Using Global Secondary Indexes in DynamoDB
Some applications might need to perform many kinds of queries, using a variety of
different attributes as query criteria. To support these requirements, you can create one or
more global secondary indexes and issue Query requests
against these indexes in Amazon DynamoDB.
Topics
Scenario: Using a Global Secondary Index
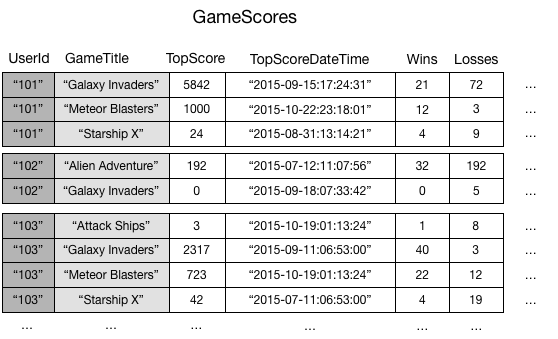
To illustrate, consider a table named GameScores that tracks users and
scores for a mobile gaming application. Each item in GameScores is
identified by a partition key (UserId) and a sort key
(GameTitle). The following diagram shows how the items in the table
would be organized. (Not all of the attributes are shown.)
Now suppose that you wanted to write a leaderboard application to display top scores
for each game. A query that specified the key attributes (UserId and
GameTitle) would be very efficient. However, if the application needed
to retrieve data from GameScores based on GameTitle only, it
would need to use a Scan operation. As more items are added to the table,
scans of all the data would become slow and inefficient. This makes it difficult to
answer questions such as the following:
-
What is the top score ever recorded for the game Meteor Blasters?
-
Which user had the highest score for Galaxy Invaders?
-
What was the highest ratio of wins vs. losses?
To speed up queries on non-key attributes, you can create a global secondary index. A global secondary index contains a selection of attributes from the base table, but they are organized by a primary key that is different from that of the table. The index key does not need to have any of the key attributes from the table. It doesn't even need to have the same key schema as a table.
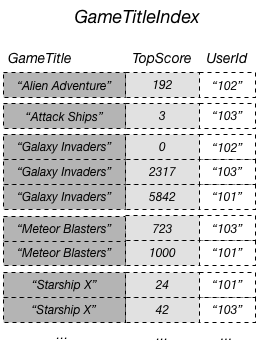
For example, you could create a global secondary index named GameTitleIndex, with a
partition key of GameTitle and a sort key of TopScore. The
base table's primary key attributes are always projected into an index, so the
UserId attribute is also present. The following diagram shows what
GameTitleIndex index would look like.
Now you can query GameTitleIndex and easily obtain the scores for Meteor
Blasters. The results are ordered by the sort key values, TopScore. If you
set the ScanIndexForward parameter to false, the results are returned in
descending order, so the highest score is returned first.
Every global secondary index must have a partition key, and can have an optional sort key. The index
key schema can be different from the base table schema. You could have a table with a
simple primary key (partition key), and create a global secondary index with a composite primary key
(partition key and sort key)—or vice versa. The index key attributes can consist
of any top-level String, Number, or Binary
attributes from the base table. Other scalar types, document types, and set types are
not allowed.
You can project other base table attributes into the index if you want. When you query
the index, DynamoDB can retrieve these projected attributes efficiently. However, global secondary index
queries cannot fetch attributes from the base table. For example, if you query
GameTitleIndex as shown in the previous diagram, the query could not
access any non-key attributes other than TopScore (although the key
attributes GameTitle and UserId would automatically be
projected).
In a DynamoDB table, each key value must be unique. However, the key values in a global secondary index do not need to be unique. To illustrate, suppose that a game named Comet Quest is especially difficult, with many new users trying but failing to get a score above zero. The following is some data that could represent this.
| UserId | GameTitle | TopScore |
|---|---|---|
| 123 | Comet Quest | 0 |
| 201 | Comet Quest | 0 |
| 301 | Comet Quest | 0 |
When this data is added to the GameScores table, DynamoDB propagates it to
GameTitleIndex. If we then query the index using Comet Quest for
GameTitle and 0 for TopScore, the following data is
returned.
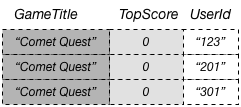
Only the items with the specified key values appear in the response. Within that set of data, the items are in no particular order.
A global secondary index only tracks data items where its key attributes actually exist. For example,
suppose that you added another new item to the GameScores table, but only
provided the required primary key attributes.
| UserId | GameTitle |
|---|---|
| 400 | Comet Quest |
Because you didn't specify the TopScore attribute, DynamoDB would not
propagate this item to GameTitleIndex. Thus, if you queried
GameScores for all the Comet Quest items, you would get the following
four items.

A similar query on GameTitleIndex would still return three items, rather
than four. This is because the item with the nonexistent TopScore is not
propagated to the index.
Attribute projections
A projection is the set of attributes that is copied from a table into a secondary index. The partition key and sort key of the table are always projected into the index; you can project other attributes to support your application's query requirements. When you query an index, Amazon DynamoDB can access any attribute in the projection as if those attributes were in a table of their own.
When you create a secondary index, you need to specify the attributes that will be projected into the index. DynamoDB provides three different options for this:
-
KEYS_ONLY – Each item in the index consists only of the table partition key and sort key values, plus the index key values. The
KEYS_ONLYoption results in the smallest possible secondary index. -
INCLUDE – In addition to the attributes described in
KEYS_ONLY, the secondary index will include other non-key attributes that you specify. -
ALL – The secondary index includes all of the attributes from the source table. Because all of the table data is duplicated in the index, an
ALLprojection results in the largest possible secondary index.
In the previous diagram, GameTitleIndex has
only one projected attribute: UserId. So while an application can
efficiently determine the UserId of the top scorers for each game using
GameTitle and TopScore in queries, it can't efficiently
determine the highest ratio of wins vs. losses for the top scorers. To do so, it would
have to perform an additional query on the base table to fetch the wins and losses for
each of the top scorers. A more efficient way to support queries on this data would be
to project these attributes from the base table into the global secondary index, as shown in this
diagram.

Because the non-key attributes Wins and Losses are projected
into the index, an application can determine the wins vs. losses ratio for any game, or
for any combination of game and user ID.
When you choose the attributes to project into a global secondary index, you must consider the tradeoff between provisioned throughput costs and storage costs:
-
If you need to access just a few attributes with the lowest possible latency, consider projecting only those attributes into a global secondary index. The smaller the index, the less that it costs to store it, and the less your write costs are.
-
If your application frequently accesses some non-key attributes, you should consider projecting those attributes into a global secondary index. The additional storage costs for the global secondary index offset the cost of performing frequent table scans.
-
If you need to access most of the non-key attributes on a frequent basis, you can project these attributes—or even the entire base table— into a global secondary index. This gives you maximum flexibility. However, your storage cost would increase, or even double.
-
If your application needs to query a table infrequently, but must perform many writes or updates against the data in the table, consider projecting
KEYS_ONLY. The global secondary index would be of minimal size, but would still be available when needed for query activity.
Multi-attribute key schema
Global Secondary Indexes support multi-attribute keys, allowing you to compose partition keys and sort keys from multiple attributes. With multi-attribute keys, you can create a partition key from up to four attributes and a sort key from up to four attributes, for a total of up to eight attributes per key schema.
Multi-attribute keys simplify your data model by eliminating the need to manually
concatenate attributes into synthetic keys. Instead of creating composite strings like
TOURNAMENT#WINTER2024#REGION#NA-EAST, you can use the natural
attributes from your domain model directly. DynamoDB handles the composite key logic
automatically, hashing multiple partition key attributes together for data distribution
and maintaining hierarchical sort order across multiple sort key attributes.
For example, consider a gaming tournament system where you want to organize matches by
tournament and region. With multi-attribute keys, you can define your partition key as
two separate attributes: tournamentId and region. Similarly,
you can define your sort key using multiple attributes like round,
bracket, and matchId to create a natural hierarchy. This
approach keeps your data typed and your code clean, without string manipulation or
parsing.
When you query a global secondary index with multi-attribute keys, you must specify all partition key
attributes using equality conditions. For sort key attributes, you can query them
left-to-right in the order they're defined in the key schema. This means you can query
the first sort key attribute alone, the first two attributes together, or all attributes
together, but you cannot skip attributes in the middle. Inequality conditions such as
>, <, BETWEEN, or
begins_with() must be the last condition in your query.
Multi-attribute keys work particularly well when creating global secondary indexes on existing tables. You can use attributes that already exist in your table without backfilling synthetic keys across your data. This makes it straightforward to add new query patterns to your application by creating indexes that reorganize your data using different attribute combinations.
Each attribute in a multi-attribute key can have its own data type: String
(S), Number (N), or Binary (B). When choosing data types,
consider that Number attributes sort numerically without requiring
zero-padding, while String attributes sort lexicographically. For example,
if you use a Number type for a score attribute, the values 5, 50, 500, and
1000 sort in natural numeric order. The same values as String type would
sort as "1000", "5", "50", "500" unless you pad them with leading zeros.
When designing multi-attribute keys, order your attributes from most general to most specific. For partition keys, combine attributes that are always queried together and that provide good data distribution. For sort keys, place frequently queried attributes first in the hierarchy to maximize query flexibility. This ordering allows you to query at any level of granularity that matches your access patterns.
See the Multi-attribute keys for implementation examples.
Reading data from a Global Secondary Index
You can retrieve items from a global secondary index using the Query and Scan
operations. The GetItem and BatchGetItem operations can't be
used on a global secondary index.
Querying a Global Secondary Index
You can use the Query operation to access one or more items in a
global secondary index. The query must specify the name of the base table and the name of the index
that you want to use, the attributes to be returned in the query results, and any
query conditions that you want to apply. DynamoDB can return the results in ascending
or descending order.
Consider the following data returned from a Query that requests
gaming data for a leaderboard application.
{ "TableName": "GameScores", "IndexName": "GameTitleIndex", "KeyConditionExpression": "GameTitle = :v_title", "ExpressionAttributeValues": { ":v_title": {"S": "Meteor Blasters"} }, "ProjectionExpression": "UserId, TopScore", "ScanIndexForward": false }
In this query:
-
DynamoDB accesses GameTitleIndex, using the GameTitle partition key to locate the index items for Meteor Blasters. All of the index items with this key are stored adjacent to each other for rapid retrieval.
-
Within this game, DynamoDB uses the index to access all of the user IDs and top scores for this game.
-
The results are returned, sorted in descending order because the
ScanIndexForwardparameter is set to false.
Scanning a Global Secondary Index
You can use the Scan operation to retrieve all of the data from a
global secondary index. You must provide the base table name and the index name in the request. With
a Scan, DynamoDB reads all of the data in the index and returns it to the
application. You can also request that only some of the data be returned, and that
the remaining data should be discarded. To do this, use the
FilterExpression parameter of the Scan operation. For
more information, see Filter expressions for scan.
Data synchronization between tables and Global Secondary Indexes
DynamoDB automatically synchronizes each global secondary index with its base table. When an application writes or deletes items in a table, any global secondary indexes on that table are updated asynchronously, using an eventually consistent model. Applications never write directly to an index. However, it is important that you understand the implications of how DynamoDB maintains these indexes.
Global secondary indexes inherit the read/write capacity mode from the base table. For more information, see Considerations when switching capacity modes in DynamoDB.
When you create a global secondary index, you specify one or more index key attributes and their data
types. This means that whenever you write an item to the base table, the data types for
those attributes must match the index key schema's data types. In the case of
GameTitleIndex, the GameTitle partition key in the index
is defined as a String data type. The TopScore sort key in the
index is of type Number. If you try to add an item to the
GameScores table and specify a different data type for either
GameTitle or TopScore, DynamoDB returns a
ValidationException because of the data type mismatch.
When you put or delete items in a table, the global secondary indexes on that table are updated in an eventually consistent fashion. Changes to the table data are propagated to the global secondary indexes within a fraction of a second, under normal conditions. However, in some unlikely failure scenarios, longer propagation delays might occur. Because of this, your applications need to anticipate and handle situations where a query on a global secondary index returns results that are not up to date.
If you write an item to a table, you don't have to specify the attributes for any
global secondary index sort key. Using GameTitleIndex as an example, you would not need to
specify a value for the TopScore attribute to write a new item to the
GameScores table. In this case, DynamoDB does not write any data to the
index for this particular item.
A table with many global secondary indexes incurs higher costs for write activity than tables with fewer indexes. For more information, see Provisioned throughput considerations for Global Secondary Indexes.
Table classes with Global Secondary Index
A global secondary index will always use the same table class as its base table. Any time a new global secondary index is added for a table, the new index will use the same table class as its base table. When a table's table class is updated, all associated global secondary indexes are updated as well.
Provisioned throughput considerations for Global Secondary Indexes
When you create a global secondary index on a provisioned mode table, you must specify read and write
capacity units for the expected workload on that index. The provisioned throughput
settings of a global secondary index are separate from those of its base table. A Query
operation on a global secondary index consumes read capacity units from the index, not the base table.
When you put, update or delete items in a table, the global secondary indexes on that
table are also updated. These index updates consume write capacity units from the index,
not from the base table.
For example, if you Query a global secondary index and exceed its provisioned read
capacity, your request will be throttled. If you perform heavy write activity on the
table, but a global secondary index on that table has insufficient write capacity, the write activity on
the table will be throttled.
Important
To avoid potential throttling, the provisioned write capacity for a global secondary index should be equal or greater than the write capacity of the base table because new updates write to both the base table and global secondary index.
To view the provisioned throughput settings for a global secondary index, use the
DescribeTable operation. Detailed information about all of the table's
global secondary indexes is returned.
Read capacity units
Global secondary indexes support eventually consistent reads, each of which consume one half of a read capacity unit. This means that a single global secondary index query can retrieve up to 2 × 4 KB = 8 KB per read capacity unit.
For global secondary index queries, DynamoDB calculates the provisioned read activity in the same way as it does for queries against tables. The only difference is that the calculation is based on the sizes of the index entries, rather than the size of the item in the base table. The number of read capacity units is the sum of all projected attribute sizes across all of the items returned. The result is then rounded up to the next 4 KB boundary. For more information about how DynamoDB calculates provisioned throughput usage, see DynamoDB provisioned capacity mode.
The maximum size of the results returned by a Query operation is
1 MB. This includes the sizes of all the attribute names and values
across all of the items returned.
For example, consider a global secondary index where each item contains 2,000 bytes of data. Now
suppose that you Query this index and that the query's
KeyConditionExpression matches eight items. The total size of the
matching items is 2,000 bytes × 8 items = 16,000 bytes. This result is then
rounded up to the nearest 4 KB boundary. Because global secondary index queries are eventually
consistent, the total cost is 0.5 × (16 KB / 4 KB), or 2 read capacity
units.
Write capacity units
When an item in a table is added, updated, or deleted, and a global secondary index is affected by this, the global secondary index consumes provisioned write capacity units for the operation. The total provisioned throughput cost for a write consists of the sum of write capacity units consumed by writing to the base table and those consumed by updating the global secondary indexes. If a write to a table does not require a global secondary index update, no write capacity is consumed from the index.
For a table write to succeed, the provisioned throughput settings for the table and all of its global secondary indexes must have enough write capacity to accommodate the write. Otherwise, the write to the table is throttled.
Important
When creating a Global Secondary Index (GSI), write operations to the base table can be throttled if the GSI activity resulting from writes to the base table exceeds the GSI's provisioned write capacity. This throttling affects all write operations, from indexing process to potentially disrupting your production workloads. For more information, see Troubleshooting throttling in Amazon DynamoDB.
The cost of writing an item to a global secondary index depends on several factors:
-
If you write a new item to the table that defines an indexed attribute, or you update an existing item to define a previously undefined indexed attribute, one write operation is required to put the item into the index.
-
If an update to the table changes the value of an indexed key attribute (from A to B), two writes are required, one to delete the previous item from the index and another write to put the new item into the index.
-
If an item was present in the index, but a write to the table caused the indexed attribute to be deleted, one write is required to delete the old item projection from the index.
-
If an item is not present in the index before or after the item is updated, there is no additional write cost for the index.
-
If an update to the table only changes the value of projected attributes in the index key schema, but does not change the value of any indexed key attribute, one write is required to update the values of the projected attributes into the index.
All of these factors assume that the size of each item in the index is less than or equal to the 1 KB item size for calculating write capacity units. Larger index entries require additional write capacity units. You can minimize your write costs by considering which attributes your queries will need to return and projecting only those attributes into the index.
Storage considerations for Global Secondary Indexes
When an application writes an item to a table, DynamoDB automatically copies the correct subset of attributes to any global secondary indexes in which those attributes should appear. Your AWS account is charged for storage of the item in the base table and also for storage of attributes in any global secondary indexes on that table.
The amount of space used by an index item is the sum of the following:
-
The size in bytes of the base table primary key (partition key and sort key)
-
The size in bytes of the index key attribute
-
The size in bytes of the projected attributes (if any)
-
100 bytes of overhead per index item
To estimate the storage requirements for a global secondary index, you can estimate the average size of an item in the index and then multiply by the number of items in the base table that have the global secondary index key attributes.
If a table contains an item where a particular attribute(s) is not defined, but that attribute is defined as an index partition key or sort key, DynamoDB doesn't write any data for that item to the index.
