First steps for modeling relational data in DynamoDB
Important
NoSQL design requires a different mindset than RDBMS design. For an RDBMS, you can create a normalized data model without thinking about access patterns. You can then extend it later when new questions and query requirements arise. By contrast, in Amazon DynamoDB, you shouldn't start designing your schema until you know the questions that it needs to answer. Understanding the business problems and the application use cases up front is absolutely essential.
To start designing a DynamoDB table that will scale efficiently, you must take several steps first to identify the access patterns that are required by the operations and business support systems (OSS/BSS) that it needs to support:
For new applications, review user stories about activities and objectives. Document the various use cases you identify, and analyze the access patterns that they require.
For existing applications, analyze query logs to find out how people are currently using the system and what the key access patterns are.
After completing this process, you should end up with a list that might look something like the following.
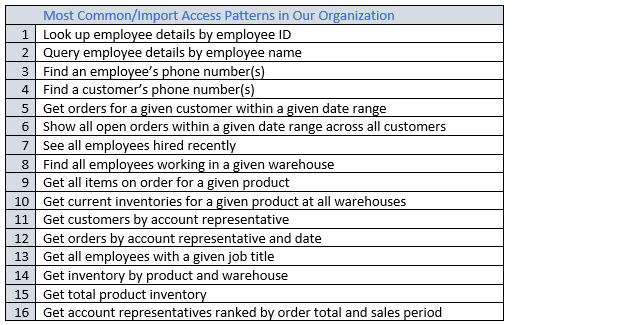
In a real application, your list might be much longer. But this collection represents the range of query pattern complexity that you might find in a production environment.
A common approach to DynamoDB schema design is to identify application layer entities and use denormalization and composite key aggregation to reduce query complexity.
In DynamoDB, this means using composite sort keys, overloaded global secondary indexes, partitioned tables/indexes, and other design patterns. You can use these elements to structure the data so that an application can retrieve whatever it needs for a given access pattern using a single query on a table or index. The primary pattern that you can use to model the normalized schema shown in Relational modeling is the adjacency list pattern. Other patterns used in this design can include global secondary index write sharding, global secondary index overloading, composite keys, and materialized aggregations.
Important
In general, you should maintain as few tables as possible in a DynamoDB application. Exceptions include cases where high-volume time series data are involved, or datasets that have very different access patterns. A single table with inverted indexes can usually enable simple queries to create and retrieve the complex hierarchical data structures required by your application.
To use NoSQL Workbench for DynamoDB to help visualize your partition key design, see Building data models with NoSQL Workbench.
