Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Journalisation du trafic IP à l'aide des journaux de flux VPC
La fonctionnalité de journaux de flux VPC vous permet de capturer des informations sur le trafic IP circulant vers et depuis les interfaces réseau dans votre VPC. Les données du journal de flux peuvent être publiées aux emplacements suivants : Amazon CloudWatch Logs, Amazon S3 ou Amazon Data Firehose. Après avoir créé un journal de flux, vous pouvez récupérer et consulter les enregistrements du journal de flux dans le groupe de journaux, le compartiment ou le flux de diffusion que vous avez configuré.
Les journaux de flux peuvent vous aider pour de nombreuses tâches, par exemple :
-
Diagnostiquer les règles de groupe de sécurité trop restrictives
-
Surveiller le trafic qui accède à votre instance
-
Déterminer la direction du trafic vers et depuis les interfaces réseau
Les données du journal de flux sont collectées en dehors du chemin d'accès de votre trafic réseau et n'affectent donc pas le débit réseau ou la latence. Vous pouvez créer ou supprimer des journaux de flux sans risque d'impact sur les performances du réseau.
Table des matières
- Principes de base des journaux de flux
- Enregistrements de journaux de flux
- Exemples d'enregistrements de journaux de flux
- Limitations des journaux de flux
- Tarification
- Utiliser des journaux de flux
- Publier les journaux de flux dans CloudWatch Logs
- Publier des journaux vers flux sur Amazon S3
- Publier des journaux de flux sur Amazon Data Firehose
- Interroger des journaux de flux à l'aide d'Amazon Athena
- Résoudre les problèmes liés aux journaux de flux de VPC
Principes de base des journaux de flux
Vous pouvez créer un journal de flux pour un VPC, un sous-réseau ou une interface réseau. Si vous créez un journal de flux pour un sous-réseau ou VPC, chaque interface réseau du sous-réseau ou du VPC est surveillée.
Les données des journaux de flux pour une interface réseau surveillée sont enregistrées sous forme d'enregistrements de journaux de flux. Il s'agit d'événements de journaux, composés de champs qui décrivent le flux de trafic. Pour plus d'informations, consultez Enregistrements de journaux de flux.
Pour créer un journal de flux, vous spécifiez :
-
La ressource pour laquelle vous souhaitez créer le journal de flux.
-
Le type de trafic à capturer (le trafic accepté, le trafic rejeté ou tout le trafic)
-
Les destinations où publier les données du journal de flux.
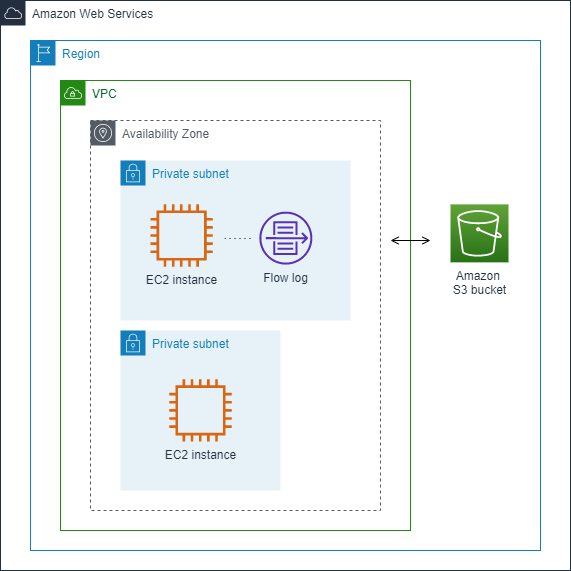
Dans l'exemple suivant, vous créez un journal de flux qui capture le trafic accepté pour l'interface réseau de l'une des instances EC2 dans un sous-réseau privé et publie les enregistrements du journal de flux dans un compartiment Amazon S3.
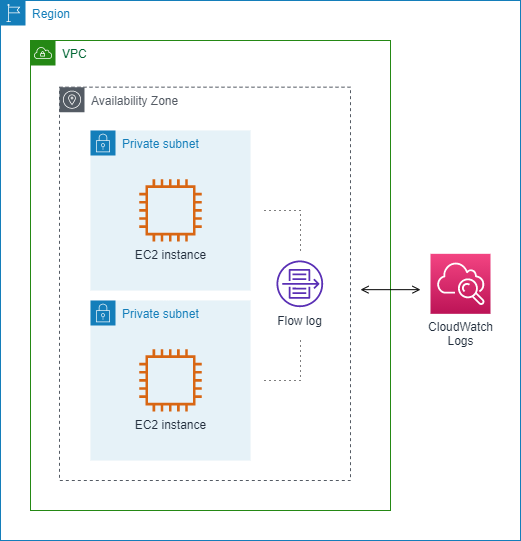
Dans l'exemple suivant, un journal de flux capture tout le trafic d'un sous-réseau et publie les enregistrements du journal de flux sur Amazon CloudWatch Logs. Le journal de flux capture le trafic pour toutes les interfaces réseau du sous-réseau.
Une fois que vous avez créé un journal de flux, plusieurs minutes peuvent s'écouler avant qu'il ne commence à collecter et à publier des données dans les destinations choisies. Les journaux de flux ne capturent pas de flux de journaux en temps réel pour vos interfaces réseau. Pour plus d’informations, consultez Créer un journal de flux.
Si vous lancez une instance dans votre sous-réseau après avoir créé un journal de flux pour votre sous-réseau ou VPC, nous créons un flux de journal (pour les CloudWatch journaux) ou un objet de fichier journal (pour Amazon S3) pour la nouvelle interface réseau dès qu'il y a du trafic réseau pour l'interface réseau.
Vous pouvez générer des journaux de flux pour les interfaces réseau créées par d'autres services AWS , par exemple :
-
Elastic Load Balancing
-
Amazon RDS
-
Amazon ElastiCache
-
Amazon Redshift
-
Amazon WorkSpaces
-
Passerelles NAT
-
Passerelles de transit
Quel que soit le type d'interface réseau, vous devez utiliser la console Amazon EC2 ou l'API Amazon EC2 afin de créer un journal de flux pour une interface réseau.
Vous pouvez appliquer des balises à vos journaux de flux. Chaque balise est constituée d'une clé et d'une valeur facultative que vous définissez. Les balises peuvent vous aider à organiser vos journaux de flux, par exemple par objectif ou par propriétaire.
Si vous n'avez plus besoin d'un journal de flux, vous pouvez le supprimer. Dans ce cas, vous désactivez le service de journaux de flux pour la ressource, de sorte qu'aucun autre enregistrement de journal de flux n'est créé ou publié. La suppression d'un journal de flux ne supprime aucune donnée existante du journal de flux. Après avoir supprimé un journal de flux, vous pouvez supprimer les données du journal de flux directement de la destination lorsque vous en avez terminé. Pour plus d’informations, consultez Supprimer un journal de flux.
Enregistrements de journaux de flux
Un enregistrement de journal de flux représente un flux de réseau dans votre VPC. Par défaut, chaque enregistrement capture un flux de trafic IP réseau (caractérisé par un 5-tuple par interface réseau) qui se produit dans un intervalle d'agrégation, également appelé fenêtre de capture.
Chaque enregistrement est une chaîne de caractères avec des champs séparés par des espaces. Un enregistrement inclut des valeurs pour les différents composants du flux IP, par exemple la source, la destination et le protocole.
Lorsque vous créez un journal de flux, vous pouvez utiliser le format par défaut pour l'enregistrement de journal de flux ou spécifier un format personnalisé.
Intervalle d'agrégation
L'intervalle d'agrégation est la période pendant laquelle un flux particulier est capturé et agrégé dans un enregistrement de journal de flux. Par défaut, l'intervalle d'agrégation maximal est de 10 minutes. Lorsque vous créez un journal de flux, vous pouvez spécifier un intervalle d'agrégation maximal d'une minute. Les journaux de flux avec un intervalle d'agrégation maximal d'une minute produisent un volume d'enregistrements de journaux de flux plus élevé que ceux avec un intervalle d'agrégation maximal de 10 minutes.
Lorsqu'une interface réseau est associée à une instance basée sur Nitro, l'intervalle d'agrégation est toujours d'une minute maximum, quel que soit celui qui a été spécifié.
Une fois les données capturées dans un intervalle d'agrégation, le traitement et la publication des données sur CloudWatch Logs ou Amazon S3 prennent plus de temps. Le service de journalisation des flux fournit généralement CloudWatch les journaux à Logs en 5 minutes environ et à Amazon S3 en 10 minutes environ. La fourniture des journaux est effectuée au mieux des possibilités disponibles. Il est donc possible que vos journaux soient retardés au-delà du délai de remise habituel.
Format par défaut
Avec le format par défaut, les enregistrements de journaux de flux incluent les champs version 2, dans l'ordre indiqué dans le tableau Champs disponibles. Vous ne pouvez pas personnaliser ou modifier le format par défaut. Pour capturer les champs supplémentaires ou un sous-ensemble de champs différent, spécifiez plutôt un format personnalisé.
Format personnalisé
Avec un format personnalisé, vous spécifiez quels champs sont inclus dans les enregistrements de journaux de flux et dans quel ordre. Cela vous permet de créer des journaux de flux qui correspondent spécifiquement à vos besoins et d'ignorer les champs qui ne sont pas pertinents. L'utilisation d'un format personnalisé peut également réduire la nécessité de faire appel à des processus distincts pour extraire des informations spécifiques des journaux de flux publiés. Vous pouvez spécifier n'importe quel nombre de champs de journal de flux disponibles, mais vous devez indiquer au moins un champ.
Champs disponibles
Le tableau suivant décrit tous les champs disponibles pour un enregistrement de journal de flux. La colonne Version indique la version des journaux de flux VPC dans laquelle le champ a été introduit. Le format par défaut inclut tous les champs version 2, dans même ordre que dans le tableau.
Lorsque vous publiez des données du journal de flux sur Amazon S3, le type de données des champs dépend du format du journal de flux. Si le format est en texte brut, tous les champs sont de type STRING. Si le format est Parquet, consultez le tableau des types de données de champ.
Si un champ ne s'applique pas à un enregistrement spécifique ou pourrait ne pas être calculé pour celui-ci, ce dernier affiche le symbole « - » pour cette entrée. Les champs de métadonnées qui ne proviennent pas directement de l'en-tête des paquets sont des approximations optimales, et leurs valeurs peuvent être manquantes ou inexactes.
| Champ | Description | Version |
|---|---|---|
|
version |
Version des journaux de flux VPC Si vous utilisez le format par défaut, la version est 2. Si vous utilisez un format personnalisé, la version est la version la plus élevée parmi les champs spécifiés. Par exemple, si vous spécifiez uniquement des champs issus de la version 2, la version est 2. Si vous spécifiez un mélange de champs des versions 2, 3 et 4, la version est 4. Type de données Parquet : INT_32 |
2 |
|
account-id |
ID de AWS compte du propriétaire de l'interface réseau source pour laquelle le trafic est enregistré. Si l'interface réseau est créée par un AWS service, par exemple lors de la création d'un point de terminaison VPC ou d'un Network Load Balancer, l'enregistrement peut s'unknownafficher pour ce champ. Type de données Parquet : CHAÎNE |
2 |
|
interface-id |
ID de l'interface réseau pour laquelle le trafic est enregistré. Type de données Parquet : CHAÎNE |
2 |
|
srcaddr |
Adresse source pour le trafic entrant, ou adresse IPv4 ou IPv6 de l'interface réseau pour le trafic sortant sur l'interface réseau. L'adresse IPv4 de l'interface réseau correspond toujours à son adresse IPv4 privée. Voir aussi pkt-srcaddr. Type de données Parquet : CHAÎNE |
2 |
|
dstaddr |
Adresse de destination pour le trafic sortant, ou adresse IPv4 ou IPv6 de l'interface réseau pour le trafic entrant sur l'interface réseau. L'adresse IPv4 de l'interface réseau correspond toujours à son adresse IPv4 privée. Voir aussi pkt-dstaddr. Type de données Parquet : CHAÎNE |
2 |
|
srcport |
Port source du trafic Type de données Parquet : INT_32 |
2 |
|
dstport |
Port de destination du trafic Type de données Parquet : INT_32 |
2 |
|
protocol |
Numéro de protocole IANA du trafic (pour plus d'informations, consultez la page Assigned Internet Protocol Numbers Type de données Parquet : INT_32 |
2 |
|
packets |
Nombre de paquets transférés pendant le flux. Type de données Parquet : INT_64 |
2 |
|
bytes |
Nombre d'octets transférés pendant le flux. Type de données Parquet : INT_64 |
2 |
|
start |
Heure, en secondes Unix, à laquelle le premier paquet du flux a été reçu dans l'intervalle d'agrégation. Jusqu'à 60 secondes peuvent s'écouler après la transmission ou la réception du paquet sur l'interface réseau. Type de données Parquet : INT_64 |
2 |
|
end |
Heure, en secondes Unix, à laquelle le dernier paquet du flux a été reçu dans l'intervalle d'agrégation. Jusqu'à 60 secondes peuvent s'écouler après la transmission ou la réception du paquet sur l'interface réseau. Type de données Parquet : INT_64 |
2 |
|
action |
Action associée au trafic :
Type de données Parquet : CHAÎNE |
2 |
|
log-status |
Statut de journalisation du journal de flux :
Type de données Parquet : CHAÎNE |
2 |
|
vpc-id |
ID du VPC qui contient l'interface réseau pour laquelle le trafic est enregistré. Type de données Parquet : CHAÎNE |
3 |
|
subnet-id |
ID du sous-réseau qui contient l'interface réseau pour laquelle le trafic est enregistré. Type de données Parquet : CHAÎNE |
3 |
|
instance-id |
ID de l'instance associée à l'interface réseau pour laquelle le trafic est enregistré, si vous êtes propriétaire de l'instance. Renvoie un symbole « - » pour une interface réseau gérée par demandeur, par exemple, l'interface réseau pour une passerelle NAT. Type de données Parquet : CHAÎNE |
3 |
|
tcp-flags |
Valeur de masque de bits pour les indicateurs TCP suivants :
-. Si aucun indicateur n'est envoyé, la valeur de l'indicateur TCP est 0.Les indicateurs TCP peuvent être interrogés pendant l'intervalle d'agrégation. Pour les connexions courtes, les indicateurs peuvent être définis sur la même ligne dans l'enregistrement de journal de flux, par exemple, 19 pour SYN-ACK et FIN, et 3 pour SYN et FIN. Pour obtenir un exemple, consultez Séquence d'indicateur TCP. Pour des informations générales sur les indicateurs TCP (comme la signification des indicateurs tels que FIN, SYN et ACK), consultez Structure d'un segment TCP Type de données Parquet : INT_32 |
3 |
|
type |
Type de trafic. Les valeurs possibles sont les suivantes : IPv4 | IPv6 | EFA. Pour plus d’informations, consultez Elastic Fabric Adapter (EFA). Type de données Parquet : CHAÎNE |
3 |
|
pkt-srcaddr |
Adresse IP source (d'origine) du trafic au niveau du paquet. Utilisez ce champ avec le champ srcaddr pour faire la distinction entre l'adresse IP d'une couche intermédiaire via laquelle les flux transitent et l'adresse IP source d'origine du trafic. Par exemple, lorsque le trafic transite par le biais d'une interface réseau pour une passerelle NAT ou lorsque l'adresse IP d'un pod dans Amazon EKS est différente de celle de l'interface réseau du nœud d'instance sur lequel le pod s'exécute (pour la communication dans un VPC). Type de données Parquet : CHAÎNE |
3 |
|
pkt-dstaddr |
Adresse IP de destination (d'origine) du trafic au niveau du paquet. Utilisez ce champ avec le champ dstaddr pour faire la distinction entre l'adresse IP d'une couche intermédiaire via laquelle le trafic transite et l'adresse IP de destination finale du trafic. Par exemple, lorsque le trafic transite par le biais d'une interface réseau pour une passerelle NAT ou lorsque l'adresse IP d'un pod dans Amazon EKS est différente de celle de l'interface réseau du nœud d'instance sur lequel le pod s'exécute (pour la communication dans un VPC). Type de données Parquet : CHAÎNE |
3 |
|
region |
Région contenant l'interface réseau pour laquelle le trafic est enregistré. Type de données Parquet : CHAÎNE |
4 |
|
az-id |
ID de la zone de disponibilité qui contient l'interface réseau pour laquelle le trafic est enregistré. Si le trafic provient d'un sous-emplacement, l'enregistrement affiche un symbole « - » pour ce champ. Type de données Parquet : CHAÎNE |
4 |
|
sublocation-type |
Type de sous-emplacement renvoyé dans le champ sublocation-id. Les valeurs possibles sont les suivantes : wavelength Type de données Parquet : CHAÎNE |
4 |
|
sublocation-id |
ID du sous-emplacement qui contient l'interface réseau pour laquelle le trafic est enregistré. Si le trafic ne provient pas d'un sous-emplacement, l'enregistrement affiche un symbole « - » pour ce champ. Type de données Parquet : CHAÎNE |
4 |
|
pkt-src-aws-service |
Le nom du sous-ensemble de plages d'adresses IP pour le pkt-srcaddr champ, si l'adresse IP source est celle d'un AWS service. Les valeurs possibles sont les suivantes : AMAZON | AMAZON_APPFLOW | AMAZON_CONNECT | API_GATEWAY | CHIME_MEETINGS | CHIME_VOICECONNECTOR | CLOUD9 | CLOUDFRONT | CODEBUILD | DYNAMODB | EBS | EC2 | EC2_INSTANCE_CONNECT | GLOBALACCELERATOR | KINESIS_VIDEO_STREAMS | ROUTE53 | ROUTE53_HEALTHCHECKS | ROUTE53_HEALTHCHECKS_PUBLISHING | ROUTE53_RESOLVER | S3 | WORKSPACES_GATEWAYS. Type de données Parquet : CHAÎNE |
5 |
|
pkt-dst-aws-service |
Le nom du sous-ensemble de plages d'adresses IP pour le pkt-dstaddr champ, si l'adresse IP de destination est celle d'un AWS service. Pour obtenir une liste des valeurs possibles, consultez le champ pkt-src-aws-service. Type de données Parquet : CHAÎNE |
5 |
|
flow-direction |
La direction du flux par rapport à l'interface où le trafic est capturé. Les valeurs possibles sont les suivantes : ingress | egress. Type de données Parquet : CHAÎNE |
5 |
|
traffic-path |
Chemin emprunté par le trafic de sortie vers la destination. Pour déterminer si le trafic est un trafic de sortie, cochez la case du champ flow-direction. Les valeurs possibles sont les suivantes. Si aucune des valeurs ne s'applique, le champ est défini sur « - ».
Type de données Parquet : INT_32 |
5 |
Limitations des journaux de flux
Lorsque vous utilisez des journaux de flux, vous devez tenir compte des limitations suivantes :
-
Vous ne pouvez pas activer les journaux de flux pour les VPC qui sont appairés à votre VPC, sauf si le VPC pair est inclus dans votre compte.
-
Une fois que vous avez créé un journal de flux, vous ne pouvez pas modifier sa configuration ou le format d'enregistrement du journal de flux. Par exemple, vous ne pouvez pas associer un rôle IAM différent au journal de flux ou ajouter/supprimer des champs dans l'enregistrement de journal de flux. En revanche, vous pouvez supprimer le journal de flux et en créer un autre avec la configuration requise.
-
Si votre interface réseau comporte plusieurs adresses IPv4 et que le trafic est envoyé vers une adresse IPv4 privée secondaire, le journal de flux affiche l'adresse IPv4 privée principale dans le champ
dstaddr. Pour capturer l'adresse IP de destination d'origine, créez un journal de flux avec le champpkt-dstaddr. -
Si le trafic est envoyé à une interface réseau et que la destination n'est pas l'une des adresses IP de l'interface réseau, le journal de flux affiche l'adresse IPv4 privée principale dans le champ
dstaddr. Pour capturer l'adresse IP de destination d'origine, créez un journal de flux avec le champpkt-dstaddr. -
Si le trafic est envoyé depuis une interface réseau et que la source n'est pas l'une des adresses IP de l'interface réseau, le journal de flux affiche l'adresse IPv4 privée principale dans le champ
srcaddr. Pour capturer l'adresse IP source d'origine, créez un journal de flux avec le champpkt-srcaddr. -
Si le trafic est envoyé depuis ou vers une interface réseau, les champs
srcaddretdstaddrdu journal de flux affichent toujours l'adresse IPv4 privée principale, quelle que soit la source ou la destination du paquet. Pour capturer la source ou la destination du paquet, créez un journal de flux avec les champspkt-srcaddretpkt-dstaddr. -
Lorsque votre interface réseau est attachée à une instance basée sur Nitro, l'intervalle d'agrégation est toujours d'une minute maximum, quel que soit l'intervalle d'agrégation maximal spécifié.
Les journaux de flux ne capturent pas tout le trafic IP. Les types de trafic suivants ne sont pas consignés :
-
Le trafic généré par des instances lorsqu'elles contactent le serveur DNS Amazon. Si vous utilisez votre propre serveur DNS, tout le trafic vers ce dernier est consigné.
-
Le trafic généré par une instance Windows pour l'activation de la licence Windows d'Amazon.
-
Le trafic depuis et vers
169.254.169.254pour les métadonnées de l'instance. -
Le trafic depuis et vers
169.254.169.123pour Amazon Time Sync Service. -
Le trafic DHCP.
-
Trafic en miroir.
-
Le trafic vers l'adresse IP réservée pour le routeur VPC par défaut.
-
Trafic entre une interface réseau de point de terminaison et une interface réseau de Network Load Balancer.
Tarification
Les frais d'ingestion et d'archivage de données pour les journaux payants s'appliquent lorsque vous publiez des journaux de flux. Pour plus d'informations sur la tarification lors de la publication de journaux vendus, ouvrez Amazon CloudWatch Pricing
Pour suivre les frais de publication des journaux de flux, vous pouvez appliquer des balises d'allocation des coûts à votre ressource de destination. Par la suite, votre rapport de répartition des AWS coûts inclut l'utilisation et les coûts agrégés par ces balises. Vous pouvez appliquer des balises associées à des catégories métier (telles que les centres de coûts, les noms d'applications ou les propriétaires) pour organiser les coûts relatifs à divers services. Pour plus d’informations, consultez les ressources suivantes :
-
Utilisation des balises de répartition des coûts dans le Guide de l'utilisateur AWS Billing .
-
Étiquetez les groupes de CloudWatch journaux dans Amazon Logs dans le guide de l'utilisateur Amazon CloudWatch Logs
-
Utilisation des balises de répartition des coûts pour les compartiments S3dans le Guide de l'utilisateur Amazon Simple Storage
-
Marquer vos flux de diffusion dans le guide du développeur Amazon Data Firehose
