Working with tables on the AWS Glue console
A table in the AWS Glue Data Catalog is the metadata definition that represents the data in a data store. You create tables when you run a crawler, or you can create a table manually in the AWS Glue console. The Tables list in the AWS Glue console displays values of your table's metadata. You use table definitions to specify sources and targets when you create ETL (extract, transform, and load) jobs.
Note
With recent changes to the AWS management console, you may need to modify your existing IAM roles to have the SearchTables permission. For new role creation, the SearchTables API permission has already been added as default.
To get started, sign in to the AWS Management Console and open the AWS Glue console at https://console.aws.amazon.com/glue/
Adding tables on the console
To use a crawler to add tables, choose Add tables, Add tables using a crawler. Then follow the instructions in the Add crawler wizard. When the crawler runs, tables are added to the AWS Glue Data Catalog. For more information, see Defining crawlers in AWS Glue.
If you know the attributes that are required to create an Amazon Simple Storage Service (Amazon S3) table definition in your Data Catalog, you can create it with the table wizard. Choose Add tables, Add table manually, and follow the instructions in the Add table wizard.
When adding a table manually through the console, consider the following:
-
If you plan to access the table from Amazon Athena, then provide a name with only alphanumeric and underscore characters. For more information, see Athena names.
-
The location of your source data must be an Amazon S3 path.
-
The data format of the data must match one of the listed formats in the wizard. The corresponding classification, SerDe, and other table properties are automatically populated based on the format chosen. You can define tables with the following formats:
- Avro
-
Apache Avro JSON binary format.
- CSV
-
Character separated values. You also specify the delimiter of either comma, pipe, semicolon, tab, or Ctrl-A.
- JSON
-
JavaScript Object Notation.
- XML
-
Extensible Markup Language format. Specify the XML tag that defines a row in the data. Columns are defined within row tags.
- Parquet
-
Apache Parquet columnar storage.
- ORC
-
Optimized Row Columnar (ORC) file format. A format designed to efficiently store Hive data.
-
You can define a partition key for the table.
-
Currently, partitioned tables that you create with the console cannot be used in ETL jobs.
Table attributes
The following are some important attributes of your table:
- Name
-
The name is determined when the table is created, and you can't change it. You refer to a table name in many AWS Glue operations.
- Database
-
The container object where your table resides. This object contains an organization of your tables that exists within the AWS Glue Data Catalog and might differ from an organization in your data store. When you delete a database, all tables contained in the database are also deleted from the Data Catalog.
- Description
-
The description of the table. You can write a description to help you understand the contents of the table.
- Table format
-
Specify creating a standard AWS Glue table, or a table in Apache Iceberg format.
- Enable compaction
-
Choose Enable compaction to compact small Amazon S3 objects in the table into larger objects.
- IAM role
To run compaction, the service assumes an IAM role on your behalf. You can choose an IAM role using the drop-down. Ensure that the role has the permissions required to enable compaction.
To learn more about the required permissions for the IAM role, see Table optimization prerequisites .
- Location
-
The pointer to the location of the data in a data store that this table definition represents.
- Classification
-
A categorization value provided when the table was created. Typically, this is written when a crawler runs and specifies the format of the source data.
- Last updated
-
The time and date (UTC) that this table was updated in the Data Catalog.
- Date added
-
The time and date (UTC) that this table was added to the Data Catalog.
- Deprecated
-
If AWS Glue discovers that a table in the Data Catalog no longer exists in its original data store, it marks the table as deprecated in the data catalog. If you run a job that references a deprecated table, the job might fail. Edit jobs that reference deprecated tables to remove them as sources and targets. We recommend that you delete deprecated tables when they are no longer needed.
- Connection
-
If AWS Glue requires a connection to your data store, the name of the connection is associated with the table.
Viewing and editing table details
To see the details of an existing table, choose the table name in the list, and then choose Action, View details.
The table details include properties of your table and its schema. This view displays the schema of the table, including column names in the order defined for the table, data types, and key columns for partitions. If a column is a complex type, you can choose View properties to display details of the structure of that field, as shown in the following example:
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
For more information about the properties of a table, such as StorageDescriptor, see
StorageDescriptor structure.
To change the schema of a table, choose Edit schema to add and remove columns, change column names, and change data types.
To compare different versions of a table, including its schema, choose Compare versions to see a side-by-side comparison of two versions of the schema for a table. For more information, see Compare table schema versions .
To display the files that make up an Amazon S3 partition, choose View partition. For Amazon S3 tables, the Key column displays the partition keys that are used to partition the table in the source data store. Partitioning is a way to divide a table into related parts based on the values of a key column, such as date, location, or department. For more information about partitions, search the internet for information about "hive partitioning."
Note
To get step-by-step guidance for viewing the details of a table, see the Explore table tutorial in the console.
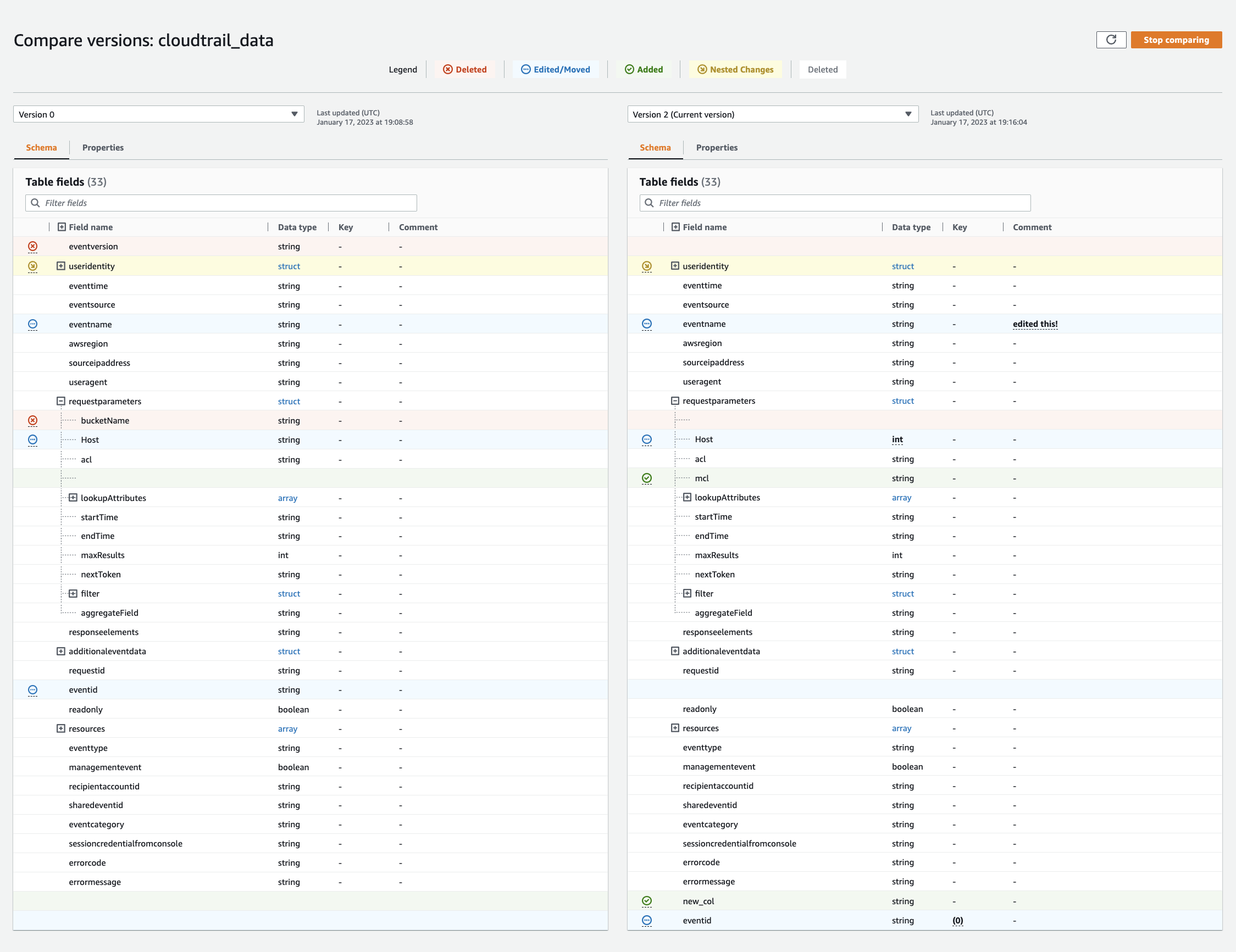
Compare table schema versions
When you compare two versions of table schemas, you can compare nested row changes by expanding and collapsing nested rows, compare schemas of two versions side-by-side, and view table properties side-by-side.
To compare versions
-
From the AWS Glue console, choose Tables, then Actions and choose Compare versions.
-
Choose a version to compare by choosing the version drop-down menu. When comparing schemas, the Schema tab is highlighted in orange.
-
When you compare tables between two versions, the table schemas are presented to you on the left and right side of the screen. This enables you to determine changes visually by comparing the Column name, data type, key, and comment fields side-by-side. When there is a change, a colored icon displays the type of change that was made.
-
Deleted – displayed by a red icon indicates where the column was removed from a previous version of the table schema.
-
Edited or Moved – displayed by a blue icon indicates where the column was modified or moved in a newer version of the table schema.
-
Added – displayed by a green icon indicates where the column was added to a newer version of the table schema.
-
Nested changes – displayed by a yellow icon indicates where the nested column contains changes. Choose the column to expand and view the columns that have either been deleted, edited, moved, or added.
-
-
Use the filter fields search bar to display fields based on the characters you enter here. If you enter a column name in either table version, the filtered fields are displayed in both table versions to show you where the changes have occurred.
-
To compare properties, choose the Properties tab.
-
To stop comparing versions, choose Stop comparing to return to the list of tables.
Optimizing Iceberg tables
The Amazon S3 data lakes using open table formats such as Apache Iceberg store the data as Amazon S3 objects. Having thousands of small Amazon S3 objects in a data lake table increases metadata overhead on Iceberg tables and affects the read performance. For better read performance by AWS analytics services such as Amazon Athena and Amazon EMR, and AWS Glue ETL jobs, AWS Glue Data Catalog provides managed compaction (a process that compacts small Amazon S3 objects into larger objects) for Iceberg tables in Data Catalog. You can use AWS Glue console, Lake Formation console, AWS CLI, or AWS API to enable or disable compaction for individual Iceberg tables that are in the Data Catalog.
The table optimizer constantly monitors table partitions and kicks off the compaction process when the threshold is exceeded for the number of files and file sizes. In the Data Catalog, the default threshold value to initiate compaction is set to 384 MB whereas in the Iceberg library the threshold for compaction is ~75% of the target file size. Data Catalog performs compaction without interfering with concurrent queries. Data Catalog supports data compaction only for tables in the Parquet format.
Topics
Table optimization prerequisites
The table optimizer assumes the permissions of the AWS Identity and Access Management (IAM) role that you specify when you enable compaction for a table. The IAM role must have the permissions to read data and update metadata in the Data Catalog. You can create an IAM role and attach the following inline policies:
-
Add the following inline policy that grants Amazon S3 read/write permissions on the location for data that is not registered with Lake Formation. This policy also includes permissions to update the table in the Data Catalog, and to permit AWS Glue to add logs in Amazon CloudWatch logs and publish metrics. For source data in Amazon S3 that isn't registered with Lake Formation, access is determined by IAM permissions policies for Amazon S3 and AWS Glue actions.
In the following inline policies, replace
bucket-namewith your Amazon S3 bucket name,aws-account-idandregionwith a valid AWS account number and Region of the Data Catalog,database_namewith the name of your database, andtable_namewith the name of the table.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::<bucket-name>/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<bucket-name>" ] }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<database-name>/<table-name>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] } -
Use the following policy to enable compaction for data registered with Lake Formation.
For more information on registering an Amazon S3 bucket with Lake Formation, see Requirements for roles used to register locations.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "lakeformation:GetDataAccess" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "glue:UpdateTable", "glue:GetTable" ], "Resource": [ "arn:aws:glue:<region>:<aws-account-id>:table/<databaseName>/<tableName>", "arn:aws:glue:<region>:<aws-account-id>:database/<database-name>", "arn:aws:glue:<region>:<aws-account-id>:catalog" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:<region>:<aws-account-id>:log-group:/aws-glue/iceberg-compaction/logs:*" } ] }If the compaction role doesn't have
IAM_ALLOWED_PRINCIPALSgroup permissions granted on the table, the role requires Lake Formation ALTER, DESCRIBE, INSERT and DELETE permissions on the table. -
(Optional) To compact Iceberg tables with data in Amazon S3 buckets encrypted using Server-side encryption, the compaction role requires permissions to decrypt Amazon S3 objects and generate a new data key to write objects to the encrypted buckets. Add the following policy to the desired AWS KMS key. We support only bucket-level encryption.
{ "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id>:role/<compaction-role-name>" }, "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": "*" } -
(Optional) For data location registered with Lake Formation, the role used to register the location requires permissions to decrypt Amazon S3 objects and generate a new data key to write objects to the encrypted buckets. For more information, see Registering an encrypted Amazon S3 location.
-
(Optional)If the AWS KMS key is stored in a different AWS account, you need to include the following permissions to the compaction role.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kms:Decrypt", "kms:GenerateDataKey" ], "Resource": ["arn:aws:kms:<REGION>:<KEY_OWNER_ACCOUNT_ID>:key/<KEY_ID>"] } ] } -
The role you use to run compaction must have the
iam:PassRolepermission on the role.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:PassRole" ], "Resource": [ "arn:aws:iam::<account-id>:role/<compaction-role-name>" ] } ] } -
Add the following trust policy to the role for AWS Glue service to assume the IAM role to run the compaction process.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
Enabling compaction
You can use AWS Glue console, Lake Formation console, AWS CLI, or AWS API to enable compaction for your Apache Iceberg tables in the Data Catalog. For new tables, you can choose Apache Iceberg as table format and enable compaction when you create the table. Compaction is disabled by default for new tables.
After you enable compaction, Table optimization tab shows the following compaction details (after approximately 15-20 minutes):
-
Start time - The time at which the compaction process started within Lake Formation. The value is a timestamp in UTC time.
-
End time - The time at which the compaction process ended in Lake Formation. The value is a timestamp in UTC time.
-
Status - The status of the compaction run. Values are success or fail.
-
Files compacted - Total number of files compacted.
-
Bytes compacted - Total number of bytes compacted.
Disabling compaction
You can disable automatic compaction for a particular Apache Iceberg table using AWS Glue console or AWS CLI.
Viewing compaction details
You can view compaction status for Apache Iceberg using the AWS Glue console, AWS CLI, or using AWS API operations.
Viewing Amazon CloudWatch metrics
After running the compaction successfully, the service creates Amazon CloudWatch metrics on the compaction job performance. You can go to the CloudWatch console and choose Metrics, All metrics. You can to filter metrics by the specific name space (for example AWS Glue), table name, or database name.
For more information, see View available metrics in the Amazon CloudWatch User Guide.
-
Number of bytes compacted
-
Number of files compacted
-
Number of DPU allocated to jobs
-
Duration of job (Hours)
Deleting an optimizer
You can delete an optimizer and associated metadata for the table using AWS CLI or AWS API operation.
Run the following AWS CLI command to delete compaction history for a table.
aws glue delete-table-optimizer \ --catalog-id123456789012\ --database-nameiceberg_db\ --table-nameiceberg_table\ --type compaction
Use DeleteTableOptimizer operation to delete an optimizer for a table.
Considerations and limitations
Data compaction supports:
Data types: Boolean, Integer, Long, Float, Double, String, Decimal, Date, Time, Timestamp, String, UUID, Binary
Compression: zstd, gzip, snappy, uncompressed
-
Encryption: Data compaction only supports default Amazon S3 encryption (SSE-S3) and server-side KMS encryption (SSE-KMS).
-
Bin pack compaction
Schema evolution
Tables with target file size (write.target-file-size-bytes property in iceberg configuration) within the inclusive range 128MB to 512 MB.
Regions
Asia Pacific (Tokyo)
Asia Pacific (Seoul)
Asia Pacific (Mumbai)
Europe (Ireland)
Europe (Frankfurt)
US East (N. Virginia)
US East (Ohio)
US West (N. California)
-
You can run compaction from the account where Data Catalog resides when the Amazon S3 bucket that stores the underlying data is in another account. To do this, the compaction role requires access to the Amazon S3 bucket.
Data compaction currently doesn’t support:
Data types: Fixed
Compression: brotli, lz4
Compaction of files while the partition spec evolves.
Regular sorting or z-order sorting
Merge or delete files: The compaction process skips data files that have delete files associated with them.
-
Compaction on cross-account tables: You can't run compaction on cross-account tables.
-
Compaction on cross-Region tables: You can't run compaction on cross-Region tables.
Enabling compaction on resource links
VPC endpoints for Amazon S3 buckets
