翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon によるモニタリング CloudWatch
Amazon DynamoDB をモニタリングできます。これにより CloudWatch、DynamoDB から未加工のデータを収集して処理し、読み取り可能でほぼリアルタイムのメトリックスに変換できます。これらの統計は一定期間保持されるため、履歴情報にアクセスしてウェブアプリケーションまたはサービスの動作をより的確に把握することができます。デフォルトでは、DynamoDB CloudWatch メトリックスデータはに自動的に送信されます。詳細については、「Amazon CloudWatch とは」を参照してください。 および Amazon CloudWatch ユーザーガイドの「メトリックスの保持」を参照してください。
トピック
DynamoDB メトリクスの使用方法
DynamoDB によってレポートされるメトリクスが提供する情報は、さまざまな方法で分析できます。以下のリストは、メトリクスの一般的な利用方法をいくつか示しています。ここで紹介するのは開始するための提案事項です。すべてを網羅しているわけではありません。
|
目的 |
関連するメトリクス |
|---|---|
How can I monitor the rate of TTL deletions on my
table?
|
指定した期間 |
How can I determine how much of my provisioned throughput is
being used?
|
指定した期間 |
How can I determine which requests exceed the provisioned
throughput quotas of a table?
|
リクエスト内で任意のイベントがプロビジョニングされたスループットクォータを超過した場合、 |
How can I determine if any system errors occurred?
|
注記項目の操作中に内部サーバーエラーが発生することがあります。これはテーブルの存続期間中に発生すると予想されます。失敗したリクエストは速やかに再試行できます。 |
DynamoDB レスポンスタイムの理解と分析
レイテンシーを分析するときは、一般的に平均値を確認するのが最善です。時折レイテンシーが急上昇しても問題ありません。ただし、平均レイテンシーが高い場合は、根本的な問題が原因である可能性があります。
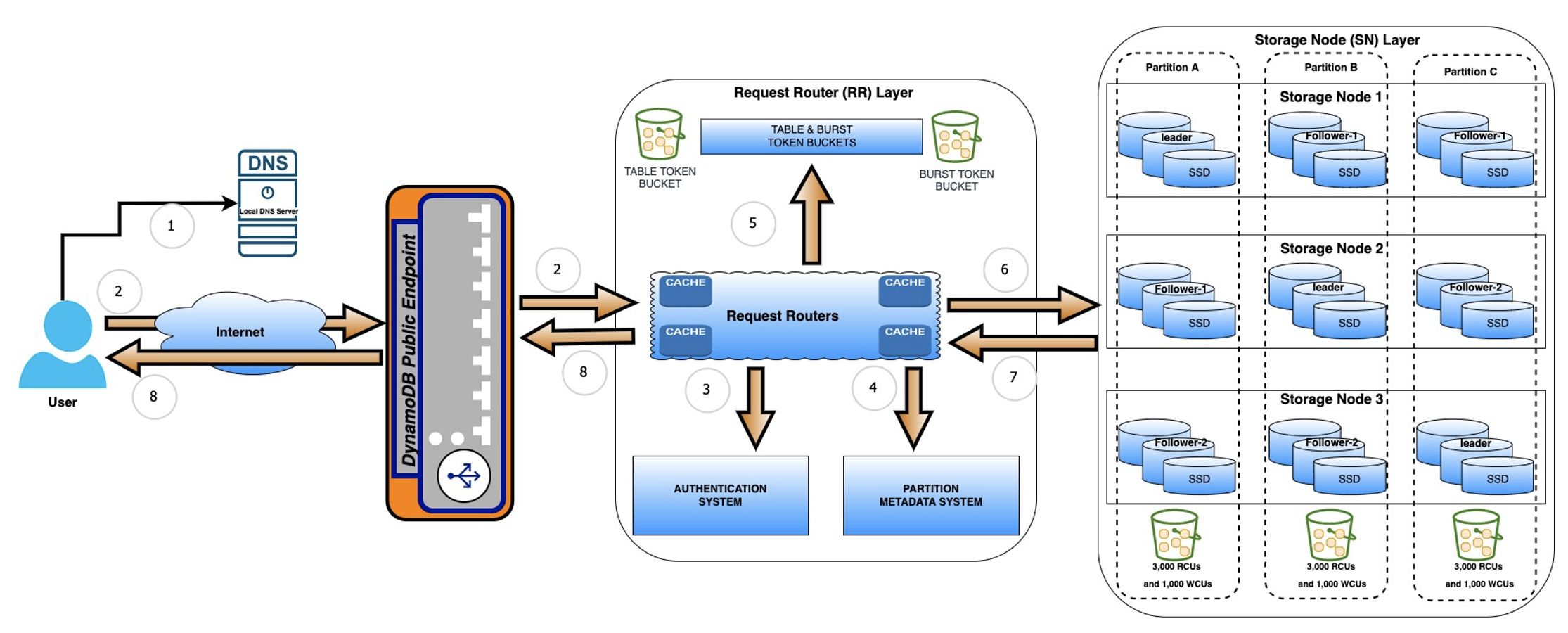
レイテンシーには、API レイテンシーとサービス側のレイテンシーの 2 つのカテゴリがあります。DynamoDB の API レイテンシーは、以下のプロセスのステップ 1~11 で測定されます。サービス側のレイテンシーは、API がリクエストルーターに到達した瞬間 (ステップ 4) から、RR が結果をアプリケーションユーザーに送り返す時間 (ステップ 11) まで測定されます。Amazon CloudWatch メトリックスを使用してサービス側のレイテンシーを分析できますSuccessfulRequestLatency。
アプリケーションが DynamoDB テーブルに対して GetItem オペレーションを発行するなど、DynamoDB に対して DynamoDB API コールを実行するときは、次のステップが実行されます。
アプリケーションは、ローカル DNS サーバーを使用して DynamoDB パブリックエンドポイントを解決します。
アプリケーションは、ステップ 1 で解決した IP アドレスに接続し、API コールを実行します。
DynamoDB パブリックエンドポイントはリクエストを受け取り、リクエストルーター (RR) と呼ばれるコンポーネントに転送します。
API リクエストがリクエストルータ (RR) に到達すると、RR は API コールの認証と承認を行います。また、RR はこの段階でスロットリングチェックも行います。
すべてのチェックが完了すると、Request Router (RR) は API リクエストから取得したパーティションキー値のハッシュを作成します。ハッシュ値に基づいて、Request Router (RR) はパーティション情報 (ストレージノード) の詳細を検索します。
ストレージノードは、顧客テーブルデータが保存されているサーバーを表します。1 つのパーティション (プライマリキーまたはパーティションキーと混同しないでください) は、3 つのストレージノードのセットで構成されます。これら 3 つのストレージノードのうち、1 つのノードがそのパーティションのリーダーとして機能し、残りの 2 つのノードがフォロワーとして機能します。
API コールが書き込みリクエストであるか、強力な整合性のある読み込みリクエストである場合、Request Routers (RR) はそのパーティションのリーダーノードを見つけ、API リクエストをその特定のノードに転送します。結果整合性のある読み込みリクエストが発生した場合、Request Routers (RR) はリクエストをそのパーティションのリーダーノードまたはいずれかのフォロワーノードにランダムに転送します。
通常の状況では、リクエストルーターは最初にストレージノードへの到達を試みます。この試みが失敗すると、RR はストレージノードに到達するために複数回再試行します。ストレージノードに接続している間、RR は常に既存の試行に十分な時間をかけてから、別の SN への接続を試みます。これは内部マイクロサービスの再試行であり、設定可能な SDK の再試行ではありません。
この段階で API リクエストはストレージノード (SN) レイヤーに到達します。SN はその処理を開始し、API コールに応じてデータの読み取りまたは書き込みを行います。
API リクエストが正常に処理されると、ストレージノード (SN) はリクエストの発信元である RR に結果またはレスポンスコードを返します。
最後に、リクエストルーターは結果をカスタマーアプリケーションに転送します。
注記
GetItemやPutItemなど、ほとんどのアトミックオペレーションでは、1 桁ミリ秒単位の平均レイテンシーが期待できます。QueryやScanなどの非アトミックオペレーションのレイテンシーは、結果セットのサイズや、クエリ条件とフィルターの複雑さなど、多くの要因によって変わります。DynamoDB は、アプリケーションが DynamoDB パブリックエンドポイントに接続するのにかかる時間や、アプリケーションがパブリックエンドポイントから結果をダウンロードするのにかかる時間を測定しません。
