Amazon S3 の HBase (Amazon S3 ストレージモード)
Amazon EMR バージョン 5.2.0 以降で HBase を実行する場合は、Amazon S3 で HBase を有効にすることで、以下の利点を得られます。
HBase ルートディレクトリが、HBase ストアファイルおよびテーブルメタデータも含めて、Amazon S3 に保存されます。このデータはクラスター外で永続的で、Amazon EC2 アベイラビリティーゾーン間で使用することができ、スナップショットやそのほかの方法を使用して復元する必要はありません。
Amazon S3 に格納したファイルを使用して、HDFS の 3 倍のレプリケーションで、データ要件ではなくコンピューティング要件に合わせて Amazon EMR クラスターのサイズを決定できます。
Amazon EMR バージョン 5.7.0 以降では、リードレプリカクラスターを設定して、データの読み取り専用コピーを Amazon S3 に保持できます。複数の読み取りオペレーションを同時に実行する場合や、プライマリクラスターが使用不能になった場合に、リードレプリカクラスターのデータを利用できます。
Amazon EMR バージョン 6.2.0 以降では、永続的 HFile トラッキングは
hbase:storefileと呼ばれる HBase システムテーブルを使用し、読み取りオペレーションに使用される HFile パスを直接追跡します。この機能はデフォルトで有効になっており、手動マイグレーションを実行する必要はありません。
次の図は Amazon S3 の HBase に関連する HBase コンポーネントを示しています。
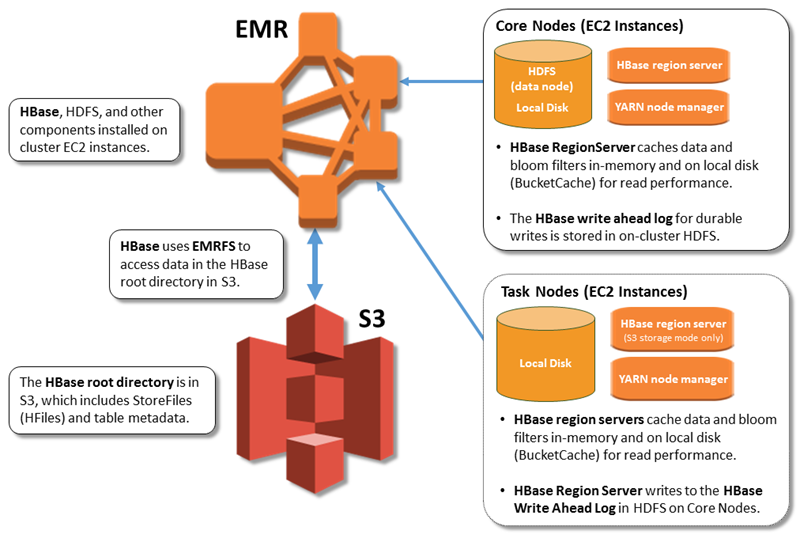
Amazon S3 での HBase の有効化
Amazon EMR コンソール、AWS CLI、または Amazon EMR API を使用して、Amazon S3 で HBase を有効にすることができます。この設定は、クラスター作成時のオプションです。コンソールを使用する場合は、[Advanced options (詳細オプション)] を使用して設定を選択します。AWS CLI を使用する場合は、--configurations オプションを使用して JSON 設定オブジェクトを提供します。設定オブジェクトのプロパティは Amazon S3 内のストレージモードとルートディレクトリの場所を指定します。Amazon S3 の場所として Amazon EMR クラスターと同じリージョン内の場所を指定する必要があります。一度に 1 つのアクティブなクラスターのみが Amazon S3 の同じ HBase ルートディレクトリを使用できます。コンソールの手順および AWS CLI を使用したクラスター作成の詳細については、「HBase を含むクラスターの作成」を参照してください。設定オブジェクトの例は、次の JSON スニペットに示します。
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://my-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3" } }
注記
Amazon S3 バケットを HBase 用の rootdir として使用する場合、Amazon S3 URI の末尾にスラッシュを追加する必要があります。例えば、問題を回避するために、"hbase.rootdir: s3://my-bucket" ではなく、"hbase.rootdir: s3://my-bucket/" を使用する必要があります。
リードレプリカクラスターの使用
Amazon S3 の HBase を使用してプライマリクラスターを設定すると、プライマリクラスターと同じデータへの読み取り専用アクセスを提供するリードレプリカクラスターを作成して設定できます。これは、クエリデータに同時にアクセスする場合や、プライマリクラスターの使用不能時にアクセスを絶やさない場合に便利です。リードレプリカ機能は Amazon EMR バージョン 5.7.0 以降で使用できます。
プライマリクラスターとリードレプリカクラスターは 1 つの重要な点を除いて設定方法が同じです。どちらも同じ hbase.rootdir の場所を参照します。ただし、リードレプリカクラスターの hbase 分類には "hbase.emr.readreplica.enabled":"true" プロパティが含まれます。
たとえば、このトピックで以前に示したプライマリクラスターの JSON 分類の場合、リードレプリカクラスターの設定は次のとおりです。
{ "Classification": "hbase-site", "Properties": { "hbase.rootdir": "s3://my-bucket/my-hbase-rootdir"} }, { "Classification": "hbase", "Properties": { "hbase.emr.storageMode":"s3", "hbase.emr.readreplica.enabled":"true" } }
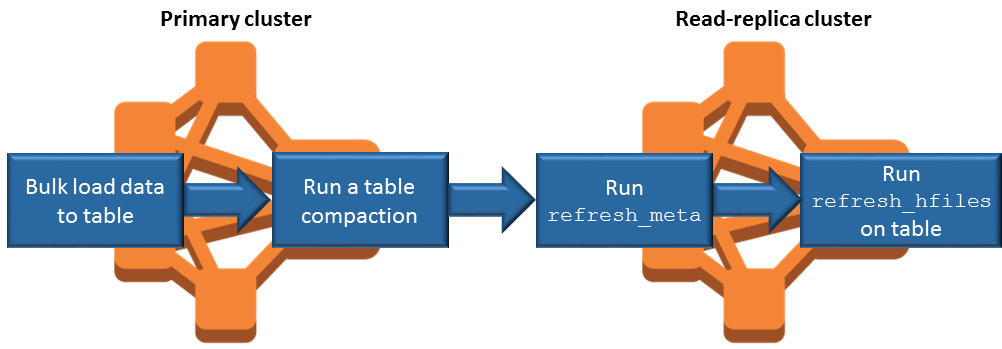
データの追加に伴うリードレプリカの同期化
リードレプリカは、プライマリクラスターが Amazon S3 に書き込む HBase StoreFile とメタデータを使用するため、Amazon S3 データストアと同期し、それより最新にはなりません。データを書き込むまでにプライマリクラスターとリードレプリカの間に生じる時間差を最小化するには、以下のガイダンスを参考にしてください。
可能な限り、プライマリクラスターのデータを一括ロードします。詳細については、Apache HBase ドキュメントの「一括ロード
」を参照してください。 ストアファイルを Amazon S3 に書き込むフラッシュは、データの追加後、できるだけ早急に発生する必要があります。時間差が最小になるように手動でフラッシュするか、フラッシュ設定を調整します。
圧縮が自動実行される場合、圧縮がトリガーされるときの不整合を避けるために手動圧縮を実行します。
リードレプリカクラスターで、メタデータの変更 (HBase リージョンの分割、圧縮の発生、テーブルの追加や削除など) があった場合、
refresh_metaコマンドを実行します。リードレプリカクラスターで、レコードがテーブルに追加されるかテーブル内で変更された場合、
refresh_hfilesコマンドを実行します。
永続的 HFile トラッキング
永続的 HFile トラッキングでは、hbase:storefile と呼ばれる HBase システムテーブルを使用し、読み取りオペレーションに使用される HFile パスを直接追跡します。HBase に追加のデータが追加されると、新しい HFile パスがテーブルに追加されます。これにより、重要な書き込みパス HBase オペレーションのコミットメカニズムとして名前変更オペレーションが削除され、ファイルシステムディレクトリの一覧ではなく、hbase:storefile システムテーブルから読み取ることで HBase リージョンを開くときに復旧時間が改善されます。この機能は Amazon EMR バージョン 6.2.0 以降ではデフォルトで有効になっており、手動での移行手順は必要ありません。
注記
HBase ストアファイルシステムテーブルを使用した永続的な HFile トラッキングは、HBase リージョンのレプリケーション機能をサポートしていません。HBase リージョンレプリケーションの詳細については、「Timeline-consistent high available reads
永続的 HFile トラッキングの無効化
永続的 HFile トラッキングは、EMR リリース 6.2.0 以降でデフォルトで有効になっています。永続的 HFile トラッキングを無効にするには、クラスターの起動時に次の設定オーバーライドを指定します。
{ "Classification": "hbase-site", "Properties": { "hbase.storefile.tracking.persist.enabled":"false", "hbase.hstore.engine.class":"org.apache.hadoop.hbase.regionserver.DefaultStoreEngine" } }
注記
Amazon EMR クラスターを再設定するときは、すべてのインスタンスグループを更新する必要があります。
ストアファイルテーブルの手動同期
新しい HFiles が作成されると、ストアファイルテーブルは最新の状態に保たれます。ただし、何らかの理由でストアファイルテーブルがデータファイルと同期しなくなった場合は、次のコマンドを使用して手動でデータを同期できます。
オンラインリージョンでストアファイルテーブルを同期する:
hbase org.apache.hadoop.hbase.client.example.RefreshHFilesClient <table>
オフラインリージョンでストアファイルテーブルを同期する:
ストアファイルテーブル znode を削除します。
echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [<tableName>, hbase:namespace] # The TableName exists in the list echo "delete /hbase/storefile/loaded/<tableName>" | sudo -u hbase hbase zkcli # Delete the Table ZNode echo "ls /hbase/storefile/loaded" | sudo -u hbase hbase zkcli [hbase:namespace]リージョンを割り当てます ('hbase shell' で実行します)。
hbase cli> assign '<region name>'割り当てが失敗した場合。
hbase cli> disable '<table name>' hbase cli> enable '<table name>'
ストアファイルテーブルのスケーリング
ストアファイルテーブルは、デフォルトでは 4 つのリージョンに分割されます。ストアファイルテーブルの書き込み負荷が大きい場合は、テーブルを手動で分割できます。
特定のホットリージョンを分割するには、次のコマンドを使用します ('hbase shell' で実行します)。
hbase cli> split '<region name>'
テーブルを分割するには、次のコマンドを使用します ('hbase shell' で実行します)。
hbase cli> split 'hbase:storefile'
運用上の考慮事項
HBase リージョンサーバーは、BlockCache を使用してデータの読み取りをメモリに保存し、BucketCache を使用してデータの読み取りをローカルディスクに保存します。また、リージョンサーバーは、MemStore を使用してデータの書き込みをメモリ内に保存し、Amazon S3 の HBase StoreFile にデータが書き込まれる前に、先書きログを使用してデータの書き込みを HDFS に保存します。クラスターの読み込みパフォーマンスは、レコードがどのくらいの頻度でインメモリキャッシュまたはオンディスクキャッシュから取得できるかに関連しています。キャッシュミスが発生すると、レコードは Amazon S3, の StoreFile から読み取られるため、HDFS からの読み取りと比べてレイテンシーと標準偏差が大幅に高くなります。さらに、Amazon S3 の最大要求率は、ローカルキャッシュから受理できるものよりも低くなるため、データのキャッシュは読み取り過多のワークロードにとって重要である場合があります。Amazon S3 のパフォーマンスの詳細については、「Amazon Simple Storage Service ユーザーガイド」の「パフォーマンスの最適化」を参照してください。
パフォーマンスを向上させるには、EC2 インスタンスストレージに可能な限りデータセットをキャッシュすることをお勧めします。BucketCache は、リージョンサーバーの EC2 インスタンスストレージを使用するため、必要なキャッシュのサイズに対応するために充分なインスタンスストアを備えた EC2 インスタンスタイプを選択し、Amazon EBS ストレージを追加できます。hbase.bucketcache.size プロパティを使用して、アタッチされたインスタンスストアおよび EBS ボリュームの BucketCache のサイズを増やすことができます。デフォルトの設定は 8,192 MB です。
書き込みでは、マイナーおよびメジャーな圧縮時の MemStore のフラッシュ頻度および StoreFile 数が、リージョンサーバーの応答時間に大きく影響する場合があります。パフォーマンスを最適化するには、MemStore フラッシュと HRegion ブロックを乗じたサイズを増やすことを検討します。これにより、メジャーな圧縮間の経過時間が長くなります。ただし、リードレプリカを使用する場合は、整合性の遅延が増大します。場合によっては、ファイルブロックサイズを増やして (ただし 5 GB 未満)、EMRFS で Amazon S3 マルチパートアップロード機能をトリガーすることで、パフォーマンスを向上できる場合があります。Amazon EMR のブロックサイズのデフォルトは 128 MB です。詳細については、「HDFS 構成」を参照してください。フラッシュと圧縮に関するパフォーマンスのベンチマークで 1 GB のブロックサイズを超えているお客様はほとんどいません。また、圧縮する StoreFile の数が少ないほど、HBase 圧縮およびリージョンサーバーのパフォーマンスが最適化されます。
大きなディレクトリの名前を変更する必要があるため、Amazon S3 でのテーブルの削除に長い時間がかかる場合があります。テーブルを削除する代わりに無効化することを検討してください。
古い WAL ファイルとストアファイルをクリーンアップする HBase クリーナープロセスがあります。Amazon EMR リリースバージョン 5.17.0 以降では、クリーナーがグローバルに有効になっており、次の設定プロパティをクリーナーの動作の制御に使用できます。
| 設定プロパティ | デフォルト値 | Description |
|---|---|---|
|
|
1 |
期限が切れた大規模な HFiles をクリーンアップするために割り当てられたスレッドの数。 |
|
|
1 |
期限が切れた小規模な HFiles をクリーンアップするために割り当てられたスレッドの数。 |
|
|
すべての使用可能なコアの 4 分の 1 に設定します。 |
oldWALs ディレクトリをスキャンするスレッドの数。 |
|
|
2 |
oldWALs ディレクトリの WALs をクリーンアップするスレッドの数。 |
Amazon EMR 5.17.0 以前では、高負荷のワークロードを実行しているときにクリーナーオペレーションがクエリパフォーマンスに影響する可能性があるため、ピークを過ぎた時間帯だけクリーナーを有効にすることをお勧めします。クリーナーには、次の HBase シェルコマンドがあります。
cleaner_chore_enabledクリーナーが有効かどうかのクエリ。cleaner_chore_run手動でクリーナーを実行してファイルを削除します。cleaner_chore_switchクリーナーを有効、または無効にし、クリーナーの以前の状態に返します。たとえば、cleaner_chore_switch trueはクリーナーを有効にします。
Amazon S3 の HBase のパフォーマンスをチューニングするプロパティ
Amazon S3 の HBase を使用するときに、以下のパラメータを調整してワークロードのパフォーマンスをチューニングできます。
| 設定プロパティ | デフォルト値 | 説明 |
|---|---|---|
|
|
8,192 |
ディスク容量 (MB)、リージョンサーバー Amazon EC2 インスタンスストアおよび BucketCache ストレージの EBS ボリュームにリザーブ。設定は、すべてのリージョンサーバーインスタンスに適用されます。BucketCache の大きなサイズは一般的にパフォーマンスの向上に対応します |
|
|
134217728 |
Amazon S3 への Memstore フラッシュがトリガーされるデータ上限 (バイト単位)。 |
|
|
4 |
更新がブロックされる MemStore の上限を決定する乗数。MemStore がこの値で乗算されて |
|
|
10 |
更新がブロックされるまでストアに存在できる StoreFile の最大数。 |
|
|
10737418240 |
リージョンが分割されるまでのリージョンの最大サイズ。 |
データ損失のないクラスターのシャットダウンと復元
Amazon S3 に書き込まれていないデータを損失することなく Amazon EMR クラスターをシャットダウンするには、MemStore キャッシュを Amazon S3 にフラッシュして新しい格納ファイルを書き込む必要があります。まず、すべてのテーブルを無効にする必要があります。次の設定ステップはクラスターにステップを追加する際に使用することができます。詳細については「Amazon EMR 管理ガイド」の「AWS CLI およびコンソールを使用した手順の作業」を参照してください。
Name="Disable all tables",Jar="command-runner.jar",Args=["/bin/bash","/usr/lib/hbase/bin/disable_all_tables.sh"]
または、次の Bash コマンドを直接実行できます。
bash /usr/lib/hbase/bin/disable_all_tables.sh
すべてのテーブルを無効にした後に、HBase シェルと次のコマンドを使用して hbase:meta テーブルをフラッシュします。
flush 'hbase:meta'
次に、Amazon EMR クラスターで提供されているシェルスクリプトを実行して、MemStore キャッシュをフラッシュすることができます。これをステップとして追加するか、またはクラスター上の AWS CLI を使用して直接実行できます。このスクリプトは、各リージョンサーバーの MemStore が Amazon S3 にフラッシュする原因となるすべての HBase テーブルを無効にします。スクリプトが正常に完了すると、データは Amazon S3 に維持され、クラスターを終了できます。
同じ HBase データを使ってクラスターを再開するには、AWS Management Console の以前のクラスターとして同じ Amazon S3 の場所を指定するか、hbase.rootdir 設定プロパティを使用します。
