Amazon Redshift は、2025 年 11 月 1 日以降、新しい Python UDF の作成をサポートしなくなります。Python UDF を使用する場合は、その日付より前に UDF を作成してください。既存の Python UDF は引き続き通常どおり機能します。詳細については、ブログ記事
Amazon Redshift の概念の説明
Amazon Redshift Serverless を使用すると、プロビジョニングされたデータウェアハウスをすべて設定しなくても、データにアクセスして分析することができます。リソースは自動的にプロビジョニングされて、データウェアハウス容量はインテリジェントにスケーリングされ、要求が厳しく、予測不可能なワークロードであっても高速なパフォーマンスを実現します。データウェアハウスがアイドル状態のときには課金されず、使用した分のみ支払います。Amazon Redshift クエリエディタ v2 またはお好みのビジネスインテリジェンス (BI) ツールで、データをロードしてクエリを直ちに開始することができます。使いやすい管理不要の環境で、最高のコストパフォーマンスと使い慣れた SQL 機能をお楽しみください。
Amazon Redshift を初めて使用する方には、以下のセクションを初めに読むことをお勧めします。
-
Amazon Redshift Serverless 機能の概要 - このトピックでは、Amazon Redshift Serverless の概要と、その主要な機能について説明します。
-
主なサービスと料金設定
— この製品詳細ページでは、Amazon Redshift Serverless の主なサービスと料金設定を確認できます。 -
Amazon Redshift Serverless データウェアハウスの使用を開始。 — このトピックでは、Amazon Redshift Serverless データウェアハウスを作成する方法と、クエリエディタ v2 を使用してデータのクエリを開始する方法について説明します。
Amazon Redshift リソースを手動で管理したい場合は、データクエリのニーズに合わせてプロビジョニングされたクラスターを作成することができます。詳細については、「Amazon Redshift クラスター」を参照してください。
組織が適格であり、Amazon Redshift Serverless が利用できない AWS リージョン でクラスターが作成されている場合、Amazon Redshift 無料トライアルプログラムでクラスターを作成できる場合があります。[このクラスターを何に使用する予定ですか?] という質問に対して、[本番稼働用] または [無料トライアル] のいずれかを選択します。[無料トライアル] を選択したときには、dc2.large ノードタイプの設定を作成します。無料トライアルの選択に関する詳細については、「Amazon Redshift 無料トライアル
以下に、Amazon Redshift Serverless の主要な概念をいくつか示します。
-
名前空間 - データベースオブジェクトとユーザーのコレクションです。名前空間は、スキーマ、テーブル、ユーザー、データ共有、スナップショットなど、Amazon Redshift Serverless で使用するすべてのリソースをグループ化します。
-
ワークグループ - コンピューティングリソースの集合です。ワークグループには、Amazon Redshift Serverless が計算タスクを実行するために使用するコンピューティングリソースが含まれています。このようなリソースの例としては、Redshift 処理ユニット (RPU)、セキュリティグループ、使用制限などがあります。ワークグループには、Amazon Redshift Serverless コンソール、AWS Command Line Interface、または Amazon Redshift Serverless API を使用して設定できるネットワークとセキュリティ設定があります。
名前空間とワークグループリソースの設定の詳細については、「名前空間の使用」と「ワークグループの使用」を参照してください。
以下に、Amazon Redshift でプロビジョニングされたクラスターの主要な概念をいくつか示します:
-
クラスター – Amazon Redshift データウェアハウスの中核となるインフラストラクチャコンポーネントは、クラスターです。
クラスターは、1 つまたは複数のコンピューティングノードで構成されます。コンピューティングノードは、コンパイルされたコードを実行します。
クラスターが 2 つ以上のコンピューティングノードでプロビジョニングされている場合、追加のリーダーノードがコンピューティングノードを調整します。リーダーノードは、ビジネスインテリジェンスツールやクエリエディタなどのアプリケーションとの外部通信を処理します。クライアントアプリケーションはリーダーノードとのみ直接通信します。コンピューティングノードは外部アプリケーションに対して透過的です。
-
データベース – クラスターには、1 つ以上のデータベースが含まれています。
ユーザーデータは、コンピューティングノード上の 1 つ以上のデータベースに保存されます。SQL クライアントはリーダーノードと通信し、リーダーノードは実行中のクエリをコンピューティングノードと調整します。コンピューティングノードとリーダーノードの詳細については、データウェアハウスシステムのアーキテクチャを参照してください。データベース内では、ユーザーデータは 1 つ以上のスキーマに編成されます。
Amazon Redshift はリレーショナルデータベース管理システム (RDBMS) であり、他の RDBMS アプリケーションと互換性があります。それは、標準的な RDBMS と同じ機能、データの挿入や削除といったオンライントランザクション処理 (OLTP) 機能を提供します。Amazon Redshift は、データセットのハイパフォーマンスなバッチ分析とレポート作成にも最適化されています。
以下に、Amazon Redshift の一般的なデータ処理フローの説明とともに、フローのさまざまな部分の説明を示します。Amazon Redshift システムアーキテクチャーの詳細については、データウェアハウスシステムのアーキテクチャを参照してください。
次の図表は、Amazon Redshift の一般的なデータ処理フローを示しています。
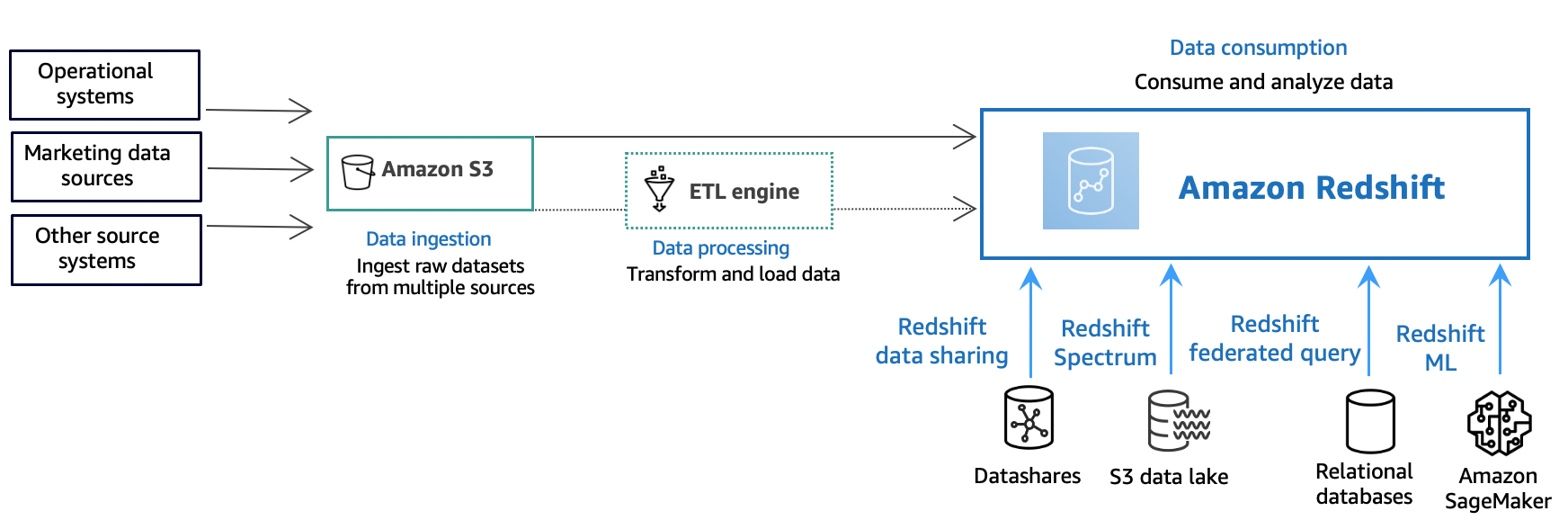
Amazon Redshift データウェアハウスは、エンタープライズクラスのリレーショナルデータベースのクエリおよび管理を行うためのシステムです。Amazon Redshift では、ビジネスインテリジェンス (BI) や、レポート作成、データ処理、分析用のツールなど、多種類のアプリケーションとのクライアント接続をサポートしています。分析クエリを実行するときは、大量のデータを複数のステージからなる操作で取得、比較、および評価して、最終的な結果を生成します。
データ取り込みレイヤーでは、さまざまなタイプのデータソースが、構造化データ、半構造化データ、非構造化データをデータストレージレイヤーに継続的にアップロードします。このデータストレージエリアは、さまざまな消費準備状態のデータを保存するステージングエリアとして機能します。ストレージの例として、Amazon Simple Storage Service (Amazon S3) バケットがあります。
オプションのデータ処理レイヤーでは、ソースデータは、抽出、変換、ロード (ETL)、または抽出、ロード、変換 (ELT) パイプラインを使用して、前処理、検証、変換を行います。これらの生のデータセットは、ETL オペレーションを使用して洗練されます。ETLエンジンの例はAWS Glueです。
データ消費レイヤーでは、データが Amazon Redshift クラスターにロードされ、そこで分析ワークロードを実行できます。
分析ワークロードの例については、「外部データソースへのクエリ」を参照してください。
