기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
VPC 흐름 로그를 사용하여 IP 트래픽 로깅
VPC 흐름 로그는 VPC의 네트워크 인터페이스에서 전송되고 수신되는 IP 트래픽에 대한 정보를 수집할 수 있는 기능입니다. 플로우 로그 데이터는 Amazon CloudWatch Logs, Amazon S3 또는 Amazon Data Firehose와 같은 위치에 게시할 수 있습니다. 흐름 로그를 생성하면 구성한 로그 그룹, 버킷 또는 전송 스트림의 흐름 로그 레코드를 검색하고 볼 수 있습니다.
흐름 로그는 다음과 같은 여러 작업에 도움이 될 수 있습니다.
-
지나치게 제한적인 보안 그룹 규칙 진단
-
인스턴스에 도달하는 트래픽 모니터링
-
네트워크 인터페이스를 오가는 트래픽 방향 결정
흐름 로그 데이터는 네트워크 트래픽 경로 외부에서 수집되므로 네트워크 처리량이나 지연 시간에 영향을 주지 않습니다. 네트워크 성능에 영향을 주지 않고 흐름 로그를 생성하거나 삭제할 수 있습니다.
목차
흐름 로그 기본 사항
VPC, 서브넷 또는 네트워크 인터페이스에 대한 흐름 로그를 생성할 수 있습니다. 서브넷이나 VPC에 대한 흐름 로그를 생성할 경우, VPC 또는 서브넷의 각 네트워크 인터페이스가 모니터링됩니다.
모니터링된 네트워크 인터페이스를 위한 흐름 로그 데이터는 트래픽 흐름을 설명하는 필드로 구성된 로그 이벤트인 흐름 로그 레코드로서 기록됩니다. 자세한 내용은 흐름 로그 레코드 단원을 참조하세요.
흐름 로그를 생성하려면 다음을 지정합니다.
-
흐름 로그를 생성할 리소스
-
캡처할 트래픽 유형(허용된 트래픽, 거부된 트래픽 또는 모든 트래픽)
-
흐름 로그 데이터를 게시할 대상
다음 예에서는 프라이빗 서브넷의 EC2 인스턴스 중 하나의 네트워크 인터페이스에 대해 허용된 트래픽을 캡처하고 흐름 로그 레코드를 Amazon S3 버킷에 게시하는 흐름 로그를 생성합니다.
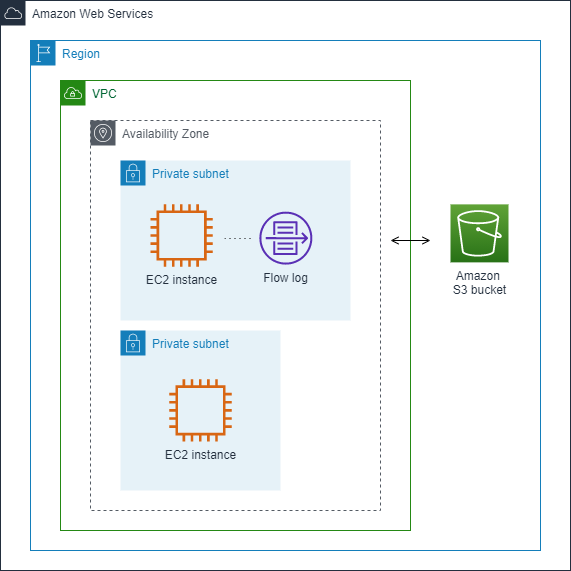
다음 예제에서 흐름 로그는 서브넷의 모든 트래픽을 캡처하고 흐름 로그 레코드를 Amazon CloudWatch Logs에 게시합니다. 흐름 로그는 서브넷의 모든 네트워크 인터페이스에 대한 트래픽을 캡처합니다.
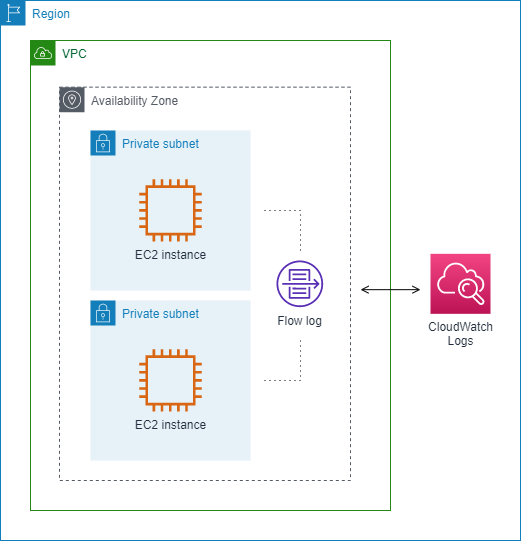
흐름 로그를 생성한 후에는, 데이터를 수집하여 선택된 대상에 게시하는 데 몇 분의 시간이 소요될 수 있습니다. 흐름 로그는 네트워크 인터페이스에 대한 로그 스트림을 실시간으로 캡처하지 않습니다. 자세한 설명은 흐름 로그 생성 섹션을 참조하세요.
서브넷 또는 VPC에 대한 흐름 CloudWatch 로그를 생성한 후 서브넷에서 인스턴스를 시작하면 네트워크 인터페이스에 네트워크 트래픽이 발생하는 즉시 새 네트워크 인터페이스에 대한 로그 스트림 (Logs) 또는 로그 파일 객체 (Amazon S3용) 가 생성됩니다.
다음과 같은 다른 AWS 서비스에서 생성한 네트워크 인터페이스에 대한 흐름 로그를 생성할 수 있습니다.
-
Elastic Load Balancing
-
Amazon RDS
-
아마존 ElastiCache
-
Amazon Redshift
-
아마존 WorkSpaces
-
NAT 게이트웨이
-
전송 게이트웨이
네트워크 인터페이스 유형에 관계없이 Amazon EC2 콘솔 또는 Amazon EC2 API를 사용하여 네트워크 인터페이스에 대한 흐름 로그를 작성해야 합니다.
흐름 로그에 태그를 적용할 수 있습니다. 각 태그는 사용자가 정의하는 키와 선택적 값으로 구성됩니다. 태그는 흐름 로그를 용도나 소유자별로 구성하는 데 도움이 될 수 있습니다.
흐름 로그가 더 이상 필요하지 않을 경우 삭제할 수 있습니다. 흐름 로그를 삭제하면 리소스에 대한 흐름 로그 서비스가 비활성화되어 생성되거나 게시되는 새 흐름 로그 레코드가 없습니다. 흐름 로그를 삭제해도 기존 흐름 로그 데이터는 삭제되지 않습니다. 흐름 로그를 삭제하면 작업을 마무리했을 때 대상에서 직접 흐름 로그 데이터를 삭제할 수 있습니다. 자세한 설명은 흐름 로그 삭제 섹션을 참조하세요.
흐름 로그 레코드
흐름 로그 레코드는 VPC에 네트워크 흐름을 나타냅니다. 기본적으로 각 레코드는 캡처 기간이라고도 하는 집계 간격 내에 발생하는 네트워크 인터넷 프로토콜(IP) 트래픽 흐름(네트워크 인터페이스별로 5튜플을 특징으로 함)을 캡처합니다.
각 레코드는 필드가 공백으로 구분되어 있는 문자열입니다. 레코드에는 소스, 대상, 프로토콜 등 IP 흐름의 다양한 구성 요소에 대한 값이 포함됩니다.
흐름 로그를 생성할 때 흐름 로그 레코드의 기본 형식을 사용하거나 사용자 지정 형식을 지정할 수 있습니다.
집계 간격
집계 간격은 특정 흐름이 캡처되어 흐름 로그 레코드로 집계되는 기간입니다. 기본적으로 최대 집계 간격은 10분입니다. 흐름 로그를 만들 때 선택적으로 최대 집계 간격을 1분으로 지정할 수 있습니다. 최대 집계 간격이 1분인 흐름 로그는 최대 집계 간격이 10분인 흐름 로그보다 더 많은 양의 흐름 로그 레코드를 생성합니다.
네트워크 인터페이스가 NITRO 기반 인스턴스에 연결된 경우 집계 간격은 지정된 최대 집계 간격에 관계없이 항상 1분 이하입니다.
집계 간격 내에 데이터를 캡처한 후에는 데이터를 처리하고 CloudWatch Logs 또는 Amazon S3에 게시하는 데 추가 시간이 걸립니다. 흐름 로그 서비스는 일반적으로 약 5분 내에 로그를 CloudWatch Logs (로그) 에 전송하고 Amazon S3에 약 10분 후에 로그를 전송합니다. 그러나 로그 전달에 최선의 노력을 기울이고 로그가 일반적인 전달 시간을 초과하여 지연될 수 있습니다.
기본 형식
기본 형식의 흐름 로그 레코드에는 사용 가능한 필드 테이블에 표시되는 순서대로 버전 2 필드가 포함됩니다. 기본 형식을 사용자 정의하거나 변경할 수 없습니다. 추가 필드 또는 다른 필드 하위 세트를 캡처하려면 사용자 지정 형식을 지정합니다.
사용자 지정 형식
사용자 지정 형식을 사용하면 흐름 로그 레코드에 포함되는 필드와 그 순서를 지정할 수 있습니다. 이를 통해 요구 사항에 맞는 흐름 로그를 만들고 관련이 없는 필드를 생략할 수 있습니다. 사용자 지정 형식을 사용하면 게시된 흐름 로그에서 특정 정보를 추출하기 위해 별도의 프로세스가 필요하지 않습니다. 사용 가능한 흐름 로그 필드를 얼마든지 지정할 수 있지만 하나 이상을 지정해야 합니다.
사용 가능한 필드
다음 표는 흐름 로그 레코드에 사용 가능한 모든 필드를 설명합니다. 버전(Version) 열은 해당 필드를 도입한 VPC 흐름 로그의 버전을 나타냅니다. 기본 형식에는 모든 버전 2 필드가 테이블에 표시되는 순서와 동일하게 포함됩니다.
Amazon S3 흐름 로그 데이터를 게시할 때 필드의 데이터 유형은 흐름 로그 형식에 따라 다릅니다. 형식이 일반 텍스트인 경우 모든 필드는 STRING 유형입니다. 형식이 Parquet 인 경우 필드 데이터 유형에 대한 표를 참조하십시오.
필드를 적용할 수 없거나 특정 레코드에 대해 계산할 수 없는 경우 레코드는 해당 항목에 대해 '-' 기호를 표시합니다. 패킷 헤더에서 직접 제공되지 않는 메타데이터 필드는 최선의 작업 수준 근사값이며 해당 값이 누락되거나 정확하지 않을 수 있습니다.
| 필드 | 설명 | 버전 |
|---|---|---|
|
version |
VPC 흐름 로그 버전. 기본 형식을 사용하는 경우, 버전은 2입니다. 사용자 지정 형식을 사용하는 경우, 버전은 지정된 필드 중에서 가장 높은 버전입니다. 예를 들어 버전 2의 필드만 지정한다면 버전은 2가 됩니다. 버전 2, 3 및 4의 필드를 혼합하여 지정한다면 버전은 4가 됩니다. Parquet 데이터 유형: INT_32 |
2 |
|
account-id |
트래픽이 기록되는 소스 네트워크 인터페이스 소유자의 AWS 계정 ID입니다. AWS 서비스에서 네트워크 인터페이스를 생성하는 경우 (예: VPC 엔드포인트 또는 Network Load Balancer) 를 생성할 때 이 필드에 레코드가 unknown 표시될 수 있습니다. Parquet 데이터 유형: 문자열 |
2 |
|
interface-id |
트래픽이 기록되는 네트워크 인터페이스 ID. Parquet 데이터 유형: 문자열 |
2 |
|
srcaddr |
들어오는 트래픽의 소스 주소 또는 네트워크 인터페이스의 나가는 트래픽의 네트워크 인터페이스의 IPv4 또는 IPv6 주소. 네트워크 인터페이스의 IPv4 주소는 항상 해당 프라이빗 IPv4 주소입니다. 또한 pkt-srcaddr 단원도 참조하십시오. Parquet 데이터 유형: 문자열 |
2 |
|
dstaddr |
나가는 트래픽의 대상 주소 또는 네트워크 인터페이스의 들어오는 트래픽의 네트워크 인터페이스의 IPv4 또는 IPv6 주소. 네트워크 인터페이스의 IPv4 주소는 항상 해당 프라이빗 IPv4 주소입니다. 또한 pkt-dstaddr 단원도 참조하십시오. Parquet 데이터 유형: 문자열 |
2 |
|
srcport |
트래픽의 소스 포트 Parquet 데이터 유형: INT_32 |
2 |
|
dstport |
트래픽의 대상 포트 Parquet 데이터 유형: INT_32 |
2 |
|
protocol |
트래픽의 IANA 프로토콜 번호. 자세한 정보는 지정된 인터넷 프로토콜 번호 Parquet 데이터 유형: INT_32 |
2 |
|
packets |
흐름 중 전송된 패킷 수. Parquet 데이터 유형: INT_64 |
2 |
|
bytes |
흐름 중 전송된 바이트 수. Parquet 데이터 유형: INT_64 |
2 |
|
start |
흐름의 첫 번째 패킷이 집계 간격 내에서 수신된 시간(단위: Unix 초)입니다. 이 시간은 패킷이 네트워크 인터페이스에서 전송되거나 수신된 후 최대 60초가 될 수 있습니다. Parquet 데이터 유형: INT_64 |
2 |
|
end |
집계 간격 내에서 흐름의 마지막 패킷을 수신한 시간(단위: Unix 초)입니다. 이 시간은 패킷이 네트워크 인터페이스에서 전송되거나 수신된 후 최대 60초가 될 수 있습니다. Parquet 데이터 유형: INT_64 |
2 |
|
action |
트래픽과 연결된 작업
Parquet 데이터 유형: 문자열 |
2 |
|
log-status |
흐름 로그의 로깅 상태:
Parquet 데이터 유형: 문자열 |
2 |
|
vpc-id |
트래픽이 기록되는 네트워크 인터페이스를 포함하는 VPC의 ID. Parquet 데이터 유형: 문자열 |
3 |
|
subnet-id |
트래픽이 기록되는 네트워크 인터페이스를 포함하는 서브넷의 ID. Parquet 데이터 유형: 문자열 |
3 |
|
instance-id |
인스턴스를 소유한 경우 트래픽이 기록되는 네트워크 인터페이스와 연결된 인스턴스의 ID입니다. NAT 게이트웨이의 네트워크 인터페이스 같은 요청자 관리 네트워크 인터페이스에는 '-' 기호를 반환합니다. Parquet 데이터 유형: 문자열 |
3 |
|
tcp-flags |
다음 TCP 플래그의 비트 마스크 값:
-입니다. 플래그가 전송되지 않는 경우 TCP 플래그 값은 0입니다.TCP 플래그는 집계 간격 동안 OR일 수 있습니다. 짧은 연결의 경우 SYN-ACK 및 FIN에 대해 19, SYN 및 FIN에 대해 3과 같이 흐름 로그 레코드의 동일한 행에 플래그가 설정될 수 있습니다. 문제 해결 예는 TCP 플래그 시퀀스을(를) 참조하십시오. TCP 플래그에 대한 일반 정보(예: FIN, SYN 및 ACK와 같은 플래그의 의미)는 Wikipedia에서 TCP 세그먼트 구조 Parquet 데이터 유형: INT_32 |
3 |
|
type |
트래픽 유형입니다. 가능한 값: IPv4 | IPv6 | EFA. 자세한 내용은 Elastic Fabric Adapter(EFA) 섹션을 참조하십시오. Parquet 데이터 유형: 문자열 |
3 |
|
pkt-srcaddr |
트래픽의 패킷 수준(원본) 소스 IP 주소입니다. 이 필드를 srcaddr 필드와 함께 사용하면 트래픽이 흐르는 중간 계층의 IP 주소와 트래픽의 원래 소스 IP 주소를 구별 할 수 있습니다. 대표적인 경우는 트래픽이 NAT 게이트웨이에 대한 네트워크 인터페이스를 통과하거나 Amazon EKS의 포드 IP 주소가 포드가 실행 중인(VPC 내 통신용) 인스턴스 노드의 네트워크 인터페이스 IP 주소와 다른 경우입니다. Parquet 데이터 유형: 문자열 |
3 |
|
pkt-dstaddr |
트래픽의 패킷 수준(원본) 대상 IP 주소입니다. 이 필드를 dstaddr 필드와 함께 사용하면 트래픽이 흐르는 중간 계층의 IP 주소와 트래픽의 최종 대상 IP 주소를 구별 할 수 있습니다. 대표적인 경우는 트래픽이 NAT 게이트웨이에 대한 네트워크 인터페이스를 통과하거나 Amazon EKS의 포드 IP 주소가 포드가 실행 중인(VPC 내 통신용) 인스턴스 노드의 네트워크 인터페이스 IP 주소와 다른 경우입니다. Parquet 데이터 유형: 문자열 |
3 |
|
region |
트래픽이 기록되는 네트워크 인터페이스가 포함된 리전입니다. Parquet 데이터 유형: 문자열 |
4 |
|
az-id |
트래픽이 기록되는 네트워크 인터페이스가 포함된 가용 영역의 ID입니다. 하위 위치에서 트래픽이 발생한 경우 레코드는 이 필드에 대해 '-' 기호를 표시합니다. Parquet 데이터 유형: 문자열 |
4 |
|
sublocation-type |
sublocation-id 필드에 반환되는 하위 위치 유형입니다. 가능한 값: wavelength Parquet 데이터 유형: 문자열 |
4 |
|
sublocation-id |
트래픽이 기록되는 네트워크 인터페이스가 포함된 하위 위치의 ID입니다. 트래픽이 하위 위치에서 발생하지 않는 경우 레코드는 이 필드에 대해 '-' 기호를 표시합니다. Parquet 데이터 유형: 문자열 |
4 |
|
pkt-src-aws-service |
소스 IP 주소가 서비스용인 경우 pkt-srcaddr 필드의 IP 주소 범위 하위 집합 이름. AWS 가능한 값: AMAZON | AMAZON_APPFLOW | AMAZON_CONNECT | API_GATEWAY | CHIME_MEETINGS | CHIME_VOICECONNECTOR | CLOUD9 | CLOUDFRONT | CODEBUILD | DYNAMODB | EBS | EC2 | EC2_INSTANCE_CONNECT | GLOBALACCELERATOR | KINESIS_VIDEO_STREAMS | ROUTE53 | ROUTE53_HEALTHCHECKS | ROUTE53_HEALTHCHECKS_PUBLISHING | ROUTE53_RESOLVER | S3 | WORKSPACES_GATEWAYS. Parquet 데이터 유형: 문자열 |
5 |
|
pkt-dst-aws-service |
대상 IP 주소가 서비스용인 경우 pkt-dstaddr 필드의 IP 주소 범위 하위 집합 이름. AWS 가능한 값 목록은 pkt-src-aws-service 필드를 참조하십시오. Parquet 데이터 유형: 문자열 |
5 |
|
flow-direction |
트래픽이 캡처되는 인터페이스에 대한 흐름 방향입니다. 가능한 값: ingress | egress Parquet 데이터 유형: 문자열 |
5 |
|
traffic-path |
송신 트래픽이 대상으로 이동하는 경로입니다. 트래픽이 송신 트래픽인지 여부를 확인하려면 flow-direction 필드를 확인하십시오. 가능한 값은 다음과 같습니다. 적용되는 값이 없는 경우 필드는 -로 설정됩니다.
Parquet 데이터 유형: INT_32 |
5 |
흐름 로그 제한
흐름 로그를 사용하려면 다음과 같은 제한 사항을 알아 두어야 합니다.
-
피어 VPC가 본인의 계정이 아닌 한, 본인의 VPC와 피어링된 VPC에 대해 흐름 로그를 활성화할 수 없습니다.
-
흐름 로그를 만든 후에는 구성 또는 흐름 로그 레코드 형식을 변경할 수 없습니다. 예를 들어 다른 IAM 역할을 흐름 로그와 연결하거나 흐름 로그 레코드에서 필드를 추가 또는 제거할 수 없습니다. 대신에 흐름 로그를 삭제한 후 필요한 구성으로 새로운 흐름 로그를 생성할 수 있습니다.
-
네트워크 인터페이스에 IPv4 주소가 여러 개 있고 트래픽이 보조 프라이빗 IPv4 주소로 전송되는 경우, 흐름 로그는
dstaddr필드에 주 프라이빗 IPv4 주소를 표시합니다. 원래 대상 IP 주소를 캡처하려면pkt-dstaddr필드로 흐름 로그를 작성하십시오. -
트래픽이 네트워크 인터페이스로 전송된 경우 대상이 네트워크 인터페이스의 IP 주소가 아니면 흐름 로그에
dstaddr필드의 기본 프라이빗 IPv4 주소가 표시됩니다. 원래 대상 IP 주소를 캡처하려면pkt-dstaddr필드로 흐름 로그를 작성하십시오. -
트래픽이 네트워크 인터페이스에서 전송된 경우 원본이 네트워크 인터페이스의 IP 주소가 아니면, 흐름 로그에
srcaddr필드의 기본 프라이빗 IPv4 주소가 표시됩니다. 원래 원본 IP 주소를 캡처하려면pkt-srcaddr필드로 흐름 로그를 작성하십시오. -
트래픽이 네트워크 인터페이스를 오가는 경우 흐름 로그의
srcaddr,dstaddr필드는 패킷 원본 또는 대상에 관계없이 항상 기본 프라이빗 IPv4 주소를 표시합니다. 패킷 소스 또는 대상을 캡처하려면pkt-srcaddr및pkt-dstaddr필드를 사용하여 흐름 로그를 작성하십시오. -
네트워크 인터페이스가 NITRO 기반 인스턴스에 연결된 경우 집계 간격은 지정된 최대 집계 간격에 관계없이 항상 1분 이하입니다.
흐름 로그는 모든 IP 트래픽을 캡처하지는 않습니다. 다음 트래픽 유형은 기록되지 않습니다.
-
인스턴스가 Amazon DNS 서버에 연결할 때 생성한 트래픽. 자체 DNS 서버를 사용할 경우 DNS 서버에 대한 모든 트래픽은 기록됩니다.
-
Amazon Windows 라이선스 인증을 위해 Windows 인스턴스에서 생성한 트래픽.
-
인스턴스 메타데이터를 위해
169.254.169.254와 주고받는 트래픽. -
Amazon Time Sync Service를 위해
169.254.169.123와 주고받는 트래픽. -
DHCP 트래픽.
-
미러링된 트래픽.
-
기본 VPC 라우터의 예약된 IP 주소로 보내는 트래픽.
-
엔드포인트 네트워크 인터페이스와 Network Load Balancer 네트워크 인터페이스 간의 트래픽.
요금
흐름 로그를 게시하면 벤딩 로그에 대한 데이터 모으기 및 보관 요금이 적용됩니다. 벤드 로그를 게시할 때의 요금에 대한 자세한 내용은 Amazon CloudWatch Pricing을
흐름 로그 게시의 요금을 추적하려는 경우 대상 리소스에 비용 할당 태그를 적용할 수 있습니다. 이후 AWS 비용 할당 보고서에는 이러한 태그별로 집계된 사용량 및 비용이 포함됩니다. 비즈니스 범주를 나타내는 태그(예: 비용 센터, 애플리케이션 이름 또는 소유자)를 적용하여 비용을 정리할 수 있습니다. 자세한 내용은 다음 자료를 참조하십시오.
-
AWS Billing 사용 설명서의 비용 할당 태그 사용
-
Amazon CloudWatch Logs 사용 설명서의 Amazon Logs의 CloudWatch 로그 그룹에 태그를 지정하십시오.
-
Amazon Simple Storage Service 사용 설명서의 비용 할당 S3 버킷 태그 사용
-
Amazon Data Firehose 개발자 가이드에서 전송 스트림에 태그 지정하기
