Como registrar tráfego IP em log com logs de fluxo da VPC
O VPC Flow Logs é um recurso que possibilita que você capture informações sobre o tráfego de IP para e proveniente de interfaces de rede da VPC. Os dados do log de fluxo podem ser publicados nos seguintes locais: Amazon CloudWatch Logs, Amazon S3 ou Amazon Data Firehose. Depois de criar um log de fluxo, você poderá recuperar e visualizar os registros do log de fluxo no grupo de logs, no bucket ou no fluxo de entrega configurado.
Os logs de fluxo podem ajudar em diversas tarefas, como:
-
Diagnosticar regras de grupo de segurança excessivamente restritivas
-
Monitorar o tráfego que chega à sua instância
-
Determinar a direção de entrada e saída do tráfego das interfaces de rede
Os dados do log de fluxo são coletados fora do caminho do tráfego de rede e, portanto, não afetam o throughput nem a latência da rede. É possível criar ou excluir logs de fluxo sem qualquer risco de impacto na pérformance da rede.
Tópicos
- Noções básicas de logs de fluxo
- Registros de log de fluxo
- Exemplos de registro de log de fluxo
- Limitações do log de fluxo
- Definição de preço
- Trabalhar com logs de fluxo
- Publicar logs de fluxo no CloudWatch Logs
- Publicar logs de fluxo no Amazon S3
- Publicar logs de fluxo no Amazon Data Firehose
- Consultar logs de fluxo usando o Amazon Athena
- Solucionar problemas do VPC Flow Logs
Noções básicas de logs de fluxo
É possível criar um log de fluxo para VPC, sub-rede ou interface de rede. Se você criar um log de fluxo para uma sub-rede ou VPC, toda interface de rede na sub-rede ou VPC será monitorada.
Os dados de log de fluxo para uma interface de rede monitorada são registrados como registros de log de fluxo, que são eventos de log que consistem em campos que descrevem o fluxo de tráfego. Para obter mais informações, consulte Registros de log de fluxo.
Para criar um log de fluxo, especifique:
-
O recurso para o qual criar o log de fluxo
-
O tipo de tráfego a ser capturado (tráfego aceito, tráfego rejeitado ou todo o tráfego)
-
Os destinos em que você quer publicar os dados de log de fluxo
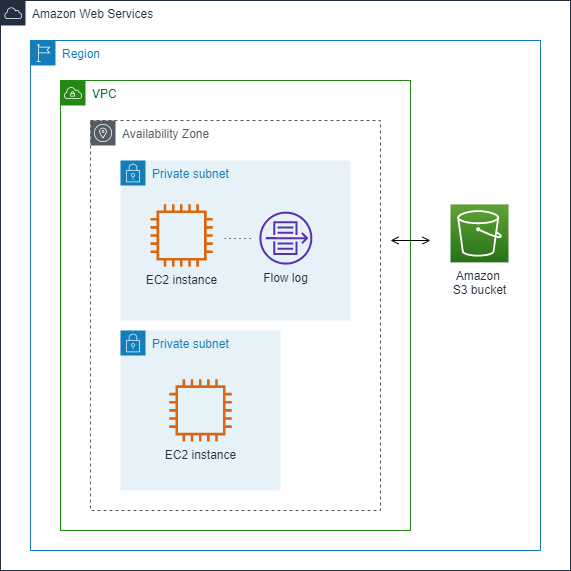
No exemplo a seguir, crie um log de fluxo que capture o tráfego aceito para a interface de rede de uma das instâncias do EC2 em uma sub-rede privada e publica os registros de log de fluxo em um bucket do Amazon S3.
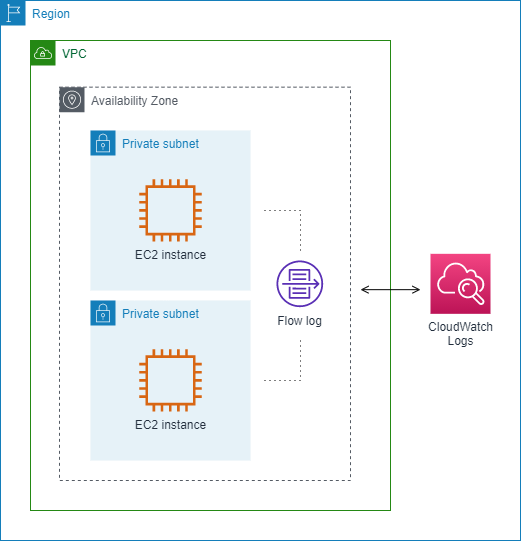
No seguinte exemplo, um log de fluxo captura todo o tráfego para a sub-rede e publica os registros do log de fluxo no Amazon CloudWatch Logs. O log de fluxo captura o tráfego para todas as interfaces de rede na sub-rede.
Depois que você criar um log de fluxo, pode demorar alguns minutos para começar a coletar e publicar dados nos destinos selecionados. Os logs de fluxo não capturam streams de logs em tempo real para suas interfaces de rede. Para ter mais informações, consulte Criar um log de fluxo.
Se você iniciar uma instância na sua sub-rede depois de criar um log de fluxo para a sua sub-rede ou VPC, criaremos um fluxo de logs (para o CloudWatch Logs) ou objeto de arquivo de log (para o Amazon S3) para a nova interface de rede assim que houver tráfego de rede para a interface de rede.
Você pode criar logs de fluxo para interfaces de rede que são criadas por outros serviços da AWS, como:
-
Elastic Load Balancing
-
Amazon RDS
-
Amazon ElastiCache
-
Amazon Redshift
-
Amazon WorkSpaces
-
Gateways NAT
-
Gateways de trânsito
Independentemente do tipo de interface de rede, é necessário usar o console ou a API do Amazon EC2 para criar um log de fluxo para uma interface de rede.
É possível aplicar tags aos logs de fluxo. Cada tag consiste de uma chave e um valor opcional, ambos definidos por você. As tags podem ajudar você a organizar seus logs de fluxo. Por exemplo, por finalidade ou proprietário.
Caso não precise mais de um log de fluxo, você pode excluí-lo. A exclusão de um log de fluxo desabilita o serviço de log de fluxo para o recurso, de modo que novos registros de log de fluxo não são criados nem publicados. A exclusão de um log de fluxo não exclui qualquer dado existente do log de fluxo. Depois de excluir um log de fluxo, você pode excluir os dados do log de fluxo diretamente do destino quando terminar de usá-lo. Para ter mais informações, consulte Excluir um log de fluxo.
Registros de log de fluxo
Um registro de log de fluxo representa um fluxo de rede na VPC. Por padrão, cada registro captura um fluxo de tráfego de protocolo de Internet (IP) da rede (caracterizado por 5 tuplas em uma base de interface de rede) que ocorre dentro de um intervalo de agregação, também referido como uma janela de captura.
Cada registro é uma string com campos separados por espaços. Um registro inclui valores para os diferentes componentes do fluxo IP como, por exemplo, a origem, o destino e o protocolo.
Ao criar um log de fluxo, é possível usar o formato padrão do registro de log de fluxo ou especificar um formato personalizado.
Intervalo de agregação
O intervalo de agregação é o período durante o qual um fluxo específico é capturado e agregado em um registro de log de fluxo. Por padrão, o intervalo de agregação máximo é de dez minutos. Ao criar um log de fluxo, você pode especificar um intervalo de agregação máximo de 1 minuto, opcionalmente. Os logs de fluxo com um intervalo de agregação máximo de 1 minuto geram um volume mais alto de registros de log de fluxo que os logs de fluxo com um intervalo de agregação máximo de 10 minutos.
Quando uma interface de rede é anexada a uma instância baseada em Nitro, o intervalo de agregação é sempre 1 minuto ou menos, independentemente do intervalo de agregação máximo especificado.
Depois que os dados forem capturados em um intervalo de agregação, será necessário tempo adicional para processar e publicar os dados no CloudWatch Logs e no Amazon S3. O serviço de log de fluxo geralmente fornece logs para o CloudWatch Logs em cerca de 5 minutos e para o Amazon S3 em cerca de 10 minutos. No entanto, a entrega de logs baseia-se no melhor esforço, e seus registros podem ser atrasados além do tempo de entrega típico.
Formato padrão
Com o formato padrão, os registros de log de fluxo incluem os campos da versão 2, na ordem mostrada na tabela de campos disponíveis. Não é possível personalizar ou alterar o formato padrão. Para capturar campos adicionais disponíveis ou um subconjunto de campos diferente, especifique um formato personalizado em vez disso.
Formato personalizado
Com um formato personalizado, você especifica quais campos estão incluídos nos registros de log de fluxo e em qual ordem. Isso permite que você crie logs de fluxo específicos para suas necessidades e omita campos que não são relevantes. Usar um formato personalizado pode diminuir a necessidade de processos separados para extrair informações específicas dos logs de fluxo publicados. É possível especificar qualquer quantidade de campos disponíveis do log de fluxo, mas você deve especificar pelo menos um.
Campos disponíveis
A tabela a seguir descreve todos os campos disponíveis para um registro de log de fluxo. A coluna Versão indica a versão do VPC Flow Logs na qual o campo foi introduzido. O formato padrão inclui todos os campos da versão 2, na mesma ordem em que aparecem na tabela.
Ao publicar dados de log de fluxo no Amazon S3, o tipo de dados para os campos dependerá do formato do log de fluxo. Se o formato estiver como texto sem formatação, todos os campos serão do tipo STRING. Se o formato for Parquet, consulte a tabela para os tipos de dados de campo.
Se um campo não for aplicável ou não puder ser computado para um registro específico, o registro exibirá o símbolo '-' para essa entrada. Os campos de metadados que não vêm diretamente do cabeçalho do pacote são aproximações e seus valores podem estar ausentes ou imprecisos.
| Campo | Descrição | Versão |
|---|---|---|
|
version |
A versão dos logs de fluxo da VPC. Se você usar o formato padrão, a versão será 2. Se você usar um formato personalizado, a versão será a versão mais alta entre os campos especificados. Por exemplo, se você especificar apenas os campos da versão 2, a versão será 2. Se você especificar uma mistura de campos das versões 2, 3 e 4, a versão será 4. Tipo de dados em Parquet: INT_32 |
2 |
|
account-id |
O ID da conta da AWS do proprietário da interface de rede de origem para a qual o tráfego é registrado. Se a interface de rede for criada por um serviço da AWS, por exemplo, ao criar um endpoint da VPC ou Network Load Balancer, o registro poderá exibir unknown para esse campo. Tipo de dados em Parquet: STRING |
2 |
|
interface-id |
O ID da interface de rede para a qual o tráfego é registrado. Tipo de dados em Parquet: STRING |
2 |
|
srcaddr |
O endereço de origem do tráfego de entrada ou o endereço IPv4 ou IPv6 da interface de rede do tráfego de saída na interface de rede. O endereço IPv4 da interface de rede sempre é o respectivo endereço IPv4 privado. Consulte também pkt-srcaddr. Tipo de dados em Parquet: STRING |
2 |
|
dstaddr |
O endereço de destino do tráfego de saída ou o endereço IPv4 ou IPv6 da interface de rede do tráfego de entrada na interface de rede. O endereço IPv4 da interface de rede sempre é o respectivo endereço IPv4 privado. Consulte também pkt-dstaddr. Tipo de dados em Parquet: STRING |
2 |
|
srcport |
A porta de origem do tráfego. Tipo de dados em Parquet: INT_32 |
2 |
|
dstport |
A porta de destino do tráfego. Tipo de dados em Parquet: INT_32 |
2 |
|
protocol |
O número do protocolo IANA do tráfego. Para obter mais informações, consulte Assigned Internet Protocol Numbers Tipo de dados em Parquet: INT_32 |
2 |
|
packets |
O número de pacotes transferidos durante o fluxo. Tipo de dados em Parquet: INT_64 |
2 |
|
bytes |
O número de bytes transferidos durante o fluxo. Tipo de dados em Parquet: INT_64 |
2 |
|
start |
O tempo, em segundos Unix, quando o primeiro pacote de fluxo foi recebido no intervalo de agregação. Isso pode ocorrer até 60 segundos após o pacote ter sido transmitido ou recebido na interface de rede Tipo de dados em Parquet: INT_64 |
2 |
|
end |
O tempo, em segundos Unix, quando o último pacote de fluxo foi recebido dentro do intervalo de agregação. Isso pode ocorrer até 60 segundos após o pacote ter sido transmitido ou recebido na interface de rede Tipo de dados em Parquet: INT_64 |
2 |
|
action |
A ação associada ao tráfego:
Tipo de dados em Parquet: STRING |
2 |
|
log-status |
O status de registro do log de fluxo:
Tipo de dados em Parquet: STRING |
2 |
|
vpc-id |
O ID da VPC que contém a interface de rede para a qual o tráfego é registrado. Tipo de dados em Parquet: STRING |
3 |
|
subnet-id |
O ID da sub-rede que contém a interface de rede para a qual o tráfego é registrado. Tipo de dados em Parquet: STRING |
3 |
|
instance-id |
O ID da instância associada à interface de rede para a qual o tráfego é registrado, caso a instância seja de sua propriedade. Retorna um símbolo “-” para uma interface de rede gerenciada pelo solicitante; por exemplo, a interface de rede de um gateway NAT. Tipo de dados em Parquet: STRING |
3 |
|
tcp-flags |
O valor da máscara de bits para os seguintes sinalizadores TCP:
-. Se nenhum sinalizador for enviado, o valor do sinalizador TCP será 0.Os sinalizadores TCP podem ser processados com o operador OR durante o intervalo de agregação. Para conexões curtas, os sinalizadores podem ser definidos na mesma linha no registro de log de fluxo, por exemplo, 19 para SYN-ACK e FIN, e 3 para SYN e FIN. Para ver um exemplo, consulte Sequência de sinalizadores TCP. Para obter informações gerais sobre sinalizadores TCP (por exemplo, o significado de sinalizadores FIN, SYN e ACK), consulte Estrutura de segmentos TCP Tipo de dados em Parquet: INT_32 |
3 |
|
type |
O tipo de tráfego. Os valores possíveis são: IPv4 | IPv6 | EFA. Para obter mais informações, consulte Elastic Fabric Adapter. Tipo de dados em Parquet: STRING |
3 |
|
pkt-srcaddr |
O endereço IP de origem (original) no nível do pacote do tráfego. Use esse campo com o campo srcaddr para diferenciar o endereço IP de uma camada intermediária pela qual o tráfego flui e o endereço IP de origem original do tráfego. Por exemplo, quando o tráfego flui por uma interface de rede para um gateway NAT ou quando o endereço IP de um pod no Amazon EKS é diferente do endereço IP da interface de rede do nó da instância em que o dispositivo está em execução (para comunicação dentro de uma VPC). Tipo de dados em Parquet: STRING |
3 |
|
pkt-dstaddr |
O endereço IP de destino (original) no nível do pacote do tráfego. Use esse campo com o campo dstaddr para diferenciar o endereço IP de uma camada intermediária pela qual o tráfego flui e o endereço IP de destino final do tráfego. Por exemplo, quando o tráfego flui por uma interface de rede para um gateway NAT ou quando o endereço IP de um pod no Amazon EKS é diferente do endereço IP da interface de rede do nó da instância em que o dispositivo está em execução (para comunicação dentro de uma VPC). Tipo de dados em Parquet: STRING |
3 |
|
region |
A região que contém a interface de rede para a qual o tráfego é registrado. Tipo de dados em Parquet: STRING |
4 |
|
az-id |
O ID da zona de disponibilidade que contém a interface de rede para a qual o tráfego é registrado. Se o tráfego for de uma sublocalização, o registro exibirá um símbolo '-' para este campo. Tipo de dados em Parquet: STRING |
4 |
|
sublocation-type |
O tipo de sublocalização que é retornado no campo sublocation-id. Os valores possíveis são: wavelength Tipo de dados em Parquet: STRING |
4 |
|
sublocation-id |
O ID da sublocalização que contém a interface de rede para a qual o tráfego é registrado. Se o tráfego não for de uma sublocalização, o registro exibirá um símbolo '-' para este campo. Tipo de dados em Parquet: STRING |
4 |
|
pkt-src-aws-service |
O nome do subconjunto de intervalos de endereços IP para o campo pkt-srcaddr, se o endereço IP de origem for para um serviço da AWS. Os valores possíveis são: AMAZON | AMAZON_APPFLOW | AMAZON_CONNECT | API_GATEWAY | CHIME_MEETINGS | CHIME_VOICECONNECTOR | CLOUD9 | CLOUDFRONT | CODEBUILD | DYNAMODB | EBS | EC2 | EC2_INSTANCE_CONNECT | GLOBALACCELERATOR | KINESIS_VIDEO_STREAMS | ROUTE53 | ROUTE53_HEALTHCHECKS | ROUTE53_HEALTHCHECKS_PUBLISHING | ROUTE53_RESOLVER | S3 | WORKSPACES_GATEWAYS. Tipo de dados em Parquet: STRING |
5 |
|
pkt-dst-aws-service |
O nome do subconjunto de intervalos de endereços IP para o campo pkt-dstaddr, se o endereço IP de destino for para um serviço da AWS. Para uma lista de valores possíveis, consulte o campo pkt-src-aws-service. Tipo de dados em Parquet: STRING |
5 |
|
flow-direction |
O sentido do fluxo em relação à interface onde o tráfego é capturado. Os valores possíveis são: ingress | egress. Tipo de dados em Parquet: STRING |
5 |
|
traffic-path |
O trajeto que o tráfego de saída leva ao destino. Para determinar se o tráfego é de saída, verifique o campo flow-direction. Os valores possíveis são conforme o seguintes. Se nenhum dos valores se aplicar, o campo será definido como -.
Tipo de dados em Parquet: INT_32 |
5 |
Limitações do log de fluxo
Para usar logs de fluxo, você precisa estar atento às seguintes limitações:
-
Você não pode habilitar logs de fluxo para VPCs emparelhadas com a sua VPC, a menos que a VPC emparelhada esteja em sua conta.
-
Depois de criar um log de fluxo, não é possível alterar sua configuração ou o formato do registro de log de fluxo. Por exemplo, não é possível associar uma função do IAM diferente ao log de fluxo, nem adicionar ou remover campos no registro do log de fluxo. Em vez disso, você pode excluir o log de fluxo e criar um novo com a configuração necessária.
-
Se sua interface de rede tiver vários endereços IPv4 e o tráfego for enviado para um endereço IPv4 privado secundário, o log de fluxo exibirá o endereço IPv4 privado primário no campo
dstaddr. Para capturar o endereço IP de destino original, crie um log de fluxo com o campopkt-dstaddr. -
Se o tráfego for enviado para uma interface de rede e o destino não for nenhum dos endereços IP da interface de rede, o log de fluxo exibirá o endereço IPv4 privado principal no campo
dstaddr. Para capturar o endereço IP de destino original, crie um log de fluxo com o campopkt-dstaddr. -
Se o tráfego for enviado de uma interface de rede e a origem não for nenhum dos endereços IP da interface de rede, o log de fluxo exibirá o endereço IPv4 privado principal no campo
srcaddr. Para capturar o endereço IP de origem original, crie um log de fluxo com o campopkt-srcaddr. -
Se o tráfego for enviado para ou de uma interface de rede, os campos
srcaddredstaddrno log de fluxo sempre exibirão o endereço IPv4 privado primário, independentemente da origem ou destino do pacote. Para capturar a origem ou o destino do pacote, crie um log de fluxo com os campospkt-srcaddrepkt-dstaddr. -
Quando uma interface de rede é anexada a uma instância baseada em Nitro, o intervalo de agregação é sempre 1 minuto ou menos, independentemente do intervalo de agregação máximo especificado.
Os logs de fluxo não capturam todo o tráfego de IP. Os tipos de tráfego a seguir não são registrados:
-
O tráfego gerado por instâncias quando elas entram em contato com o servidor de DNS da Amazon. Se você usar seu próprio servidor de DNS, todo tráfego para esse servidor de DNS será registrado.
-
O tráfego gerado por uma instância Windows para ativação de licença do Amazon Windows.
-
O tráfego para e proveniente de
169.254.169.254para metadados de instância. -
O tráfego para e proveniente de
169.254.169.123para o Amazon Time Sync Service. -
Tráfego DHCP.
-
Tráfego espelhado.
-
Tráfego para o endereço IP reservado para o router padrão da VPC.
-
Trafegue entre uma interface de rede do endpoint e uma interface de rede do Network Load Balancer.
Definição de preço
As cobranças de ingestão e de arquivamento de dados para logs fornecidos se aplicam quando você publica logs de fluxo. Para obter mais informações sobre preços ao publicar logs fornecidos, abra Amazon CloudWatch Pricing
Para rastrear cobranças da publicação de logs de fluxo, você pode aplicar tags de alocação de custos ao recurso de destino. Em seguida, o relatório de alocação de custos da AWS incluirá o uso e os custos agregados por essas tags. É possível aplicar tags que representem categorias de negócios (como centros de custos, nomes de aplicativos ou proprietários) para organizar os custos. Para mais informações, consulte:
-
Usar tags de alocação de custos no Guia do usuário do AWS Billing.
-
Tag log groups in Amazon CloudWatch Logs (Marcar grupos de logs no Amazon CloudWatch Logs) no Amazon CloudWatch Logs User Guide (Guia do usuário do Amazon CloudWatch Logs)
-
Using cost allocation S3 bucket tags (Usar tags de alocação de custos para buckets do S3) no Amazon Simple Storage Service User Guide (Guia do usuário do Amazon Simple Storage Service)
-
Marcar fluxos de entrega no Guia do desenvolvedor do Amazon Data Firehose
