查询和扫描数据的最佳实践
本节介绍在 Amazon DynamoDB 中使用 Query 和 Scan 操作的一些最佳实践。
扫描性能注意事项
通常 Scan 操作效率低于 DynamoDB 中的其他操作。Scan 操作始终扫描整个表或二级索引,然后加入从结果集移除数据的步骤,筛选值以提供所需的结果。
如果可行,应避免对大型表或索引使用通过筛选器移除大量结果的 Scan 操作。此外,随着表或索引的增长,Scan 操作速度减慢。Scan 操作检查每个项目的请求值,可以在单个操作中用完大型表或索引的预置吞吐量。要缩短响应时间,请设计表和索引,使应用程序可以使用 Query 而不是 Scan。(对于表,还可以考虑使用 GetItem 和 BatchGetItem API。)
或者,您可以设计应用程序,以尽可能降低对请求速率的影响的方式使用 Scan 操作。这可能包括在使用全局二级索引(而不是 Scan 操作)可能更高效的情况下进行建模。有关此过程的更多信息,请参阅以下视频。
避免读取操作的突然峰值
创建表时,设置读取和写入容量单位要求。对于读取,容量单位表示为每秒的强一致性 4KB 数据读取请求数量。对于最终一致性读取,一个读取容量单位为每秒两个 4KB 读取请求。Scan 操作默认执行最终一致性读取,最多可以返回 1 MB(一页)数据。因此,单个 Scan 请求可以占用(1 MB 页面大小/4KB 项目大小)/2(最终一致性读取)= 128 个读取操作。如果请求强一致性读取,则 Scan 操作将占用两倍预置吞吐量 — 256 个读取操作。
这说明相比为表配置的读取容量,使用量突然猛增。扫描的这种容量单位使用方式,阻止对同一表的其他潜在更重要请求使用可用容量单位。因此此类请求可能将得到 ProvisionedThroughputExceeded 异常。
问题不仅在于 Scan 使用的容量单位突然增加,还可能占用同一分区的所有容量单位,因为扫描请求读取分区上彼此相邻的项目。这意味着请求命中同一分区,导致其所有容量单位被占用,限制对该分区的其他请求。如果读取数据的请求分布在多个分区,则操作不会限制特定分区。
下图说明 Query 和 Scan 操作使用的容量单位突然峰值造成的影响,以及对同一表的其他请求的影响。
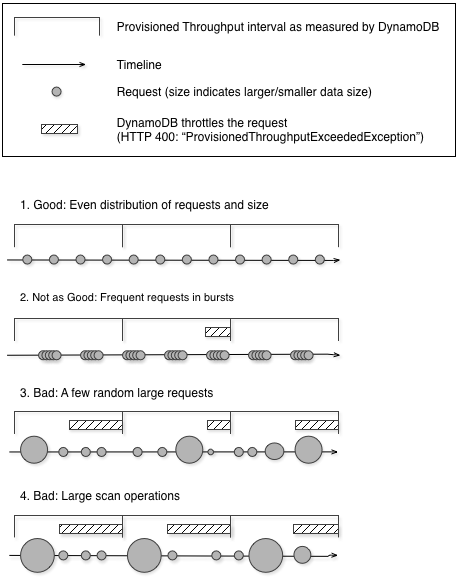
如下所示,使用峰值可以通过以下几种方式影响表的预置吞吐量:
-
良好:均匀分布请求和大小
-
不够好:频繁请求突发
-
坏:少数随机大请求
-
坏:大型扫描操作
可以用以下技术代替大型 Scan 操作,尽可能减小扫描对表预置吞吐量的影响。
-
减小页面大小
Scan 操作读取整个页面(默认 1 MB),可以设置更小的页面大小,减小扫描操作的影响。
Scan操作提供一个限制参数,可以用于设置请求的页面大小。每个具有更小页面大小的Query或Scan请求使用更少读取操作,在每个请求之间产生“暂停”。例如,假设每个项目为 4 KB,将页面大小设置为 40 个项目。Query请求将只占用 20 个最终一致性读取操作或 40 个强一致性读取操作。更多的较小Query或Scan操作将允许其他关键请求成功执行,不受限制。 -
隔离扫描操作
DynamoDB 专为轻松扩展而设计。因此,应用程序可以为不同目的创建表,甚至在多个表中重复内容。您希望在表上执行不占用“关键任务”流量的扫描。一些应用程序在两个表之间每小时轮换流量来处理此负载 — 一个用于关键流量,另一个用于记账。其他应用程序在两个表上执行每次写入:“任务关键型”表和“影子”表。
配置应用程序,如果请求接收的响应代码指示超出预置吞吐量,则重试。或者,使用 UpdateTable 操作增加表的预置吞吐量。如果工作负载临时峰值导致吞吐量偶尔超过预配量,则用指数回退重试请求。有关实施指数回退的更多信息,请参阅 错误重试和指数回退。
利用并行扫描
相比顺序扫描,许多应用程序都可以从使用并行 Scan 操作获益。例如,处理大型历史数据表的应用程序执行并行扫描的速度比顺序扫描要快得多。后台“sweeper”进程的多个工作线程以低优先级扫描表,不影响生产流量。在这些示例中,使用并行 Scan,不占用其他应用程序的预置吞吐量资源。
虽然并行扫描有自己的优势,但对预置吞吐量要求很高。使用并行扫描时,应用程序的多个工作线程同时运行 Scan 操作,快速消耗表的所有预置读取容量。在此情况下,需要访问表的其他应用程序可能会受到限制。
如果满足以下条件,可以选择并行扫描:
表大小为 20 GB 或更大。
未充分利用表的预置读取吞吐量。
顺序
Scan操作太慢。
选择 TotalSegments
TotalSegments 的最佳设置取决于具体数据、表的预置吞吐量设置以及性能要求。可能需要实验来得出正确设置。我们建议从简单比值开始,如每 2 GB 数据一个段。例如,对于 30 GB 表,可以将 TotalSegments 设置为 15(30 GB/2 GB)。应用程序将使用 15 个工作线程,每个工作线程扫描一个不同的段。
还可以根据客户端资源选择 TotalSegments 值。可以将 TotalSegments 设置为 1 到 1000000 之间的任意数字,DynamoDB 支持扫描这个数量的段。例如,如果客户端限制可同时运行的线程数量,可以逐渐增加 TotalSegments 直到应用程序达到最佳 Scan 性能。
监测并行扫描以优化预置吞吐量使用,同时确保其他应用程序不会耗尽资源。如果没有占用所有预配置吞吐量,但 Scan 请求仍遇到限制,增加 TotalSegments 值。如果 Scan 请求占用的预置吞吐量超过要使用的量,减少 TotalSegments 值。
