io/aurora_redo_log_flush
The io/aurora_redo_log_flush event occurs when a session is writing
persistent data to Amazon Aurora storage.
Supported engine versions
This wait event information is supported for the following engine versions:
-
Aurora MySQL version 2
Context
The io/aurora_redo_log_flush event is for a write input/output (I/O) operation in Aurora MySQL.
Note
In Aurora MySQL version 3, this wait event is named io/redo_log_flush.
Likely causes of increased waits
For data persistence, commits require a durable write to stable storage. If the
database is doing too many commits, there is a wait event on the write I/O operation,
the io/aurora_redo_log_flush wait event.
In the following examples, 50,000 records are inserted into an Aurora MySQL DB cluster using the db.r5.xlarge DB instance class:
-
In the first example, each session inserts 10,000 records row by row. By default, if a data manipulation language (DML) command isn't within a transaction, Aurora MySQL uses implicit commits. Autocommit is turned on. This means that for each row insertion there is a commit. Performance Insights shows that the connections spend most of their time waiting on the
io/aurora_redo_log_flushwait event.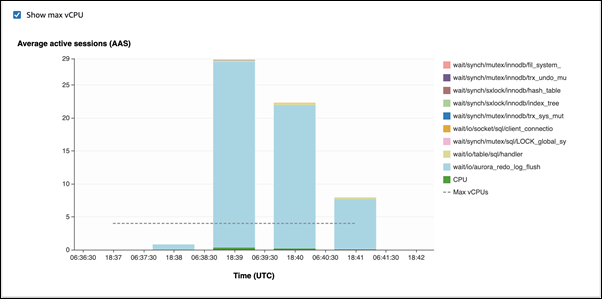
This is caused by the simple insert statements used.
The 50,000 records take 3.5 minutes to be inserted.
-
In the second example, inserts are made in 1,000 batches, that is each connection performs 10 commits instead of 10,000. Performance Insights shows that the connections don't spend most of their time on the
io/aurora_redo_log_flushwait event.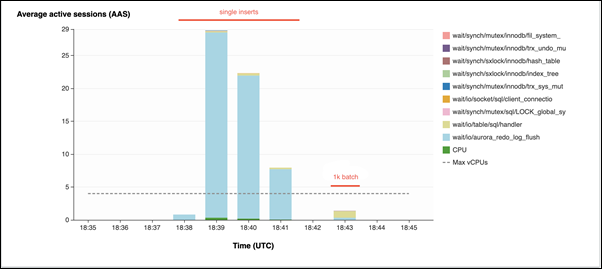
The 50,000 records take 4 seconds to be inserted.
Actions
We recommend different actions depending on the causes of your wait event.
Topics
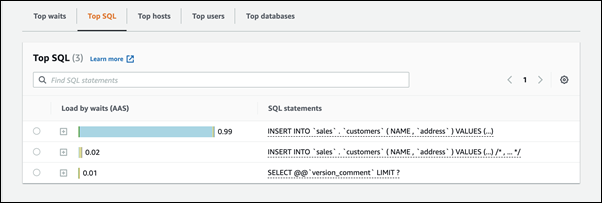
Identify the problematic sessions and queries
If your DB instance is experiencing a bottleneck, your first task is to find the sessions and queries that
cause it. For a useful AWS Database Blog post, see Analyze Amazon Aurora
MySQL Workloads with Performance Insights
To identify sessions and queries causing a bottleneck
Sign in to the AWS Management Console and open the Amazon RDS console at https://console.aws.amazon.com/rds/
. -
In the navigation pane, choose Performance Insights.
-
Choose your DB instance.
-
In Database load, choose Slice by wait.
-
At the bottom of the page, choose Top SQL.
The queries at the top of the list are causing the highest load on the database.
Group your write operations
The following examples trigger the io/aurora_redo_log_flush wait
event. (Autocommit is turned on.)
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE id=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx;
To reduce the time spent waiting on the io/aurora_redo_log_flush wait event, group your write operations
logically into a single commit to reduce persistent calls to storage.
Turn off autocommit
Turn off autocommit before making large changes that aren't within a transaction, as shown in the following example.
SET SESSION AUTOCOMMIT=OFF; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; .... UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1=xx; -- Other DML statements here COMMIT; SET SESSION AUTOCOMMIT=ON;
Use transactions
You can use transactions, as shown in the following example.
BEGIN INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); .... INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'); DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; .... DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1=xx; -- Other DML statements here END
Use batches
You can make changes in batches, as shown in the following example. However, using batches that are too large can cause performance issues, especially in read replicas or when doing point-in-time recovery (PITR).
INSERT INTO `sampleDB`.`sampleTable` (sampleCol2, sampleCol3) VALUES ('xxxx','xxxxx'),('xxxx','xxxxx'),...,('xxxx','xxxxx'),('xxxx','xxxxx'); UPDATE `sampleDB`.`sampleTable` SET sampleCol3='xxxxx' WHERE sampleCol1 BETWEEN xx AND xxx; DELETE FROM `sampleDB`.`sampleTable` WHERE sampleCol1<xx;
