Creating a multiserver assessment report in AWS Schema Conversion Tool
To determine the best target direction for your overall environment, create a multiserver assessment report.
A multiserver assessment report evaluates multiple servers based on input that you provide for each schema definition that you want to assess. Your schema definition contains database server connection parameters and the full name of each schema. After assessing each schema, AWS SCT produces a summary, aggregated assessment report for database migration across your multiple servers. This report shows the estimated complexity for each possible migration target.
You can use AWS SCT to create a multiserver assessment report for the following source and target databases.
| Source database | Target database |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Azure SQL Database |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Azure Synapse Analytics |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 for z/OS |
Amazon Aurora MySQL-Compatible Edition (Aurora MySQL), Amazon Aurora PostgreSQL-Compatible Edition (Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM Db2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish for Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
Performing a multiserver assessment
Use the following procedure to perform a multiserver assessment with AWS SCT. You don't need to create a new project in AWS SCT to perform a multiserver assessment. Before you get started, make sure that you have prepared a comma-separated value (CSV) file with database connection parameters. Also, make sure that you have installed all required database drivers and set the location of the drivers in the AWS SCT settings. For more information, see Installing JDBC drivers for AWS Schema Conversion Tool.
To perform a multiserver assessment and create an aggregated summary report
-
In AWS SCT, choose File, New multiserver assessment. The New multiserver assessment dialog box opens.
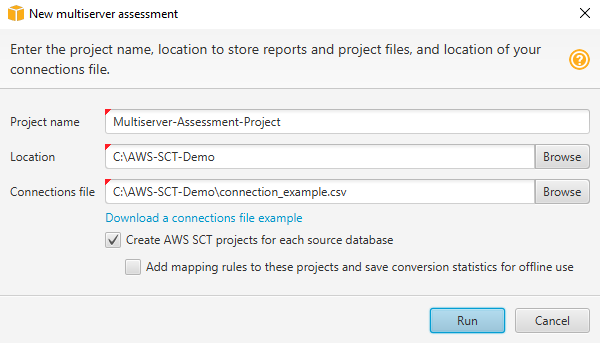
-
Choose Download a connections file example to download an empty template of a CSV file with database connection parameters.
-
Enter values for Project name, Location (to store reports), and Connections file (a CSV file).
-
Choose Create AWS SCT projects for each source database to automatically create migration projects after generating the assessment report.
-
With the Create AWS SCT projects for each source database turned on, you can choose Add mapping rules to these projects and save conversion statistics for offline use. In this case, AWS SCT will add mapping rules to each project and save the source database metadata in the project. For more information, see Using offline mode in AWS Schema Conversion Tool.
-
Choose Run.
A progress bar appears indicating the pace of database assessment. The number of target engines can affect the assessment runtime.
-
Choose Yes if the following message is displayed: Full analysis of all Database servers may take some time. Do you want to proceed?
When the multiserver assessment report is done, a screen appears indicating so.
-
Choose Open Report to view the aggregated summary assessment report.
By default, AWS SCT generates an aggregated report for all source databases and a detailed assessment report for each schema name in a source database. For more information, see Locating and viewing reports.
With the Create AWS SCT projects for each source database option turned on, AWS SCT creates an empty project for each source database. AWS SCT also creates assessment reports as described earlier. After you analyze these assessment reports and choose migration destination for each source database, add target databases to these empty projects.
With the Add mapping rules to these projects and save conversion statistics for offline use option turned on, AWS SCT creates a project for each source database. These projects include the following information:
Your source database and a virtual target database platform. For more information, see Mapping to virtual targets in the AWS Schema Conversion Tool.
A mapping rule for this source-target pair. For more information, see Data type mapping.
A database migration assessment report for this source-target pair.
Source schema metadata, which enables you to use this AWS SCT project in an offline mode. For more information, see Using offline mode in AWS Schema Conversion Tool.
Preparing an input CSV file
To provide connection parameters as input for multiserver assessment report, use a CSV file as shown in the following example.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
The preceding example uses a semicolon to separate the two schema names for the
Sales database. It also uses a semicolon to separate the two target
database migration platforms for the Sales database.
Also, the preceding example uses AWS Secrets Manager to connect to the Customers
database and Windows Authentication to connect to the HR database.
You can create a new CSV file or download a template for a CSV file from AWS SCT and fill in the required information. Make sure that the first row of your CSV file includes the same column names as shown in the preceding example.
To download a template of the input CSV file
Start AWS SCT.
Choose File, then choose New multiserver assessment.
Choose Download a connections file example.
Make sure that your CSV file includes the following values, provided by the template:
-
Name – The text label that helps identify your database. AWS SCT displays this text label in the assessment report.
-
Description – An optional value, where you can provide additional information about the database.
-
Secret Manager Key – The name of the secret that stores your database credentials in the AWS Secrets Manager. To use Secrets Manager, make sure that you store AWS profiles in AWS SCT. For more information, see Configuring AWS Secrets Manager in the AWS Schema Conversion Tool.
Important
AWS SCT ignores the Secret Manager Key parameter if you include Server IP, Port, Login, and Password parameters in the input file.
-
Server IP – The Domain Name Service (DNS) name or IP address of your source database server.
-
Port – The port used to connect to your source database server.
-
Service Name – If you use a service name to connect to your Oracle database, the name of the Oracle service to connect to.
-
Database name – The database name. For Oracle databases, use the Oracle System ID (SID).
-
BigQuery path – the path to the service account key file for your source BigQuery database. For more information about creating this file, see Privileges for BigQuery as a source.
-
Source Engine – The type of your source database. Use one of the following values:
AZURE_MSSQL for an Azure SQL Database.
AZURE_SYNAPSE for an Azure Synapse Analytics database.
GOOGLE_BIGQUERY for a BigQuery database.
DB2ZOS for an IBM Db2 for z/OS database.
DB2LUW for an IBM Db2 LUW database.
GREENPLUM for a Greenplum database.
MSSQL for a Microsoft SQL Server database.
MYSQL for a MySQL database.
NETEZZA for a Netezza database.
ORACLE for an Oracle database.
POSTGRESQL for a PostgreSQL database.
REDSHIFT for an Amazon Redshift database.
SNOWFLAKE for a Snowflake database.
SYBASE_ASE for an SAP ASE database.
TERADATA for a Teradata database.
VERTICA for a Vertica database.
-
Schema Names – The names of the database schemas to include in the assessment report.
For Azure SQL Database, Azure Synapse Analytics, BigQuery, Netezza, SAP ASE, Snowflake, and SQL Server, use the following format of the schema name:
db_name.schema_nameReplace
db_nameReplace
schema_nameEnclose database or schema names that include a dot in double quotation marks as shown following:
"database.name"."schema.name".Separate multiple schema names by using semicolons as shown following:
Schema1;Schema2.The database and schema names are case-sensitive.
Use the percent (
%) as a wildcard to replace any number of any symbols in the database or schema name. The preceding example uses the percent (%) as a wildcard to include all schemas from theemployeesdatabase in the assessment report. -
Use Windows Authentication – If you use Windows Authentication to connect to your Microsoft SQL Server database, enter true. For more information, see Using Windows Authentication when using Microsoft SQL Server as a source.
-
Login – The user name to connect to your source database server.
-
Password – The password to connect to your source database server.
-
Use SSL – If you use Secure Sockets Layer (SSL) to connect to your source database, enter true.
-
Trust store – The trust store to use for your SSL connection.
-
Key store – The key store to use for your SSL connection.
-
SSL authentication – If you use SSL authentication by certificate, enter true.
-
Target Engines – The target database platforms. Use the following values to specify one or more targets in the assessment report:
AURORA_MYSQL for an Aurora MySQL-Compatible database.
AURORA_POSTGRESQL for an Aurora PostgreSQL-Compatible database.
BABELFISH for a Babelfish for Aurora PostgreSQL database.
MARIA_DB for a MariaDB database.
MSSQL for a Microsoft SQL Server database.
MYSQL for a MySQL database.
ORACLE for an Oracle database.
POSTGRESQL for a PostgreSQL database.
REDSHIFT for an Amazon Redshift database.
Separate multiple targets by using semicolons like this:
MYSQL;MARIA_DB. The number of targets affects the time it takes to run the assessment.
Locating and viewing reports
The multiserver assessment generates two types of reports:
-
An aggregated report of all source databases.
-
A detailed assessment report of target databases for each schema name in a source database.
Reports are stored in the directory that you chose for Location in the New multiserver assessment dialog box.
To access the detailed reports, you can navigate the subdirectories, which are organized by source database, schema name, and target database engine.
Aggregated reports show information in four columns about conversion complexity of a target database. The columns include information about conversion of code objects, storage objects, syntax elements, and conversion complexity.
The following example shows information for conversion of two Oracle database schemas to Amazon RDS for PostgreSQL.

The same four columns are appended to the reports for each additional target database engine specified.
For details on how to read this information, see following.
Output for an aggregated assessment report
The aggregated multiserver database migration assessment report in AWS Schema Conversion Tool is a CSV file with the following columns:
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
To gather information, AWS SCT runs full assessment reports and then aggregates reports by schemas.
In the report, the following three fields show the percentage of possible automatic conversion based on the assessment:
- Code object conversion %
-
The percentage of code objects in the schema that AWS SCT can convert automatically or with minimal change. Code objects include procedures, functions, views, and similar.
- Storage object conversion %
-
The percentage of storage objects that SCT can convert automatically or with minimal change. Storage objects include tables, indexes, constraints, and similar.
- Syntax elements conversion %
-
The percentage of syntax elements that SCT can convert automatically. Syntax elements include
SELECT,FROM,DELETE, andJOINclauses, and similar.
The conversion complexity calculation is based on the notion of action items. An action item reflects a type of problem found in source code that you need to fix manually during migration to a particular target. An action item can have multiple occurrences.
A weighted scale identifies the level of complexity for performing a migration. The number 1 represents the lowest level of complexity, and the number 10 represents the highest level of complexity.
