Routing strategies in DynamoDB
Perhaps the most complex piece of a global table deployment is managing request routing. Requests must first go from an end user to a Region that’s chosen and routed in some manner. The request encounters some stack of services in that Region, including a compute layer that perhaps consists of a load balancer backed by an AWS Lambdafunction, container, or Amazon Elastic Compute Cloud (Amazon EC2) node, and possibly other services including another database. That compute layer communicates with DynamoDB It should do that by using the local endpoint for that Region. The data in the global table replicates to all other participating Regions, and each Region has a similar stack of services around its DynamoDB table.
The global table provides each stack in the various Regions with a local copy of the same data. You might consider designing for a single stack in a single Region and anticipate making remote calls to a secondary Region’s DynamoDB endpoint if there’s an issue with the local DynamoDB table. This is not best practice. If there’s an issue in one Region that’s caused by DynamoDB (or, more likely, caused by something else in the stack or by another service that depends on DynamoDB), it’s best to route the end user to another Region for processing and use that other Region’s compute layer, which will talk to its local DynamoDB endpoint. This approach routes around the problematic Region entirely. To ensure resiliency, you need replication across multiple Regions: replication of the compute layer as well as the data layer.
There are numerous alternative techniques to route an end user request to a Region for processing. The optimum choice depends on your write mode and your failover considerations. This section discusses four options: client-driven, compute-layer, Route 53, and Global Accelerator.
Client-driven request routing
With client-driven request routing, illustrated in the following diagram, the end user client (an application, a web page with JavaScript, or another client) keeps track of the valid application endpoints (for example, an Amazon API Gateway endpoint rather than a literal DynamoDB endpoint) and uses its own embedded logic to choose the Region to communicate with. It might choose based on random selection, lowest observed latencies, highest observed bandwidth measurements, or locally performed health checks.
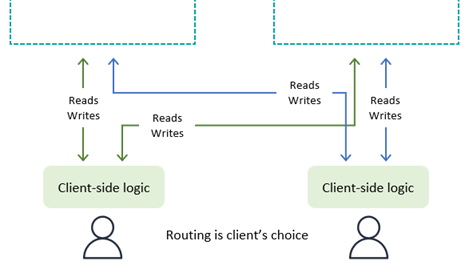
As an advantage, client-driven request routing can adapt to things such as real-world public internet traffic conditions to switch Regions if it notices any degraded performance. The client must be aware of all potential endpoints, but launching a new Regional endpoint is not a frequent occurrence.
With write to any Region mode, a client can unilaterally select its preferred endpoint. If its access to one Region becomes impaired, the client can route to another endpoint.
With the write to one Region mode, the client will need a mechanism to route its writes to the currently active region. This could be as basic as empirically testing which region is presently accepting writes (noting any write rejections and falling back to an alternate) or as complex as calling a global coordinator to query for the current application state (perhaps built on the Amazon Application Recovery Controller (ARC) (ARC) routing control which provides a 5-region quorum-driven system to maintain global state for needs such as this). The client can decide if reads can go to any Region for eventual consistency or must be routed to the active region for strong consistency. For further information see How Route 53 works.
With the write to your Region mode, the client needs to determine the home region for the data set it’s working against. For example, if the client corresponds to a user account and each user account is homed to a Region, the client can request the appropriate endpoint from a global login system.
For example, a financial services company that helps users manage their business finances via the web could use global tables with a write to your Region mode. Each user must login to a central service. That service returns credentials and the endpoint for the Region where those credentials will work. The credentials are valid for a short time. After that the webpage auto-negotiates a new login, which provides an opportunity to potentially redirect the user’s activity to a new Region.
Compute-layer request routing
With compute-layer request routing, illustrated in the following diagram, the code that runs in the compute layer determines whether to process the request locally or pass it to a copy of itself that’s running in another Region. When you use the write to one Region mode, the compute layer might detect that it’s not the active Region and allow local read operations while forwarding all write operations to another Region. This compute layer code must be aware of data topology and routing rules, and enforce them reliably, based on the latest settings that specify which Regions are active for which data. The outer software stack within the Region doesn’t have to be aware of how read and write requests are routed by the micro service. In a robust design, the receiving Region validates whether it is the current primary for the write operation. If it isn’t, it generates an error that indicates that the global state needs to be corrected. The receiving Region might also buffer the write operation for a while if the primary Region is in the process of changing. In all cases, the compute stack in a Region writes only to its local DynamoDB endpoint, but the compute stacks might communicate with one another.

The Vanguard Group uses a system called Global Orchestration and Status Tool (GOaST) and
a library called Global Multi-Region library (GMRlib) for this routing process, as presented
at re:Invent
2022
Route 53 request routing
Amazon Application Recovery Controller (ARC) is a Domain Name Service (DNS) technology. With Route 53, the client requests its endpoint by looking up a well-known DNS domain name, and Route 53 returns the IP address corresponding to the regional endpoint(s) it thinks most appropriate. This is illustrated in the following diagram. Route 53 has a long list of routing policies it uses to determine the appropriate Region. It also can do failover routing to route traffic away from Regions that fail health checks.
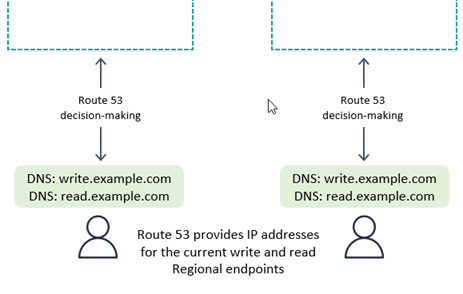
With write to any Region mode, or if combined with the compute-layer request routing on the backend, Route 53 can be given full access to return the Region based on any complex internal rules such as the Region in closest network proximity, or closest geographic proximity, or any other choice.
With write to one Region mode, you can configure Route 53 to return the currently active Region (using Route 53 ARC). If the client wants to connect to a passive Region (for example, for read operations), it could look up a different DNS name.
Note
Clients cache the IP addresses in the response from Route 53 for a time indicated by the time to live (TTL) setting on the domain name. A longer TTL extends the recovery time objective (RTO) for all clients to recognize the new endpoint. A value of 60 seconds is typical for failover use. Not all software perfectly adheres to DNS TTL expiration, and there might be multiple levels of DNS caching, such as at the operating system, virtual machine, and application.
With write to your Region mode, it’s best to avoid Route 53 unless you're also using compute-layer request routing.
Global Accelerator request routing
With AWS Global Accelerator
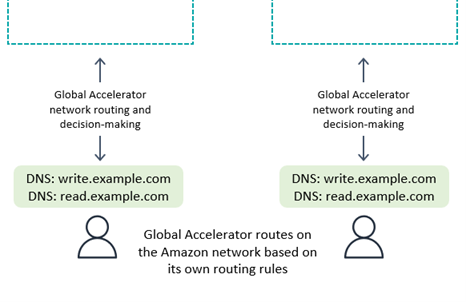
With write to any Region mode, or if combined with the compute-layer request routing on the back- end, Global Accelerator works seamlessly. The client connects to the nearest edge location and need not be concerned with which Region receives the request.
With write to one Region Global Accelerator routing rules must send requests to the currently active Region. You can use health checks that artificially report a failure on any Region that’s not considered by your global system to be the active Region. As with DNS, it’s possible to use an alternative DNS domain name for routing read requests if the requests can be from any Region.
With write to your Region mode, it’s best to avoid Global Accelerator unless you're also using compute-layer request routing.
