Using Global Secondary Indexes for materialized aggregation queries in DynamoDB
Maintaining near real-time aggregations and key metrics on top of rapidly changing data is becoming increasingly valuable to businesses for making rapid decisions. For example, a music library might want to showcase its most downloaded songs in near-real time.
Consider the following music library table layout:
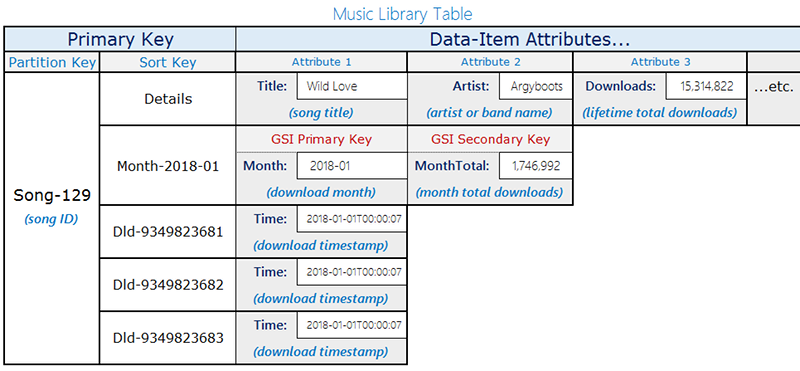
The table in this example stores songs with the songID as the partition key.
You can enable Amazon DynamoDB Streams on this table and attach a Lambda function to the streams so
that as each song is downloaded, an entry is added to the table with
Partition-Key=SongID and Sort-Key=DownloadID. As these updates are
made, they trigger a Lambda function in DynamoDB Streams. The Lambda function can aggregate and
group the downloads by songID and update the top-level item,
Partition-Key=songID, and Sort-Key=Month. Keep in mind that if a
lambda execution fails just after writing the new aggregated value, it may be retried and
aggregate the value more than once, leaving you with an approximate value.
To read the updates in near-real time, with single-digit millisecond latency, use the global
secondary index with query conditions Month=2018-01,
ScanIndexForward=False, Limit=1.
Another key optimization used here is that the global secondary index is a sparse index and is available only on the items that need to be queried to retrieve the data in real time. The global secondary index can serve additional workflows that need information on the top 10 songs that were popular, or any song downloaded in that month.
