Cataloging the data output from an Amazon AppFlow flow
When you use Amazon AppFlow to transfer data with a flow that meets certain requirements, you get the option to register the data with a data catalog. A data catalog is a metadata repository. The metadata represents aspects of your data, such as the schema, format, and data types. The metadata also includes business metadata, which consists of labels and descriptions that data users write to provide helpful context for themselves and other data users. A data catalog provides a unified view of your data, even if the data belongs to multiple datasets that reside in multiple locations. When you query the consolidated metadata in a data catalog, you can more quickly search and discover your data assets.
To catalog your data, you create flows that transfer to Amazon S3, and you configure these flows with the required settings. When the flows run, Amazon AppFlow creates metadata tables in the AWS Glue Data Catalog.
The AWS Glue Data Catalog is a component of the AWS Glue service. You can use the Data Catalog to discover and search your data assets across various locations, including S3 buckets. When you register your data with the Data Catalog, you can more quickly access it with many AWS analytics, AI, and ML services. These services include AWS Glue, Amazon Athena, Amazon SageMaker AI Data Wrangler, and more.
It's convenient to catalog your data with Amazon AppFlow for the following reasons:
-
You can transfer and catalog your data in the same operation.
-
You don't have to use crawlers to populate the Data Catalog.
When you run a flow that catalogs your data, Amazon AppFlow does the following in your AWS account:
-
Prepares the metadata that represents the data output of the flow
-
Writes the metadata to a Data Catalog table
-
Stores the table in a Data Catalog database
The Data Catalog table also includes any partition keys that organize your data in Amazon S3. For any flow that transfers data to Amazon S3, you can activate several types of partition keys in the flow settings. For more information, see Partitioning and aggregating data output from an Amazon AppFlow flow.
For more information about the Data Catalog, see AWS Glue Data Catalog in the AWS Glue Developer Guide.
Before you begin
Before you can catalog the data that you transfer with Amazon AppFlow, you must have a user role that you create with the AWS Identity and Access Management (IAM) service. This role grants Amazon AppFlow the permissions that it needs to create Data Catalog tables, databases, and partitions.
For an example IAM policy that has the required permissions, see Identity-based policy examples for Amazon AppFlow.
Cataloging flow output (Amazon AppFlow console)
To create a flow that catalogs data, complete the following steps in the Amazon AppFlow console.
Sign in to the AWS Management Console and open the Amazon AppFlow console at https://console.aws.amazon.com/appflow/
. -
To view the Data Catalog settings, configure a flow that transfers data to Amazon S3. Do one of the following:
-
If you want to catalog the data from a new flow, choose Create flow and step through the flow creation process.
When you get to the Configure flow page, under Destination details, set Destination name to Amazon S3.
-
If you want to catalog the data from an existing flow, choose Flows in the navigation pane to view your flows. Then, select the flow and choose Edit.
On the Edit flow configuration page, under Destination details, ensure that Destination name is set to Amazon S3.
-
-
To view the Data Catalog settings, expand the AWS Glue Data Catalog settings section, and select the Create a Data Catalog table check box.
-
Configure the following settings:
-
User role – The required IAM user role. If you haven't created this role yet, see Before you begin.
-
Database – A Data Catalog database where Amazon AppFlow stores the Data Catalog tables that it creates when your flow runs.
If you already have a database that you want to use, choose the Select existing database tab, and select the database.
Otherwise, choose the Create database tab and enter a name. Then, choose the Create database button, and Amazon AppFlow creates the database for you. Amazon AppFlow creates the database in AWS Glue in your AWS account in the selected AWS Region.
-
Table name prefix – A prefix that Amazon AppFlow prepends to the name of each Data Catalog table that Amazon AppFlow creates for the flow.
-
-
When you've configured the Data Catalog settings, do either of the following:
-
If you are creating a flow, work through the remaining flow creation steps in the console. For all of the steps to create a flow, see Create a flow using the AWS console.
-
If you are editing a flow, choose Save.
With this Data Catalog configuration, Amazon AppFlow stores metadata about the flow output each time that the flow runs. To view this metadata, open the AWS Glue console at https://console.aws.amazon.com/glue/
. In the AWS Glue console, you can choose Databases and Tables in the navigation pane to view the Data Catalog databases and tables that Amazon AppFlow creates. -
Data Catalog table names
Amazon AppFlow creates metadata tables in the Data Catalog in several different naming formats.
To query the latest data output from your flow, use the table with the name that appears in the following format:
-
prefix_appflow_flow-name_timestamp_latestAmazon AppFlow updates this table continuously with the metadata from the most recent flow run.
In this name,
timestampis the time when Amazon AppFlow created the table. The timestamp is formatted as a Unix epoch. For example, the timestamp for November 14, 2022 at 12:00:00 PM UTC is 1668456000.
To query historical versions of your data output, use the tables with names that appear in the following formats:
-
prefix_appflow_flow-name_schema-versionThese tables contain metadata for each schema version.
-
prefix_appflow_flow-name_schema-version_execution-idThese tables contain metadata from individual flow runs. Amazon AppFlow creates these tables only when you set Execution ID as a partition key in the flow settings.
The variable elements in these names are as follows:
-
prefix– The prefix that you specify in the flow settings. -
flow-name– The flow name. Amazon AppFlow modifies this name, if needed, to comply with table naming restrictions in the Data Catalog. -
schema-version– The version number of your data schema. Amazon AppFlow assigns this version number and increases it by one when you change any of the following settings for your flow:-
Field mappings
-
Field data types
-
Partition settings
-
-
execution-id— The ID that Amazon AppFlow assigns to a flow run. You can see these IDs in the run history for the flow.
Example Data Catalog output from a flow run
The following examples show how Amazon AppFlow creates metadata tables in the Data Catalog to catalog a dataset.
Example dataset
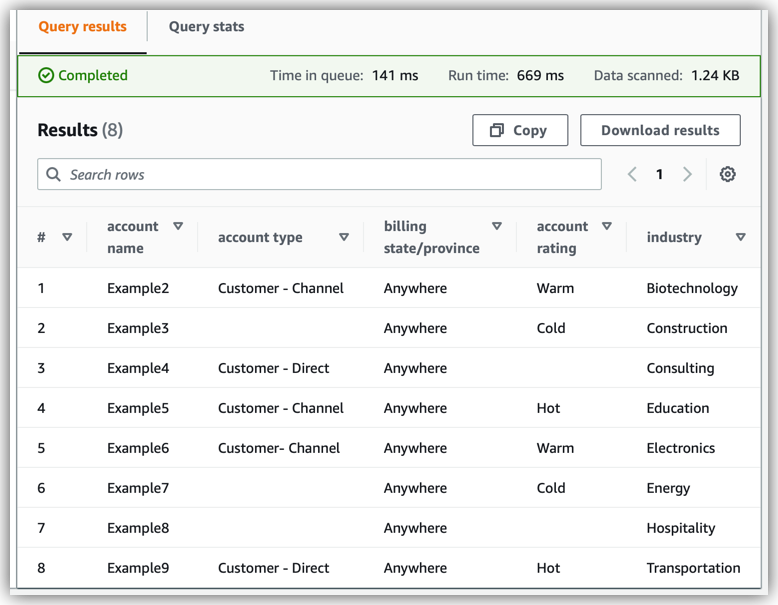
The following table represents an example dataset of account records from a Salesforce database. The dataset is the source data for a flow that transfers from Salesforce to Amazon S3.
Account Name |
Account Type |
Billing State/Province |
Account Rating |
Industry |
|---|---|---|---|---|
Example1 |
Customer - Direct |
Anywhere |
Hot |
Apparel |
Example2 |
Customer - Channel |
Anywhere |
Warm |
Biotechnology |
Example3 |
Anywhere |
Cold |
Construction |
|
Example4 |
Customer - Direct |
Anywhere |
Consulting |
|
Example5 |
Customer - Channel |
Anywhere |
Hot |
Education |
Example6 |
Customer- Channel |
Anywhere |
Warm |
Electronics |
Example7 |
Anywhere |
Cold |
Energy |
|
Example8 |
Anywhere |
Hospitality |
||
Example9 |
Customer - Direct |
Anywhere |
Hot |
Transportation |
Example flow configuration
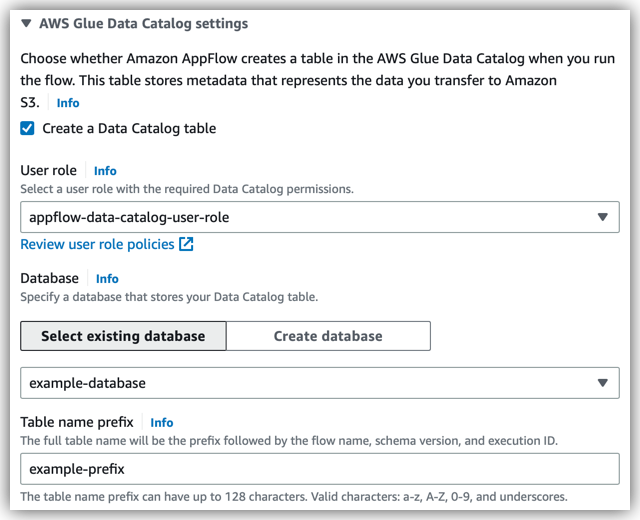
The flow that transfers the example dataset has the following configuration under AWS Glue Data Catalog settings in the console:
-
User role is set to
appflow-data-catalog-user-role. This is an example name for a role that grants the required permissions to Amazon AppFlow. -
Database is set to
example-database. -
Table name prefix is set to
example-prefix.
Example Data Catalog table
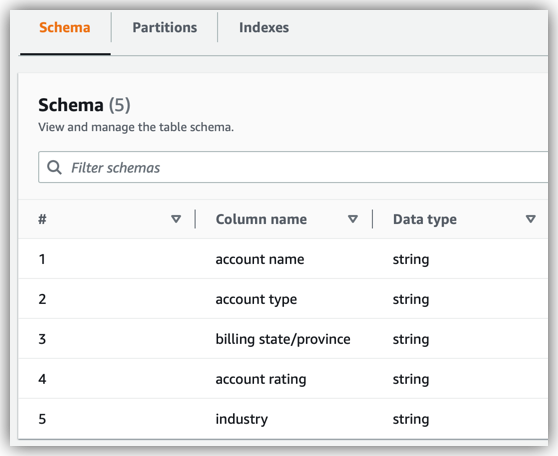
When the flow runs, Amazon AppFlow creates tables in the database named example-database. One of these tables is named example-prefix_appflow_exampleflow_1668036146_latest.Amazon AppFlow updates this table every time the flow runs. You can view the tables that Amazon AppFlow creates for your flows in the Data Catalog console.
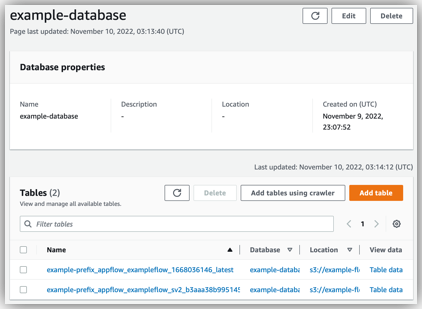
The Data Catalog console provides details pages for each table. Each page shows the metadata that a table stores, such as the columns and data types in the data schema. For more information, see Working with tables on the AWS Glue console in the AWS Glue Developer Guide.
While you're on a table details page, you can also view any business metadata that Amazon AppFlow
discovered in your source data. To view this data, open the table properties by choosing
Actions and then View properties. The table
properties JSON gives the business metadata as the values of the AppFlowLabel and
AppFlowDescription attributes.
Example Data Catalog table properties with business metadata from Amazon AppFlow
. . . "StorageDescriptor": { "Columns": [ { "Name": "id", "Type": "string", "Parameters": { "AppFlowLabel": "Account ID", "AppFlowDescription": "A unique identifier for the customer account." } }, . . .
You can search the cataloged dataset with data query tools and many AWS services. One way that you can query the data is to choose the Table data link on the database page in the Data Catalog console. That link opens Amazon Athena. This is an AWS service that runs SQL queries to help you analyze data in Amazon S3.
In Amazon Athena, the following SQL query retrieves the data that Amazon AppFlow catalogs in the example table:
SELECT * FROM "AwsDataCatalog"."example-database" ."example-prefix_appflow_exampleflow_1668036146_latest" limit 10;
The Amazon Athena console shows the data that the query retrieves.