Payor Strategic Focus Areas
Publication date: May 22, 2024 (Diagram history)
This set of reference architectures illustrates how payors can leverage advanced analytics and harness structured and unstructured healthcare data to enhance customer experiences, optimize resource allocation, and make informed decisions across the healthcare continuum. Additionally, the solution empowers payors to modernize and standardize healthcare data, enabling seamless integration of core payor systems, provider data, and healthcare content repositories.
Modernize Core Payor Functions Diagram
This reference architecture demonstrates how to connect core payor systems, standardize payor and provider data, and create a ready-to-go repository of healthcare content. The solution will enable healthcare companies to accelerate the digitization and modernization of healthcare data and achieve advanced insights into healthcare data at scale.
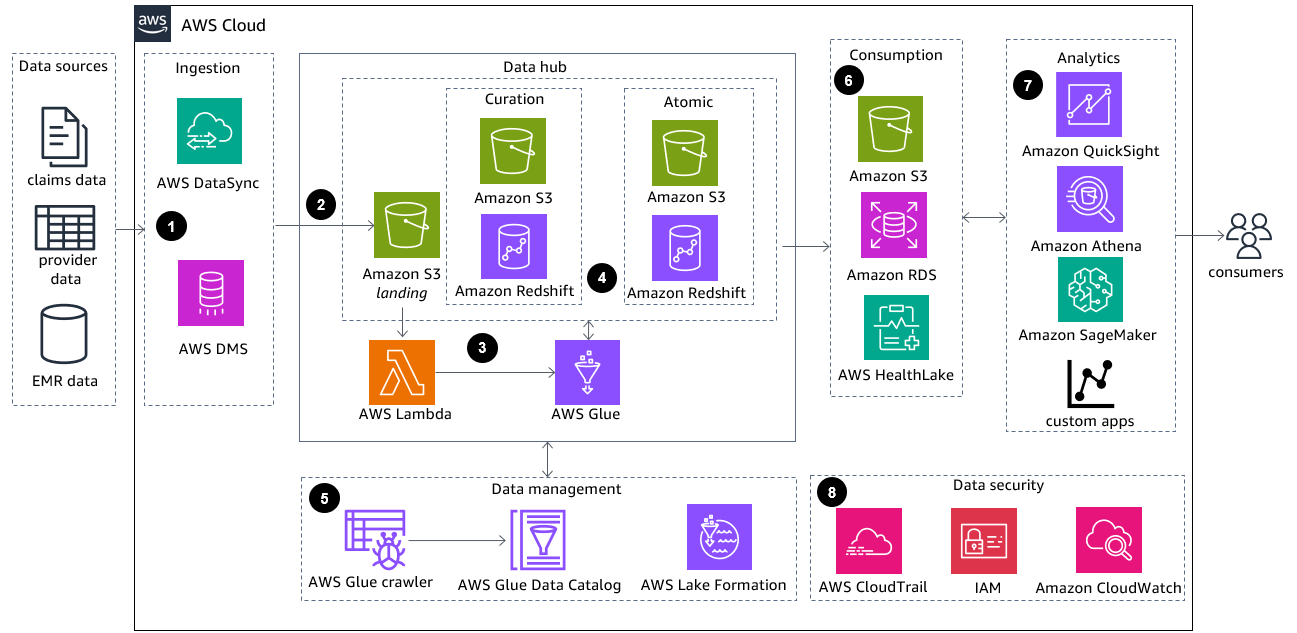
-
On-premises or cloud data sources are ingested in into the AWS Cloud using AWS DataSync
or AWS Database Migration Service (AWS DMS), depending on the type of source. Use DataSync for near real-time ingestion or AWS DMS for database migration. Ingestion requires secure connectivity with encryption in transit and at rest. -
The raw data is moved into a data hub landing zone and stored in the source format in Amazon Simple Storage Service
(Amazon S3). -
AWS Lambda
functions can be used to run shorter processing jobs that use less memory for data curation and referential integrity. They can also be used to initiate AWS Glue (Spark) jobs for data extract, transform, and load (ETL) processing. -
Data is cleansed and curated into Amazon Redshift
using standardization and data quality rules stored in a rules engine. Rules can be common across source data elements or plan-specific for extensibility. The atomic layer with all datasets should be checked for referential integrity and context applied where necessary. The curated and atomic levels use Amazon Redshift as the data store along with Amazon S3 for documents storage. -
Create business terms for data elements in the system. Link technical metadata to the business terms and capture and store lineage in the data catalog. An AWS Glue crawler interacts with data stores to populate AWS Glue Data Catalog, which contains reference to data that is used as source and targets for ETL jobs in AWS Glue. AWS Lake Formation
centralizes permissions management of your data and provides a single place to manage access controls and data governance across your organization. -
Data can be stored in a data warehouse for business intelligence (BI), RDS, or key/value store for faster access and blob store for bulk data consumption. Purpose-built data stores store curated data for downstream consumption. FHIR format data can be directly ingested into AWS HealthLake
; for relational and transaction data, use Amazon Relational Database Service (Amazon RDS); and for structured and semi-structured data at any large scale, use Amazon Redshift. For all the other datatypes, you can use Amazon S3. -
Query structured claims data and create data products that can be consumed by care management to provide more efficient operational analysis and improved clinical insights. Deploy analytical models, standard reports, and dashboards to visualize and study performance. Amazon Athena
can help you with direct queries analysis, data preparation for machine learning, and data reconciliation. Create visualization dashboards using Amazon QuickSight , then use Amazon SageMaker AI to build, train, and deploy machine learning models on the available data and integrate with custom application. End users include businesses, researchers, data scientists, and technical users. -
Data security, compliance, and governance is handled at the solution level by a set of purpose built-services. AWS Identity and Access Management
(IAM) provides security propagation across services and data is encrypted through AWS Key Management Service (AWS KMS). Amazon CloudWatch helps you monitor your solution's metrics, logs, and alarms. AWS CloudTrail helps to monitor access to AWS endpoints. For more security and monitoring options, see the AWS Security Decision Guide .
Advanced Analytics to Drive Business Value Diagram
This reference architecture enables access and delivery of person-centered care, drives improved outcomes at a lower cost, and accelerates the digitization and utilization of healthcare data. The solution is designed to help you harness complex structured and un-structured data on multiple determinants of health to inform clinical and community intervention.
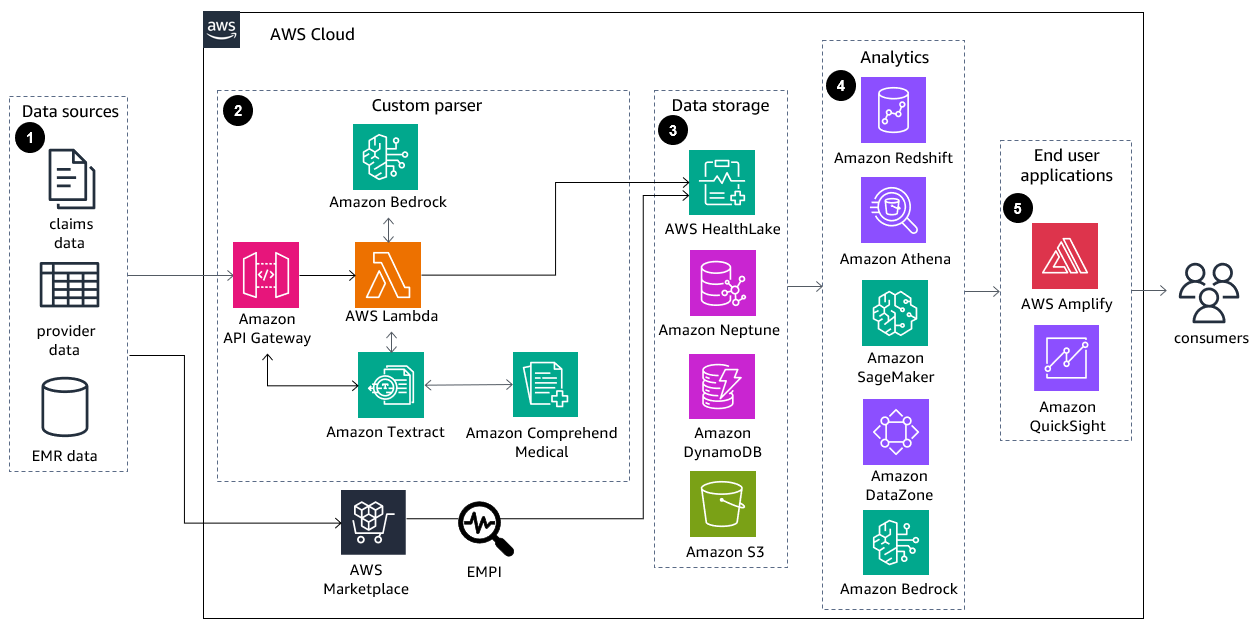
-
On-premises or cloud data sources are ingested in into AWS. Ingested data can be from any of the following data sources: clinical, claims, provider, and electronic medical records (EMR). Specific connectors will ingest different data types, such as HL7v2, FHIR, CCDA, X12, or semi-structured. Clinical large language models (LLMs) can be trained to convert data into FHIR for ingestion purposes. Data ingestion requires secure connectivity ensuring encryption at rest and in transit. Data ingestion can be streaming, near real time, or batch.
-
Data enrichment pipelines transform and normalize ingested data into a common data model. Syntactic parser and semantic harmonization components can be implemented using AWS services like Amazon Comprehend Medical
, Amazon Textract , and AWS Lambda. LLMs from Amazon Bedrock can be leveraged for data enrichment. This step ensures the data that is ingested into AWS HealthLake is in FHIR R4 format. Alternatively, AWS Partner solutions are available to implement data ingestion. For more details, refer to AWS HealthLake Partners
. You can bring your own identity and terminology services to assist with data harmonization (Employee Master Patient Index or EMPI). -
Purpose-built data stores will hydrate AWS HealthLake using common data models. You can also store data in graph databases like Amazon Neptune
, NoSQL databases like Amazon DynamoDB , or data lakes like Amazon Simple Storage Service (Amazon S3). -
Providers have access to patient population data in AWS HealthLake and generate business insights through Amazon Athena and Amazon Redshift. Amazon SageMaker AI can provide machine learning insights. Amazon Bedrock helps leverage LLMs to translate English queries into SQL FHIR queries. Amazon DataZone
can be leveraged to create data products and make them available in a catalog. -
Create dashboards using Amazon QuickSight (with Amazon Q
integration) and enhanced applications like longitudinal patient view through AWS Amplify .
Improve the Customer Experience Diagram
This reference architecture enables omni-channel engagement for customers. It provides a responsive, engaging, and personalized experience by combining data from care, disease, and utilization management systems and clinician contact centers to help agents make informed customer decisions.
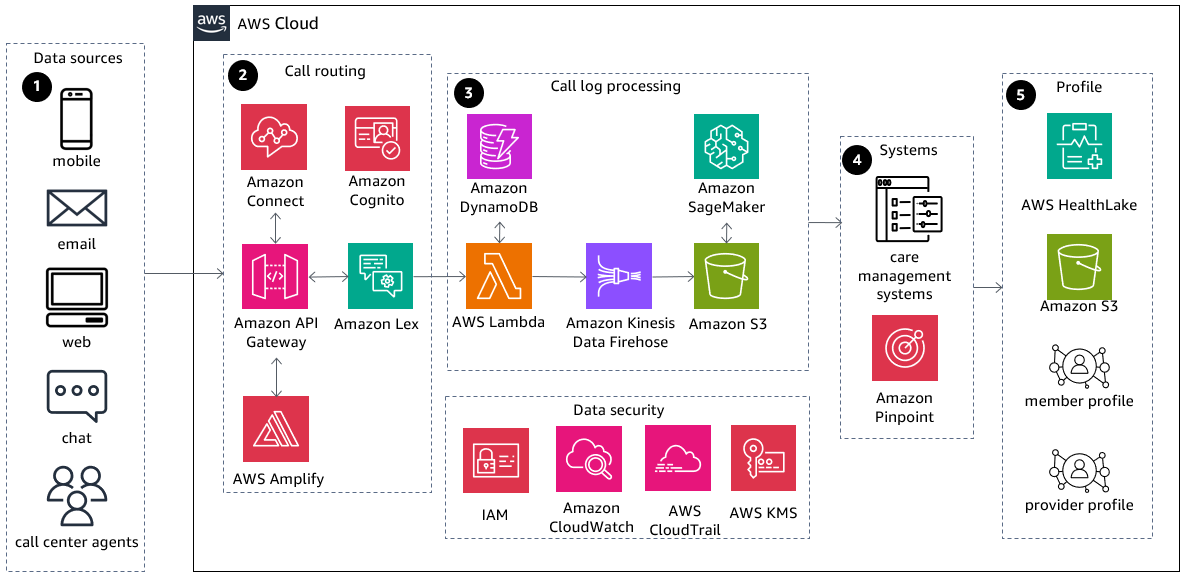
-
Callers dial through the main line or other channels and interact with the call center application. Data ingestion requires secure connectivity ensuring encryption at rest and in transit. Data can be streamed, near real-time for calls, or batch for offline communications.
-
Amazon Connect
routes calls while leveraging Amazon Lex for conversation and AWS Amplify for agent applications. Amazon Cognito provides security while Amazon API Gateway provides API-based access for call log analysis. -
Call logs are sent to AWS Lambda, which leverages Amazon Data Firehose
to ingest them into Amazon Simple Storage Service (Amazon S3). Amazon SageMaker AI analyzes the stored logs and determines next steps. AWS Identity and Access Management (IAM) provides security propagation across services and data is encrypted through AWS Key Management Service (AWS KMS). Amazon CloudWatch provides logging capabilities for data pipelines while AWS CloudTrail helps track API calls. -
Purpose-built AWS services connect to care management systems to get member information and Amazon Pinpoint
connects with customers through scalable, targeted, multi-channel communications. -
Member and provider profiles are enriched in real time from AWS HealthLake and Amazon S3 data lakes and passed to a care management system to decide the next best action and react to member calls.
Download editable diagram
To customize this reference architecture diagram based on your business needs, download the ZIP file which contains an editable PowerPoint.
Create a free AWS account

Sign up for an AWS account. New accounts include 12 months of AWS Free Tier
Further reading
For additional information, refer to
Diagram history
To be notified about updates to this reference architecture diagram, subscribe to the RSS feed.
| Change | Description | Date |
|---|---|---|
Initial publication | Reference architecture diagram first published. | May 22, 2024 |
Note
To subscribe to RSS updates, you must have an RSS plugin enabled for the browser you are using.
