Amazon Athena Vertica connector
Vertica is a columnar database platform that can be deployed in the cloud or on premises that supports exabyte scale data warehouses. You can use the Amazon Athena Vertica connector in federated queries to query Vertica data sources from Athena. For example, you can run analytical queries over a data warehouse on Vertica and a data lake in Amazon S3.
Prerequisites
Deploy the connector to your AWS account using the Athena console or the AWS Serverless Application Repository. For more information, see Deploying a data source connector or Using the AWS Serverless Application Repository to deploy a data source connector.
Set up a VPC and a security group before you use this connector. For more information, see Creating a VPC for a data source connector.
Limitations
-
Because the Athena Vertica connector uses Amazon S3 Select to read Parquet files from Amazon S3, performance of the connector can be slow. When you query large tables, we recommend that you use a CREATE TABLE AS (SELECT ...) query and SQL predicates.
-
Currently, due to a known issue in Athena Federated Query, the connector causes Vertica to export all columns of the queried table to Amazon S3, but only the queried columns are visible in the results on the Athena console.
-
Write DDL operations are not supported.
-
Any relevant Lambda limits. For more information, see Lambda quotas in the AWS Lambda Developer Guide.
Workflow
The following diagram shows the workflow of a query that uses the Vertica connector.
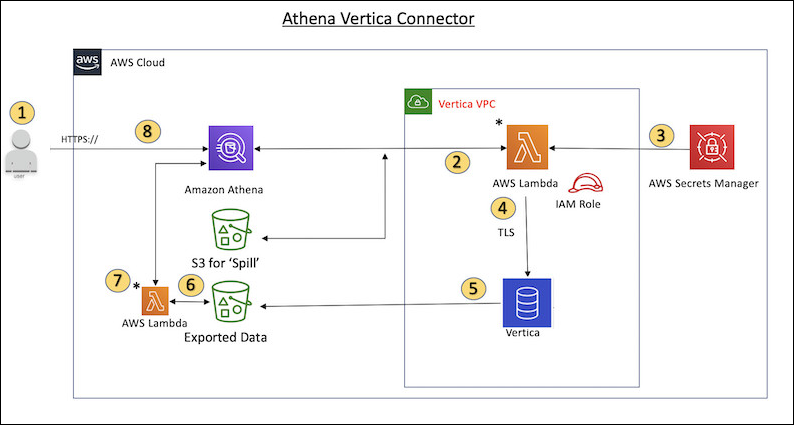
-
A SQL query is issued against one or more tables in Vertica.
-
The connector parses the SQL query to send the relevant portion to Vertica through the JDBC connection.
-
The connection strings use the user name and password stored in AWS Secrets Manager to gain access to Vertica.
-
The connector wraps the SQL query with a Vertica
EXPORTcommand, as in the following example.EXPORT TO PARQUET (directory = 's3://bucket_name/folder_name, Compression='Snappy', fileSizeMB=64) OVER() as SELECT PATH_ID, ... SOURCE_ITEMIZED, SOURCE_OVERRIDE FROM DELETED_OBJECT_SCHEMA.FORM_USAGE_DATA WHERE PATH_ID <= 5; -
Vertica processes the SQL query and sends the result set to an Amazon S3 bucket. For better throughput, Vertica uses the
EXPORToption to parallelize the write operation of multiple Parquet files. -
Athena scans the Amazon S3 bucket to determine the number of files to read for the result set.
-
Athena makes multiple calls to the Lambda function and uses Amazon S3 Select to read the Parquet files from the result set. Multiple calls enable Athena to parallelize the read of the Amazon S3 files and achieve a throughput of up to 100GB per second.
-
Athena processes the data returned from Vertica with data scanned from the data lake and returns the result.
Terms
The following terms relate to the Vertica connector.
-
Database instance – Any instance of a Vertica database deployed on Amazon EC2.
-
Handler – A Lambda handler that accesses your database instance. A handler can be for metadata or for data records.
-
Metadata handler – A Lambda handler that retrieves metadata from your database instance.
-
Record handler – A Lambda handler that retrieves data records from your database instance.
-
Composite handler – A Lambda handler that retrieves both metadata and data records from your database instance.
-
Property or parameter – A database property used by handlers to extract database information. You configure these properties as Lambda environment variables.
-
Connection String – A string of text used to establish a connection to a database instance.
-
Catalog – A non-AWS Glue catalog registered with Athena that is a required prefix for the
connection_stringproperty.
Parameters
The Amazon Athena Vertica connector exposes configuration options through Lambda environment variables. You can use the following Lambda environment variables to configure the connector.
-
AthenaCatalogName – Lambda function name
-
ExportBucket – The Amazon S3 bucket where the Vertica query results are exported.
-
SpillBucket – The name of the Amazon S3 bucket where this function can spill data.
-
SpillPrefix – The prefix for the
SpillBucketlocation where this function can spill data. -
SecurityGroupIds – One or more IDs that correspond to the security group that should be applied to the Lambda function (for example,
sg1,sg2, orsg3). -
SubnetIds – One or more subnet IDs that correspond to the subnet that the Lambda function can use to access your data source (for example,
subnet1, orsubnet2). -
SecretNameOrPrefix – The name or prefix of a set of names in Secrets Manager that this function has access to (for example,
vertica-*) -
VerticaConnectionString – The Vertica connection details to use by default if no catalog specific connection is defined. The string can optionally use AWS Secrets Manager syntax (for example,
${secret_name}). -
VPC ID – The VPC ID to be attached to the Lambda function.
Connection string
Use a JDBC connection string in the following format to connect to a database instance.
jdbc:vertica://host_name:port/database?user=vertica-username&password=vertica-password
Using a single connection handler
You can use the following single connection metadata and record handlers to connect to a single Vertica instance.
| Handler type | Class |
|---|---|
| Composite handler | VerticaCompositeHandler |
| Metadata handler | VerticaMetadataHandler |
| Record handler | VerticaRecordHandler |
Single connection handler parameters
| Parameter | Description |
|---|---|
default |
Required. The default connection string. |
The single connection handlers support one database instance and must provide a
default connection string parameter. All other connection
strings are ignored.
Providing credentials
To provide a user name and password for your database in your JDBC connection string, you can use connection string properties or AWS Secrets Manager.
-
Connection String – A user name and password can be specified as properties in the JDBC connection string.
Important
As a security best practice, do not use hardcoded credentials in your environment variables or connection strings. For information about moving your hardcoded secrets to AWS Secrets Manager, see Move hardcoded secrets to AWS Secrets Manager in the AWS Secrets Manager User Guide.
-
AWS Secrets Manager – To use the Athena Federated Query feature with AWS Secrets Manager, the VPC connected to your Lambda function should have internet access
or a VPC endpoint to connect to Secrets Manager. You can put the name of a secret in AWS Secrets Manager in your JDBC connection string. The connector replaces the secret name with the
usernameandpasswordvalues from Secrets Manager.For Amazon RDS database instances, this support is tightly integrated. If you use Amazon RDS, we highly recommend using AWS Secrets Manager and credential rotation. If your database does not use Amazon RDS, store the credentials as JSON in the following format:
{"username": "${username}", "password": "${password}"}
Example connection string with secret names
The following string has the secret names ${vertica-username} and
${vertica-password}.
jdbc:vertica://host_name:port/database?user=${vertica-username}&password=${vertica-password}
The connector uses the secret name to retrieve secrets and provide the user name and password, as in the following example.
jdbc:vertica://host_name:port/database?user=sample-user&password=sample-password
Currently, the Vertica connector recognizes the vertica-username and
vertica-password JDBC properties.
Spill parameters
The Lambda SDK can spill data to Amazon S3. All database instances accessed by the same Lambda function spill to the same location.
| Parameter | Description |
|---|---|
spill_bucket |
Required. Spill bucket name. |
spill_prefix |
Required. Spill bucket key prefix. |
spill_put_request_headers |
(Optional) A JSON encoded map of request headers and values for
the Amazon S3 putObject request that is used for spilling
(for example, {"x-amz-server-side-encryption" :
"AES256"}). For other possible headers, see PutObject
in the Amazon Simple Storage Service API Reference. |
Data type support
The following table shows the supported data types for the Vertica connector.
| Boolean |
|---|
| BigInt |
| Short |
| Integer |
| Long |
| Float |
| Double |
| Date |
| Varchar |
| Bytes |
| BigDecimal |
| TimeStamp as Varchar |
Performance
The Lambda function performs projection pushdown to decrease the data scanned by the query. LIMIT clauses reduce the amount of data scanned, but if you do not provide a predicate, you should expect SELECT queries with a LIMIT clause to scan at least 16 MB of data. The Vertica connector is resilient to throttling due to concurrency.
Passthrough queries
The Vertica connector supports passthrough queries. Passthrough queries use a table function to push your full query down to the data source for execution.
To use passthrough queries with Vertica, you can use the following syntax:
SELECT * FROM TABLE( system.query( query => 'query string' ))
The following example query pushes down a query to a data source in Vertica. The query
selects all columns in the customer table, limiting the results to 10.
SELECT * FROM TABLE( system.query( query => 'SELECT * FROM customer LIMIT 10' ))
License information
By using this connector, you acknowledge the inclusion of third party components, a list
of which can be found in the pom.xml
See also
For the latest JDBC driver version information, see the pom.xml
For additional information about this connector, see the corresponding site
