Transforming data assets
A core value of a data lake is that it is the collection point and repository for all of an organization’s data assets, regardless of their native formats. This allows quick ingestion, elimination of data duplication and data sprawl, and centralized governance and management. After the data assets are collected, they need to be transformed into normalized formats to be used by a variety of data analytics and processing tools.
The key to ‘democratizing’ the data and making the data lake available to the widest number of users of varying skill sets and responsibilities is to transform data assets into a format that allows for efficient one-time SQL querying. Data transformation or ETL process prepares the data to be consumed by downstream systems for advanced analytics, visualizations and business reporting, or machine learning.
The first step involves extracting information from the different data sources which was discussed in the Data ingestion methods section. The data is stored in a raw bucket (refer to the Data lake foundation section of this document). After you have the data, you need to transform it. Transformations might involve aggregating the data from different sources or changing the file format of the data received, such as from CSV to Parquet format to reduce the file size and optimize the Athena query.
You can compress the files or convert the data format from string to double, or number to date format. After the transformation is complete, the data can be written into transformed bucket (refer to the Data lake foundation section of this document) which is then further used by the downstream systems.
There are multiple ways to transform data assets, and the “best” way often comes down to the nature of the analytics application, individual preference, skill sets, and the tools available. When a data lake is built on AWS, there is a wide variety of tools and services available for data transformation, so you can pick the methods and tools that best suits your purpose. Because the data lake is inherently multi-tenant, multiple data transformation jobs using different tools can run concurrently.
There are two common and straightforward methods to transform data assets into Parquet in a data lake built on S3 using Amazon EMR clusters. The first method involves creating an Amazon EMR cluster with Hive installed using the raw data assets in Amazon S3 as input, transforming those data assets into Hive tables, and then writing those Hive tables back out to Amazon S3 in Parquet format. The second method is to use Spark on Amazon EMR. With this method, a typical transformation can be achieved with only 20 lines of PySpark code.
A third data transformation method on a data lake built on S3 is to use AWS Glue. AWS Glue simplifies and automates difficult and time-consuming data discovery, conversion, mapping, and job scheduling tasks. AWS Glue guides you through the process of transforming and moving your data assets with an easy-to-use console that helps you understand your data sources, transform and prepare these data assets for analytics, and load them reliably from S3 data sources back into S3 destinations.
AWS Glue automatically crawls raw data assets in your data lake’s S3 buckets, identifies data formats, and then suggests schemas and transformations so that you don’t have to spend time hand coding data flows. You can then edit these transformations, if necessary, using the tools and technologies you already know, such as Python, Spark, Git, and your favorite integrated developer environment, and then share them with other AWS Glue users of the data lake. AWS Glue’s flexible job scheduler can be set up to run data transformation flows on a recurring basis, in response to triggers, or even in response to AWS Lambda events.
AWS Glue automatically and transparently provisions hardware resources, and distributes ETL jobs on Apache Spark nodes so that ETL run times remain consistent as data volume grows. AWS Glue coordinates the implementation of data lake jobs in the right sequence, and automatically retries failed jobs. With AWS Glue, there are no servers or clusters to manage, and you pay only for the resources consumed by your ETL jobs.
AWS Lambda functions can also be used for transforming the data stored in your data lake built on Amazon S3. Lambda functions can respond to event notifications from Amazon S3 when an object is created or deleted. You can configure a Lambda function to perform an action asynchronously, based on the event.
When data is stored in a data lake built on S3, you can share the data with multiple
applications. These applications can vary in nature and purpose (for example, ecommerce
applications, analytics applications, and marketing applications) and necessitate a different
view for each application. S3 Object Lambda
S3 Object Lambda uses a Lambda function to automatically process and transform the data as it is being retrieved from an S3 bucket. The following figure shows an example of an S3 Object Lambda.
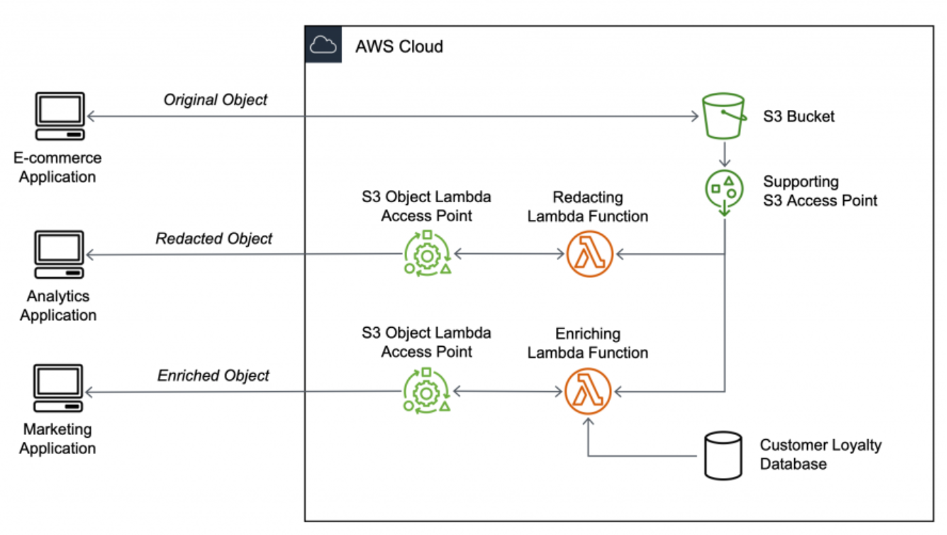
Using S3 Object Lambda to transform data before retrieval by applications
S3 Object Lambda can be very useful in redacting PII data for analytics applications, format conversion, enriching data from other data sources, resizing objects, or even implementing custom authorization rules to access the data stored in your data lake built on Amazon S3.
Another transformation feature that S3 supports natively is batch operations. Using S3 Batch Operations, you can define an operation to be performed on the exabytes of objects stored in your bucket. S3 Batch Operations manages the entire lifecycle of the batch operation by tracking the progress, sending notifications, and storing a detailed completion report for all the operations performed on the objects.
By using S3 Batch Operations, you can copy objects from a bucket into another bucket in the same or different Region, or invoke a Lambda function to transform the object. S3 Batch Operation can also be used to manage the tags defined for the objects and restoring a large number of objects from S3 Glacier. S3 Batch Operation, along with S3 Object Lock, can be used to manage retention dates and legal holds to apply compliance and governance rules for multiple objects at the same time. S3 Object Lock works on the write once read many (WORM) model that can help in prevention of accidental deletion of objects. It can also help in adhering to regulatory controls.
