How Amazon Bedrock knowledge bases work
Amazon Bedrock Knowledge Bases help you take advantage of Retrieval Augmented Generation (RAG), a popular technique that involves drawing information from a data store to augment the responses generated by Large Language Models (LLMs). When you set up a knowledge base with your data source, your application can query the knowledge base to return information to answer the query either with direct quotations from sources or with natural responses generated from the query results.
With Amazon Bedrock Knowledge Bases, you can build applications that are enriched by the context that is received from querying a knowledge base. It enables a faster time to market by abstracting from the heavy lifting of building pipelines and providing you an out-of-the-box RAG solution to reduce the build time for your application. Adding a knowledge base also increases cost-effectiveness by removing the need to continually train your model to be able to leverage your private data.
The following diagrams illustrate schematically how RAG is carried out. Knowledge base simplifies the setup and implementation of RAG by automating several steps in this process.
Pre-processing unstructured data
To enable effective retrieval from unstructured private data (data that doesn't exist in a structured data store), a common practice is to convert the data into text and split it into manageable pieces. The pieces or chunks are then converted to embeddings and written to a vector index, while maintaining a mapping to the original document. These embeddings are used to determine semantic similarity between queries and text from the data sources. The following image illustrates pre-processing of data for the vector database.
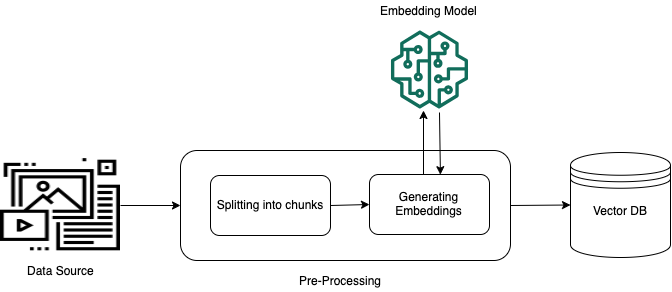
Vector embeddings are a series of numbers that represent each chunk of text. A model converts each text chunk into series of numbers, known as vectors, so that the texts can be mathematically compared. These vectors can either be floating-point numbers (float32) or binary numbers. Most embeddings models supported by Amazon Bedrock use floating-point vectors by default. However, some models support binary vectors. If you choose a binary embedding model, you must also choose a model and vector store that supports binary vectors.
Binary vectors, which use only 1 bit per dimension, aren't as costly on storage as floating-point (float32) vectors, which use 32 bits per dimension. However, binary vectors aren't as precise as floating-point vectors in their representation of the text.
The following example shows a piece of text in three representations:
| Representation | Value |
|---|---|
| Text | "Amazon Bedrock uses high-performing foundation models from leading AI companies and Amazon." |
| Floating-point vector | [0.041..., 0.056..., -0.018..., -0.012..., -0.020...,
...] |
| Binary vector | [1,1,0,0,0, ...] |
Runtime execution
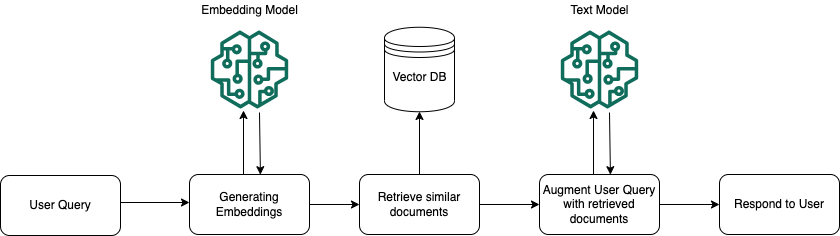
At runtime, an embedding model is used to convert the user's query to a vector. The vector index is then queried to find chunks that are semantically similar to the user's query by comparing document vectors to the user query vector. In the final step, the user prompt is augmented with the additional context from the chunks that are retrieved from the vector index. The prompt alongside the additional context is then sent to the model to generate a response for the user. The following image illustrates how RAG operates at runtime to augment responses to user queries.
To learn more about how to turn your data into a knowledge base, how to query your knowledge base after you've set it up, and customizations that you can apply to the data source during ingestion, see the following topics:
Topics
