Running a hybrid job with Amazon Braket Hybrid Jobs
To run a hybrid job with Amazon Braket Hybrid Jobs, you first need to define
your algorithm. You can define it by writing the algorithm script and,
optionally, other dependency files using the Amazon Braket Python SDK
In either case, next you create a hybrid job using the Amazon Braket
API, where you provide your algorithm script or container, select the
target quantum device the hybrid job is to use, and then choose from a variety of optional
settings. The default values provided for these optional settings work for the majority of
use cases. For the target device to run your Hybrid Job, you have a choice between a QPU,
an on-demand simulator (such as SV1, DM1 or
TN1), or the classical hybrid job instance itself. With an on-demand simulator
or QPU, your hybrid jobs container makes API calls to a remote device. With the embedded
simulators, the simulator is embedded in the same container as your algorithm script. The
lightning
simulators
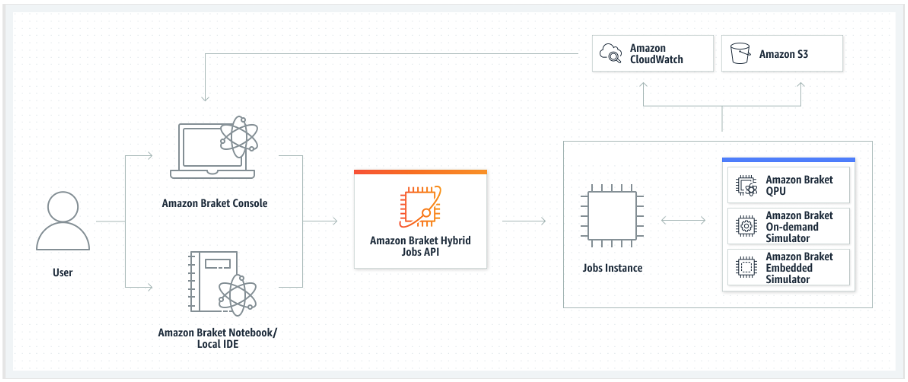
If your target device is an on-demand or embedded simulator, Amazon Braket starts running the hybrid job right away. It spins up the hybrid job instance (you can customize the instance type in the API call), runs your algorithm, writes the results to Amazon S3, and releases your resources. This release of resources ensures that you only pay for what you use.
The total number of concurrent hybrid jobs per quantum processing unit (QPU) is restricted. Today, only one hybrid job can run on a QPU at any given time. Queues are used to control the number of hybrid jobs allowed to run so as not to exceed the limit allowed. If your target device is a QPU, your hybrid job first enters the job queue of the selected QPU. Amazon Braket spins up the hybrid job instance needed and runs your hybrid job on the device. For the duration of your algorithm, your hybrid job has priority access, meaning that quantum tasks from your hybrid job run ahead of other Braket quantum tasks queued up on the device, provided the job quantum tasks are submitted to the QPU once every few minutes. Once your hybrid job is complete, resources are released, meaning you only pay for what you use.
Note
Devices are regional and your hybrid job runs in the same AWS Region as your primary device.
In both the simulator and QPU target scenarios, you have the option to define custom algorithm metrics, such as the energy of your Hamiltonian, as part of your algorithm. These metrics are automatically reported to Amazon CloudWatch and from there, they display in near real-time in the Amazon Braket console.
Note
If you wish to use a GPU based instance, be sure to use one of the GPU-based
simulators available with the embedded simulators on Braket (for example,
lightning.gpu). If you choose one of the CPU-based embedded simulators
(for example, lightning.qubit, or braket:default-simulator),
the GPU will not be used and you may incur unnecessary costs.
