Task Runner on AWS Data Pipeline-Managed Resources
When a resource is launched and managed by AWS Data Pipeline, the web service
automatically installs Task Runner on that resource to process tasks in the
pipeline. You specify a computational resource (either an Amazon EC2 instance or an Amazon EMR
cluster) for the runsOn field of an activity object. When AWS Data Pipeline
launches this resource, it installs Task Runner on that resource and configures
it to process all activity objects that have their runsOn field set to
that resource. When AWS Data Pipeline terminates the resource, the Task Runner logs are published to an Amazon S3 location before it shuts down.
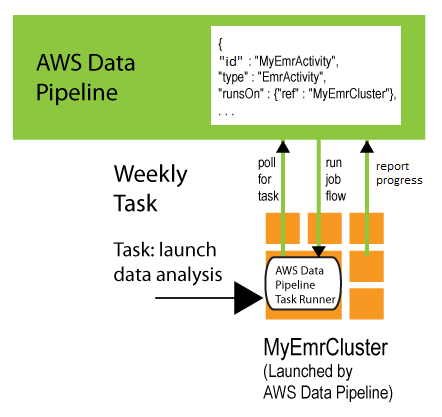
For example, if you use the EmrActivity in a pipeline,
and specify an EmrCluster resource in the runsOn
field. When AWS Data Pipeline processes that activity, it launches an Amazon EMR cluster and
installs Task Runner onto the master node. This
Task Runner then processes the tasks for activities that have their
runsOn field set to that EmrCluster object.
The following excerpt from a pipeline definition shows this relationship
between the two objects.
{ "id" : "MyEmrActivity", "name" : "Work to perform on my data", "type" : "EmrActivity", "runsOn" : {"ref" : "MyEmrCluster"}, "preStepCommand" : "scp remoteFiles localFiles", "step" : "s3://myBucket/myPath/myStep.jar,firstArg,secondArg", "step" : "s3://myBucket/myPath/myOtherStep.jar,anotherArg", "postStepCommand" : "scp localFiles remoteFiles", "input" : {"ref" : "MyS3Input"}, "output" : {"ref" : "MyS3Output"} }, { "id" : "MyEmrCluster", "name" : "EMR cluster to perform the work", "type" : "EmrCluster", "hadoopVersion" : "0.20", "keypair" : "myKeyPair", "masterInstanceType" : "m1.xlarge", "coreInstanceType" : "m1.small", "coreInstanceCount" : "10", "taskInstanceType" : "m1.small", "taskInstanceCount": "10", "bootstrapAction" : "s3://elasticmapreduce/libs/ba/configure-hadoop,arg1,arg2,arg3", "bootstrapAction" : "s3://elasticmapreduce/libs/ba/configure-other-stuff,arg1,arg2" }
For information and examples of running this activity, see EmrActivity.
If you have multiple AWS Data Pipeline-managed resources in a pipeline, Task Runner is installed on each of them, and they all poll AWS Data Pipeline for tasks to process.
