Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewährte Methoden für Leistungsoptimierung und Effizienz in Amazon MQ für RabbitMQ
Sie können die Leistung Ihres Amazon MQ for RabbitMQ-Brokers optimieren, indem Sie den Durchsatz maximieren, die Latenz minimieren und eine effiziente Ressourcennutzung sicherstellen. Gehen Sie wie folgt vor, um die Leistung Ihrer Anwendung zu optimieren.
Schritt 1: Halten Sie die Nachrichtengröße unter 1 MB
Wir empfehlen, Nachrichten unter 1 Megabyte (MB) zu halten, um optimale Leistung und Zuverlässigkeit zu gewährleisten.
RabbitMQ 3.13 unterstützt standardmäßig Nachrichtengrößen von bis zu 128 MB, aber große Nachrichten können unvorhersehbare Speicheralarme auslösen, die die Veröffentlichung blockieren und bei der knotenübergreifenden Replikation von Nachrichten potenziell zu hohem Speicherdruck führen. Zu große Nachrichten können sich auch auf die Neustart- und Wiederherstellungsprozesse des Brokers auswirken, was das Risiko für die Servicekontinuität erhöht und zu Leistungseinbußen führen kann.
Speichern und Abrufen großer Payloads mithilfe des Schemas für die Schadensüberprüfung
Um große Nachrichten zu verwalten, können Sie das Muster der Anspruchsprüfung implementieren, indem Sie die Nachrichtennutzdaten in einem externen Speicher speichern und nur die Nutzlast-Referenz-ID über RabbitMQ senden. Der Verbraucher verwendet die Nutzlast-Referenz-ID, um die umfangreiche Nachricht abzurufen und zu verarbeiten.
Das folgende Diagramm zeigt, wie Amazon MQ für RabbitMQ und Amazon S3 zur Implementierung des Antragsprüfungsmusters verwendet wird.
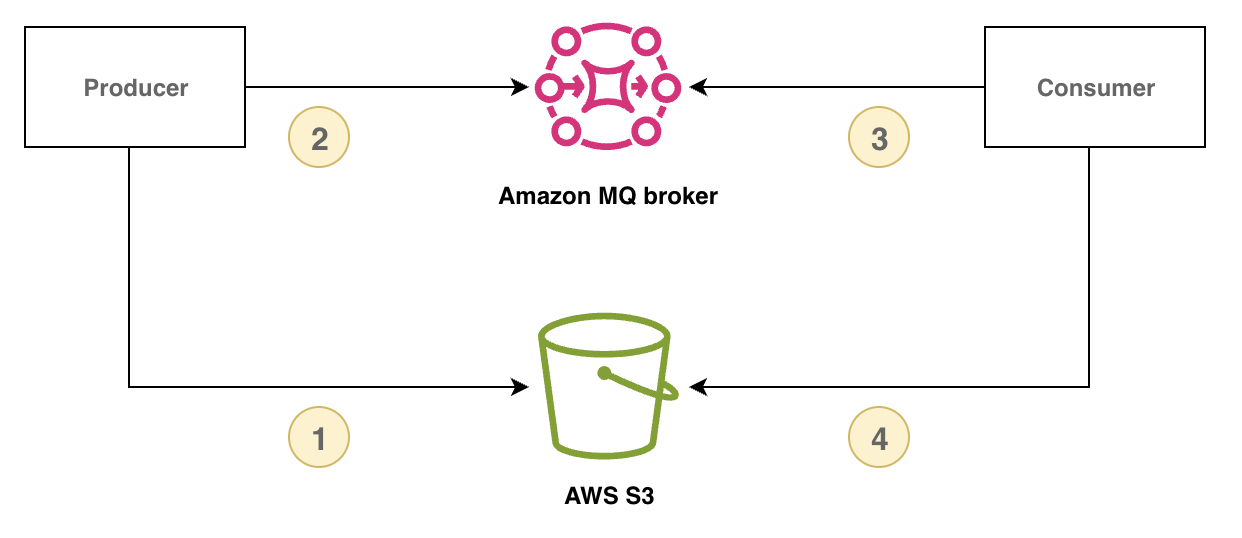
Das folgende Beispiel demonstriert dieses Muster mit Amazon MQ, dem AWS SDK for Java 2.x und Amazon S3:
-
Definieren Sie zunächst eine Message-Klasse, die die Amazon S3 S3-Referenz-ID enthält.
class Message { // Other data fields of the message... public String s3Key; public String s3Bucket; } -
Erstellen Sie eine Publisher-Methode, die die Payload in Amazon S3 speichert und eine Referenznachricht über RabbitMQ sendet.
public void publishPayload() { // Store the payload in S3. String payload = PAYLOAD; String prefix = S3_KEY_PREFIX; String s3Key = prefix + "/" + UUID.randomUUID(); s3Client.putObject(PutObjectRequest.builder() .bucket(S3_BUCKET).key(s3Key).build(), RequestBody.fromString(payload)); // Send the reference through RabbitMQ. Message message = new Message(); message.s3Key = s3Key; message.s3Bucket = S3_BUCKET; // Assign values to other fields in your message instance. publishMessage(message); } -
Implementieren Sie eine Consumer-Methode, die die Payload von Amazon S3 abruft, die Payload verarbeitet und das Amazon S3 S3-Objekt löscht.
public void consumeMessage(Message message) { // Retrieve the payload from S3. String payload = s3Client.getObjectAsBytes(GetObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()) .asUtf8String(); // Process the complete message. processPayload(message, payload); // Delete the S3 object. s3Client.deleteObject(DeleteObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()); }
Schritt 2: Nutzung und langlebige Verbraucher basic.consume
Die Verwendung basic.consume bei einem langlebigen Verbraucher ist effizienter als die Abfrage einzelner Nachrichten mithilfe von. basic.get Weitere Informationen finden Sie unter Abfragen einzelner Nachrichten
Schritt 3: Konfigurieren Sie den Vorabruf
Sie können den RabbitMQ-Prefetch-Wert verwenden, um zu optimieren, wie Ihre Verbraucher Nachrichten konsumieren. RabbitMQ implementiert den Channel-Prefetch-Mechanismus, der von AMQP 0-9-1 bereitgestellt wird, indem die Prefetch-Anzahl auf Verbraucher im Gegensatz zu Kanälen angewendet wird. Der Prefetch-Wert wird verwendet, um anzugeben, wie viele Nachrichten an den Verbraucher zu einem bestimmten Zeitpunkt gesendet werden. Standardmäßig legt RabbitMQ eine unbegrenzte Puffergröße für Clientanwendungen fest.
Es gibt eine Vielzahl von Faktoren zu berücksichtigen, wenn Sie eine Pre-Fetch-Anzahl für Ihre RabbitMQ-Verbraucher festlegen. Berücksichtigen Sie zunächst die Umgebung und Konfiguration Ihrer Verbraucher. Da Verbraucher alle Nachrichten während der Verarbeitung im Speicher behalten müssen, kann ein hoher Pre-Fetch-Wert negative Auswirkungen auf die Leistung Ihrer Verbraucher haben und in einigen Fällen dazu führen, dass ein Verbraucher alle zusammen abstürzt. Ebenso behält der RabbitMQ-Broker selbst alle Nachrichten, die er im Speicher sendet, zwischengespeichert, bis er die Verbraucherbestätigung erhält. Ein hoher Prefetch-Wert kann dazu führen, dass Ihr RabbitMQ-Server schnell über den Arbeitsspeicher verfügt, wenn die automatische Bestätigung nicht für Verbraucher konfiguriert ist und wenn Verbraucher relativ lange Zeit benötigen, um Nachrichten zu verarbeiten.
In Anbetracht der obigen Überlegungen empfehlen wir, immer einen Pre-Fetch-Wert festzulegen, um Situationen zu vermeiden, in denen ein RabbitMQ-Broker oder seine Verbraucher aufgrund einer großen Anzahl von unverarbeiteten oder nicht bestätigten Nachrichten nicht genügend Arbeitsspeicher auslaufen. Wenn Sie Ihre Broker optimieren müssen, um große Mengen von Nachrichten zu verarbeiten, können Sie Ihre Broker und Verbraucher mit einer Reihe von Pre-Fetch-Zählungen testen, um den Wert zu bestimmen, an dem der Netzwerk-Overhead im Vergleich zu der Zeit, die ein Verbraucher benötigt, um Nachrichten zu verarbeiten, weitgehend unbedeutend wird.
Anmerkung
Wenn Ihre Clientanwendungen so konfiguriert haben, dass die Zustellung von Nachrichten an Verbraucher automatisch bestätigt wird, hat das Festlegen eines Pre-Fetch-Werts keine Auswirkungen.
Alle vorab abgerufenen Nachrichten werden aus der Warteschlange entfernt.
Das folgende Beispiel demonstriert das Festlegen eines Vorabruf-Werts von10für einen einzelnen Verbraucher mit der RabbitMQ Java-Client-Bibliothek.
ConnectionFactory factory = new ConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.basicQos(10, false); QueueingConsumer consumer = new QueueingConsumer(channel); channel.basicConsume("my_queue", false, consumer);
Anmerkung
In der RabbitMQ-Java-Client-Bibliothek wird der Standardwert für dieglobal-Flag auffalse gestellt, so dass das obige Beispiel einfach alschannel.basicQos(10) ausgeschrieben werden kann.
Schritt 4: Verwenden Sie Celery 5.5 oder höher mit Quorum-Warteschlangen
Python Celery
Für alle Celery-Versionen
-
Schalten Sie
task_create_missing_queueses aus, um die Abwanderung in der Warteschlange zu verringern. -
Schalten Sie es dann aus,
worker_enable_remote_controlum die dynamische Erstellung voncelery@...pidboxWarteschlangen zu beenden. Dadurch wird die Abwanderung von Warteschlangen auf dem Broker reduziert.worker_enable_remote_control = false -
Um die Aktivität unkritischer Nachrichten weiter zu reduzieren, schalten Sie Celery aus, worker-send-task-events
indem Sie beim Starten Ihrer Celery-Anwendung Celery entweder nicht einschließen -Eoder--task-eventskennzeichnen. -
Starten Sie Ihre Cellery-Anwendung mit den folgenden Parametern:
celery -A app_name worker --without-heartbeat --without-gossip --without-mingle
Für Celery Versionen 5.5 und höher
-
Führen Sie ein Upgrade auf Celery Version 5.5
durch, die Mindestversion, die Quorum-Warteschlangen unterstützt, oder auf eine neuere Version. Um zu überprüfen, welche Version von Celery Sie verwenden, verwenden Sie. celery --versionWeitere Informationen zu Quorumwarteschlangen finden Sie unter. Quorum-Warteschlangen für RabbitMQ auf Amazon MQ -
Nach dem Upgrade auf Celery 5.5 oder höher konfigurieren Sie die Konfiguration
task_default_queue_typeauf „Quorum“. -
Anschließend müssen Sie in den Broker-Transportoptionen
auch „Bestätigungen veröffentlichen“ aktivieren: broker_transport_options = {"confirm_publish": True}
