Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von EXPLAIN und EXPLAIN ANALYZE in Athena
Die EXPLAIN-Anweisung zeigt den logischen oder verteilten Ausführungsplan einer angegebenen SQL-Anweisung oder validiert die SQL-Anweisung. Sie können die Ergebnisse im Textformat oder in einem Datenformat für das Rendern in einem Diagramm ausgeben.
Anmerkung
Sie können grafische Darstellungen logischer und verteilter Pläne für Ihre Abfragen in der Athena-Konsole anzeigen, ohne die EXPLAIN-Dateisyntax zu verwenden. Weitere Informationen finden Sie unter Ausführungspläne für SQL Abfragen anzeigen.
Die EXPLAIN ANALYZE-Anweisung zeigt sowohl den verteilten Ausführungsplan einer angegebenen SQL-Anweisung als auch die Rechenkosten jeder Operation in einer SQL-Abfrage an. Sie können die Ergebnisse im Text- oder JSON-Format ausgeben.
Überlegungen und Einschränkungen
Die EXPLAIN- und EXPLAIN ANALYZE-Anweisungen in Athena unterliegen den folgenden Einschränkungen.
-
Da
EXPLAIN-Abfragen keine Daten scannen, berechnet Athena keine Gebühren. DaEXPLAIN-Abfragen jedoch AWS Glue aufrufen, um Tabellen-Metadaten abzurufen, können Gebühren von Glue anfallen, wenn die Anrufe das kostenlose Kontingent für Glueüberschreiten. -
Weil
EXPLAIN ANALYZE-Abfragen ausgeführt werden, scannen sie Daten und Athena berechnet die gescannte Datenmenge. -
Die in Lake Formation definierten Zeilen- oder Zellenfilterinformationen und die Abfragestatistikinformationen werden in der Ausgabe von
EXPLAINundEXPLAIN ANALYZEnicht angezeigt.
EXPLAIN-Syntax
EXPLAIN [ (option[, ...]) ]statement
option kann einer der folgenden sein:
FORMAT { TEXT | GRAPHVIZ | JSON } TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
Wenn die Option FORMAT nicht angegeben ist, wird standardmäßig das TEXT-Format ausgegeben. Der IO Typ stellt Informationen zu den Tabellen und Schemas bereit, die die Abfrage liest.
EXPLAIN-ANALYZE-Syntax
Zusätzlich zu der in EXPLAIN enthaltenen Ausgabe enthält die EXPLAIN
ANALYZE-Ausgabe auch Laufzeitstatistiken für die angegebene Abfrage, z. B. die CPU-Auslastung, die Anzahl der Eingabezeilen und die Anzahl der Ausgabezeilen.
EXPLAIN ANALYZE [ (option[, ...]) ]statement
option kann einer der folgenden sein:
FORMAT { TEXT | JSON }
Wenn die Option FORMAT nicht angegeben ist, wird standardmäßig das TEXT-Format ausgegeben. Weil alle Abfragen für EXPLAIN ANALYZE DISTRIBUTED sind, ist die Option TYPE für EXPLAIN ANALYZE nicht verfügbar.
statement kann einer der folgenden sein:
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
EXPLAIN-Beispiele
Die folgenden Beispiele für EXPLAIN entwickeln sich von den einfacheren zu den komplexeren Beispielen.
Das folgende Beispiel EXPLAIN zeigt den Ausführungsplan für eine SELECT-Abfrage für Elastic-Load-Balancing-Protokolle. Das Format ist standardmäßig die Textausgabe.
EXPLAIN SELECT request_timestamp, elb_name, request_ip FROM sampledb.elb_logs;
Ergebnisse
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULARSie können mit der Athena-Konsole einen Abfrageplan grafisch darstellen. Geben Sie eine SELECT-Anweisung wie die folgende im Athena-Abfrage-Editor ein und wählen Sie dann EXPLAIN (Erklären) aus.
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey
Die Explain-Seite des Athena-Abfrage-Editors wird geöffnet und zeigt Ihnen einen verteilten Plan und einen logischen Plan für die Abfrage. Das folgende Diagramm zeigt den logischen Plan für das Beispiel.
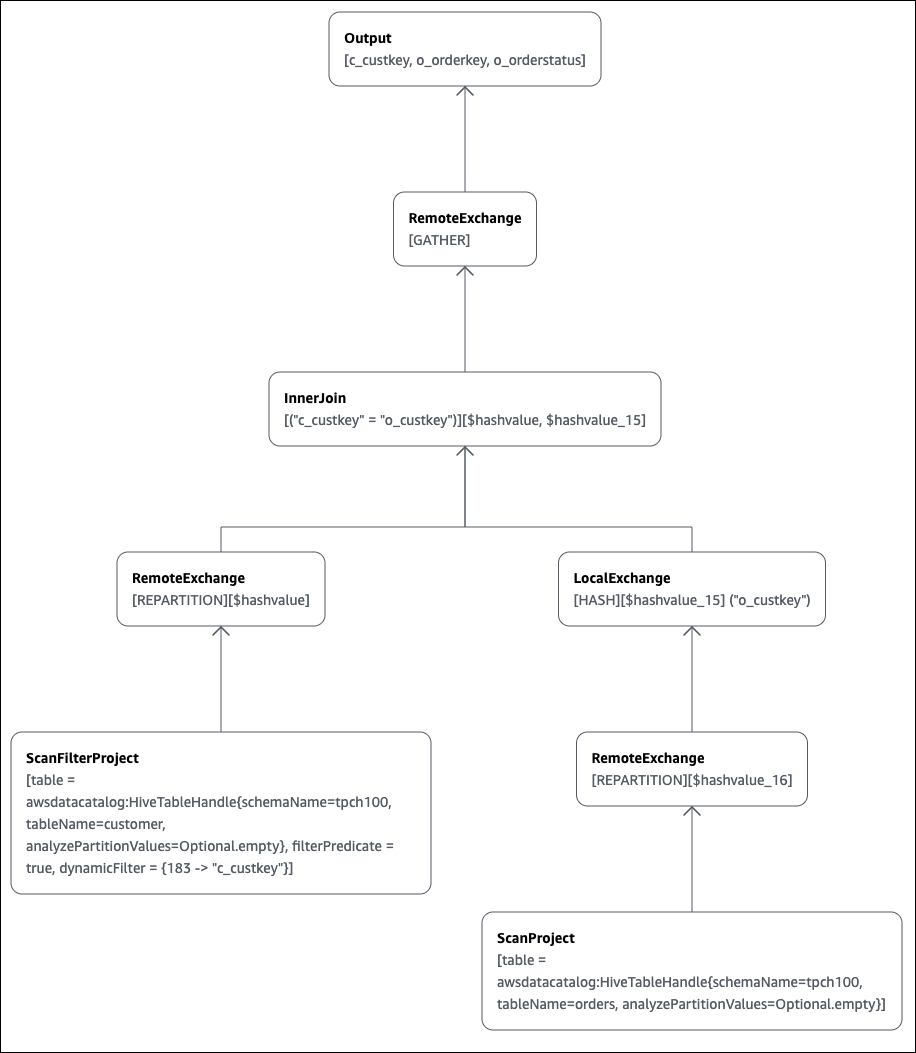
Wichtig
Derzeit sind einige Partitionsfilter im verschachtelten Operator-Baumdiagramm möglicherweise nicht sichtbar, obwohl Athena sie auf Ihre Abfrage anwendet. Um die Wirkung solcher Filter zu überprüfen, führen Sie EXPLAIN oder EXPLAIN
ANALYZE auf Ihre Anfrage aus und sehen Sie sich die Ergebnisse an.
Weitere Informationen zur Verwendung der Abfrageplan-Diagrammfeatures in der Athena-Konsole finden Sie unter Ausführungspläne für SQL Abfragen anzeigen.
Wenn Sie ein Filterprädikat für einen partitionierten Schlüssel verwenden, um eine partitionierte Tabelle abzufragen, wendet das Abfragemodul das Prädikat auf den partitionierten Schlüssel an, um die Menge der gelesenen Daten zu reduzieren.
Im folgenden Beispiel wird eine EXPLAIN-Abfrage verwendet, um die Partitionsbereinigung für eine SELECT-Abfrage in einer partitionierten Tabelle zu überprüfen. Zuerst erstellt eine CREATE TABLE-Anweisung die tpch100.orders_partitioned-Tabelle. Die Tabelle ist nach Spalte o_orderdate partitioniert.
CREATE TABLE `tpch100.orders_partitioned`( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_totalprice` double, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) PARTITIONED BY ( `o_orderdate` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://amzn-s3-demo-bucket/<your_directory_path>/'
Die tpch100.orders_partitioned-Tabelle hat mehrere Partitionen auf o_orderdate, wie der Befehl SHOW PARTITIONS zeigt.
SHOW PARTITIONS tpch100.orders_partitioned; o_orderdate=1994 o_orderdate=2015 o_orderdate=1998 o_orderdate=1995 o_orderdate=1993 o_orderdate=1997 o_orderdate=1992 o_orderdate=1996
Die folgende EXPLAIN-Abfrage überprüft die Partitionsbereinigung für die angegebene SELECT-Anweisung.
EXPLAIN SELECT o_orderkey, o_custkey, o_orderdate FROM tpch100.orders_partitioned WHERE o_orderdate = '1995'
Ergebnisse
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARDer fett gedruckte Text im Ergebnis zeigt, dass das Prädikat o_orderdate =
'1995' auf den PARTITION_KEY angewendet wurde.
Die folgende EXPLAIN-Abfrage überprüft die Join-Reihenfolge und den Join-Typ der SELECT-Anweisung. Verwenden Sie eine Abfrage wie diese, um die Speicherauslastung der Abfrage zu untersuchen, um die Wahrscheinlichkeit eines EXCEEDED_LOCAL_MEMORY_LIMIT-Fehlers zu verringern.
EXPLAIN (TYPE DISTRIBUTED) SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
Ergebnisse
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULARDie Beispielabfrage wurde für eine bessere Leistung zu einem Cross-Join optimiert. Die Ergebnisse zeigen, dass tpch100.orders als BROADCAST-Verteilungstyp verteilt wird. Dies impliziert, dass die tpch100.orders-Tabelle an alle Knoten verteilt wird, die den Join-Vorgang ausführen. Der BROADCAST-Verteilungstyp erfordert, dass alle gefilterten Ergebnisse der tpch100.orders-Tabelle in den Speicher jedes Knotens passen, der die Join-Operation ausführt.
Die tpch100.customer-Tabelle ist jedoch kleiner als tpch100.orders. Da tpch100.customer weniger Speicher benötigt, können Sie die Abfrage in BROADCAST
tpch100.customer statt in tpch100.orders umschreiben. Dies verringert die Wahrscheinlichkeit, dass die Abfrage den EXCEEDED_LOCAL_MEMORY_LIMIT-Fehler erhält. Diese Strategie setzt folgende Punkte voraus:
-
Das
tpch100.customer.c_custkeyist in dertpch100.customer-Tabelle eindeutig. -
Es besteht eine one-to-many Zuordnungsbeziehung zwischen
tpch100.customerundtpch100.orders.
Im folgenden Beispiel wird die neu geschriebene Abfrage dargestellt.
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.orders o JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes. ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
Sie können eine EXPLAIN-Abfrage verwenden, um die Wirksamkeit des Filterns von Prädikaten zu überprüfen. Sie können die Ergebnisse verwenden, um Prädikate zu entfernen, die keine Auswirkung haben, wie im folgenden Beispiel.
EXPLAIN SELECT c.c_name FROM tpch100.customer c WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT) AND c.c_custkey BETWEEN 1000 AND 2000 AND c.c_custkey = 1500
Ergebnisse
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULARDas filterPredicate in den Ergebnissen zeigt, dass der Optimierer die ursprünglichen drei Prädikate zu zwei Prädikaten zusammengeführt und ihre Anwendungsreihenfolge geändert hat.
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
Da die Ergebnisse zeigen, dass das Prädikat AND c.c_custkey BETWEEN
1000 AND 2000 keine Auswirkung hat, können Sie dieses Prädikat entfernen, ohne die Abfrageergebnisse zu ändern.
Informationen zu den in den Ergebnissen von EXPLAIN-Abfragen verwendeten Begriffen finden Sie unter Verstehen Sie die Ergebnisse der EXPLAIN Athena-Erklärung.
EXPLAIN-ANALYZE-Beispiele
In den nachstehenden Beispielen wird ein Beispiel für EXPLAIN ANALYZE-Abfragen und Ausgaben gezeigt.
Das folgende Beispiel EXPLAIN ANALYZE zeigt den Ausführungsplan und die Rechenkosten für eine SELECT Abfrage von Protokollen. CloudFront Das Format ist standardmäßig die Textausgabe.
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
Ergebnisse
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULARDas folgende Beispiel zeigt den Ausführungsplan und die Rechenkosten für eine SELECT Abfrage von CloudFront Protokollen. Im Beispiel wird JSON als Ausgabeformat angegeben.
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
Ergebnisse
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}Weitere Ressourcen
Weitere Informationen finden Sie in den folgenden Ressourcen.
-
Statistiken und Ausführungsdetails für abgeschlossene Abfragen anzeigen
-
Trino-Dokumentation
EXPLAIN -
Trino-Dokumentation
EXPLAIN ANALYZE -
Optimieren Sie die Leistung von Verbundabfragen mit EXPLAIN und EXPLAIN ANALYZE in Amazon Athena
im AWS -Big-Data-Blog.
