Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Einen Amazon Chime SDK-Data Lake erstellen
Mit dem Amazon Chime SDK Call Analytics Data Lake können Sie Ihre auf maschinellem Lernen basierenden Erkenntnisse und alle Metadaten aus Amazon Kinesis Data Stream in Ihren Amazon S3 S3-Bucket streamen. Verwenden Sie beispielsweise den Data Lake für den Zugriff URLs auf Aufzeichnungen. Um den Data Lake zu erstellen, stellen Sie eine Reihe von AWS CloudFormation Vorlagen entweder über die Amazon Chime SDK-Konsole oder programmgesteuert mithilfe von bereit. AWS CLI Mit dem Data Lake können Sie Ihre Anrufmetadaten und Sprachanalysedaten abfragen, indem Sie auf AWS Glue-Datentabellen in Amazon Athena verweisen.
Themen
Voraussetzungen
Sie benötigen die folgenden Elemente, um einen Amazon Chime SDK-Lake zu erstellen:
-
Ein Amazon Kinesis Kinesis-Datenstream. Weitere Informationen finden Sie unter Creating a Stream via the AWS Management Console im Amazon Kinesis Streams Developer Guide.
-
Ein S3-Bucket. Weitere Informationen finden Sie unter Erstellen Sie Ihren ersten Amazon S3 S3-Bucket im Amazon S3 S3-Benutzerhandbuch.
Terminologie und Konzepte von Data Lakes
Verwenden Sie die folgenden Begriffe und Konzepte, um zu verstehen, wie der Data Lake funktioniert.
- Amazon Kinesis Data Firehose
-
Ein ETL-Service (Extrahieren, Transformieren und Laden), der Streaming-Daten zuverlässig erfasst, transformiert und an Data Lakes, Datenspeicher und Analysedienste weiterleitet. Weitere Informationen finden Sie unter Was ist Amazon Kinesis Data Firehose?
- Amazon Athena
-
Amazon Athena ist ein interaktiver Abfrageservice, mit dem Sie Daten in Amazon S3 mithilfe von Standard-SQL analysieren können. Athena ist serverlos, sodass Sie keine Infrastruktur verwalten müssen, und Sie zahlen nur für die Abfragen, die Sie ausführen. Um Athena zu verwenden, verweisen Sie auf Ihre Daten in Amazon S3, definieren Sie das Schema und verwenden Sie Standard-SQL-Abfragen. Sie können Arbeitsgruppen auch verwenden, um Benutzer zu gruppieren und zu kontrollieren, auf welche Ressourcen sie bei der Ausführung von Abfragen Zugriff haben. Arbeitsgruppen ermöglichen es Ihnen, die Parallelität von Abfragen zu verwalten und die Ausführung von Abfragen für verschiedene Benutzergruppen und Workloads zu priorisieren.
- Glue Data Catalog
-
In Amazon Athena enthalten Tabellen und Datenbanken die Metadaten, die ein Schema für die zugrunde liegenden Quelldaten detailliert beschreiben. Für jeden Datensatz muss eine Tabelle in Athena existieren. Die Metadaten in der Tabelle teilen Athena den Standort Ihres Amazon S3 S3-Buckets mit. Es spezifiziert auch die Datenstruktur, wie Spaltennamen, Datentypen und den Namen der Tabelle. Datenbanken enthalten nur die Metadaten und Schemainformationen für einen Datensatz.
Mehrere Data Lakes erstellen
Es können mehrere Data Lakes erstellt werden, indem ein eindeutiger Glue-Datenbankname angegeben wird, um anzugeben, wo Anrufinformationen gespeichert werden sollen. Für ein bestimmtes AWS Konto kann es mehrere Konfigurationen für Anrufanalysen mit jeweils einem entsprechenden Data Lake geben. Dies bedeutet, dass die Datentrennung für bestimmte Anwendungsfälle angewendet werden kann, z. B. für die Anpassung der Aufbewahrungsrichtlinien und die Zugriffsrichtlinien für die Speicherung der Daten. Für den Zugriff auf Erkenntnisse, Aufzeichnungen und Metadaten können unterschiedliche Sicherheitsrichtlinien angewendet werden.
Regionale Verfügbarkeit von Data Lakes
Der Amazon Chime SDK Data Lake ist in den folgenden Regionen verfügbar.
Region |
Tisch Glue |
QuickSight |
|---|---|---|
us-east-1 |
Verfügbar |
Verfügbar |
us-west-2 |
Verfügbar |
Verfügbar |
eu-central-1 |
Verfügbar |
Verfügbar |
Data-Lake-Architektur
Das folgende Diagramm zeigt die Data-Lake-Architektur. Die Zahlen in der Zeichnung entsprechen dem unten stehenden nummerierten Text.
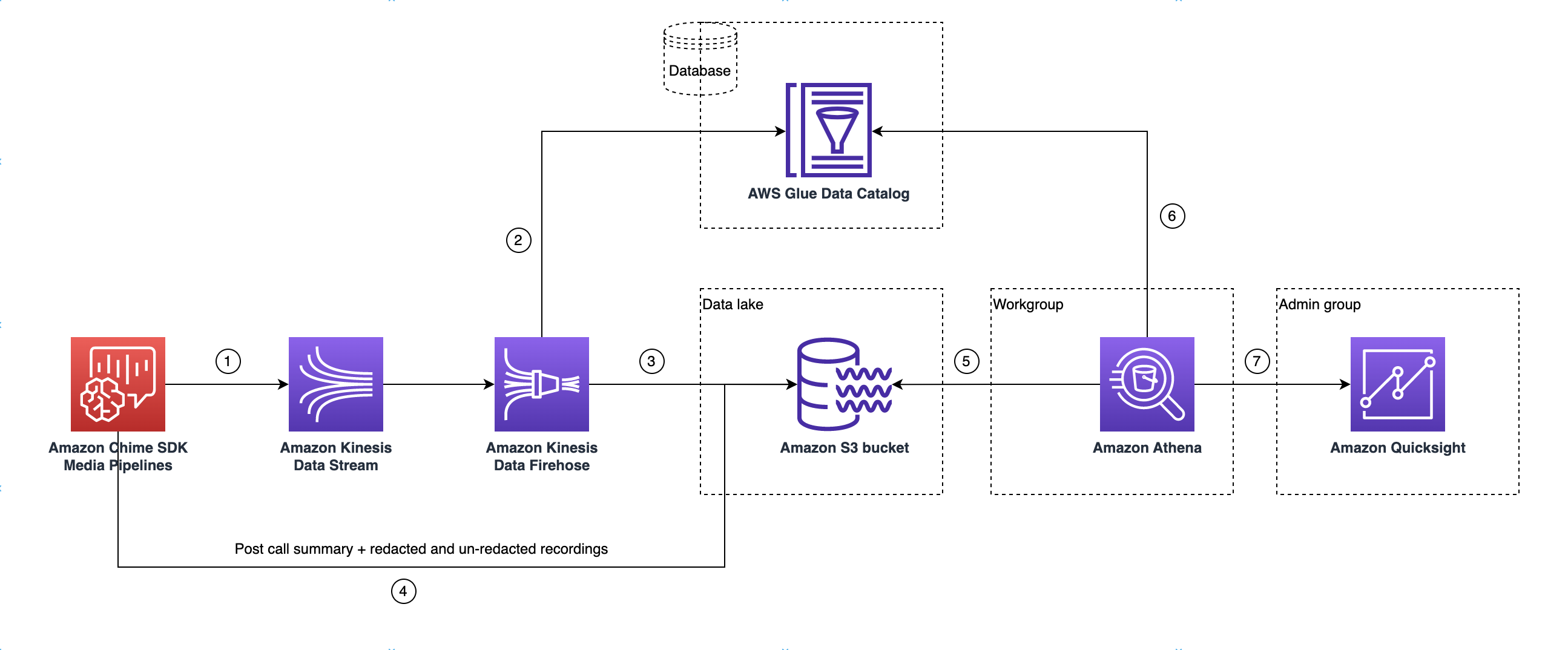
Sobald Sie im Diagramm die AWS Konsole zum Bereitstellen der CloudFormation Vorlage aus dem Workflow zur Einrichtung der Media Insights-Pipeline-Konfiguration verwenden, fließen die folgenden Daten in den Amazon S3 S3-Bucket:
-
Die Amazon Chime SDK-Anrufanalysen beginnen mit dem Streaming von Echtzeitdaten in den Kinesis Data Stream des Kunden.
-
Amazon Kinesis Firehose speichert diese Echtzeitdaten, bis sie 128 MB oder 60 Sekunden angesammelt haben, je nachdem, was zuerst eintritt. Firehose verwendet dann den
amazon_chime_sdk_call_analytics_firehose_schemaim Glue-Datenkatalog enthaltenen, um die Daten zu komprimieren, und wandelt die JSON-Datensätze in eine Parquet-Datei um. -
Die Parkettdatei befindet sich in Ihrem Amazon S3 S3-Bucket in einem partitionierten Format.
-
Neben Echtzeitdaten werden auch Zusammenfassungen von Amazon Transcribe Call Analytics in Form von WAV-Dateien (geschwärzt und nicht geschwärzt, sofern in der Konfiguration angegeben) und WAV-Dateien für die Anrufaufzeichnung an Ihren Amazon S3 S3-Bucket gesendet.
-
Sie können Amazon Athena und Standard-SQL verwenden, um die Daten im Amazon S3 S3-Bucket abzufragen.
-
Die CloudFormation Vorlage erstellt auch einen Glue-Datenkatalog, um diese zusammenfassenden Daten nach dem Anruf über Athena abzufragen.
-
Alle Daten im Amazon S3 S3-Bucket können auch mithilfe QuickSight von visualisiert werden. QuickSight baut mithilfe von Amazon Athena eine Verbindung mit einem Amazon S3 S3-Bucket auf.
Die Amazon Athena Athena-Tabelle verwendet die folgenden Funktionen, um die Abfrageleistung zu optimieren:
- Datenpartitionierung
-
Durch die Partitionierung wird Ihre Tabelle in Teile aufgeteilt und die zugehörigen Daten werden anhand von Spaltenwerten wie Datum, Land und Region zusammengefasst. Partitionen verhalten sich wie virtuelle Spalten. In diesem Fall definiert die CloudFormation Vorlage Partitionen bei der Tabellenerstellung, wodurch die pro Abfrage gescannte Datenmenge reduziert und die Leistung verbessert wird. Sie können auch nach Partitionen filtern, um die Menge der von einer Abfrage gescannten Daten einzuschränken. Weitere Informationen finden Sie unter Partitionierung von Daten in Athena im Amazon Athena Athena-Benutzerhandbuch.
Dieses Beispiel zeigt die Partitionierungsstruktur mit dem Datum 1. Januar 2023:
-
s3://example-bucket/amazon_chime_sdk_data_lake /serviceType=CallAnalytics/detailType={DETAIL_TYPE}/year=2023/month=01/day=01/example-file.parquet -
wo
DETAIL_TYPEist einer der folgenden:-
CallAnalyticsMetadata -
TranscribeCallAnalytics -
TranscribeCallAnalyticsCategoryEvents -
Transcribe -
Recording -
VoiceAnalyticsStatus -
SpeakerSearchStatus -
VoiceToneAnalysisStatus
-
-
- Optimieren Sie die Generierung von spaltenbasierten Datenspeichern
-
Apache Parquet verwendet spaltenweise Komprimierung, Komprimierung basierend auf dem Datentyp und Prädikat-Pushdown zum Speichern von Daten. Bessere Komprimierungsraten oder das Überspringen von Datenblöcken bedeuten, dass weniger Byte aus Ihrem Amazon S3 S3-Bucket gelesen werden. Das führt zu einer besseren Abfrageleistung und geringeren Kosten. Für diese Optimierung ist die Datenkonvertierung von JSON zu Parquet in Amazon Kinesis Data Firehose aktiviert.
- Partitionsprojektion
-
Diese Athena-Funktion erstellt automatisch Partitionen für jeden Tag, um die Leistung datumsbasierter Abfragen zu verbessern.
Einrichtung des Data Lake
Verwenden Sie die Amazon Chime SDK-Konsole, um die folgenden Schritte auszuführen.
-
Starten Sie die Amazon Chime SDK-Konsole ( https://console.aws.amazon.com/chime-sdk/Home
) und wählen Sie im Navigationsbereich unter Call Analytics die Option Configurations aus. -
Schließen Sie Schritt 1 ab, wählen Sie Weiter und aktivieren Sie auf der Seite Schritt 2 das Kontrollkästchen Voice Analytics.
-
Aktivieren Sie unter Ausgabedetails das Kontrollkästchen Data Warehouse für die Durchführung historischer Analysen und wählen Sie dann den Link CloudFormation Stack bereitstellen aus.
Das System leitet Sie zur Seite Quick Create Stack in der CloudFormation Konsole weiter.
-
Geben Sie einen Namen für den Stack und anschließend die folgenden Parameter ein:
-
DataLakeType— Wählen Sie Create Call Analytics DataLake. -
KinesisDataStreamName— Wähle deinen Stream. Es sollte der Stream sein, der für das Streaming von Anrufanalysen verwendet wird. -
S3BucketURI— Wählen Sie Ihren Amazon S3 S3-Bucket. Die URI muss das Präfix habens3://bucket-name -
GlueDatabaseName— Wählen Sie einen eindeutigen Namen für die AWS Glue-Datenbank. Sie können eine bestehende Datenbank im AWS Konto nicht wiederverwenden.
-
-
Aktivieren Sie das Bestätigungskästchen und wählen Sie dann Data Lake erstellen aus. Warten Sie 10 Minuten, bis das System den Lake erstellt hat.
Einrichtung des Data Lake mit AWS CLI
Wird verwendet AWS CLI , um eine Rolle mit Berechtigungen zum Aufrufen CloudFormation von Create Stack zu erstellen. Gehen Sie wie folgt vor, um die IAM-Rollen zu erstellen und einzurichten. Weitere Informationen finden Sie unter Erstellen eines Stacks im AWS CloudFormation Benutzerhandbuch.
-
Erstellen Sie eine Rolle namens AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role und fügen Sie der Rolle eine Vertrauensrichtlinie hinzu, die es ermöglicht, die Rolle zu übernehmen. CloudFormation
-
Erstellen Sie mithilfe der folgenden Vorlage eine IAM-Vertrauensrichtlinie und speichern Sie die Datei im.json-Format.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": {} } ] } -
Führen Sie den aws iam create-role Befehl aus und übergeben Sie die Vertrauensrichtlinie als Parameter.
aws iam create-role \ --role-name AmazonChimeSdkCallAnalytics-Datalake-Provisioning-Role --assume-role-policy-document file://role-trust-policy.json -
Notieren Sie sich den Rollen-ARN, der von der Antwort zurückgegeben wird. Die Rolle arn ist im nächsten Schritt erforderlich.
-
-
Erstellen Sie eine Richtlinie mit der Erlaubnis, einen CloudFormation Stack zu erstellen.
-
Erstellen Sie eine IAM-Richtlinie mithilfe der folgenden Vorlage und speichern Sie die Datei im JSON-Format. Diese Datei ist erforderlich, wenn Sie create-policy aufrufen.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "DeployCloudFormationStack", "Effect": "Allow", "Action": [ "cloudformation:CreateStack" ], "Resource": "*" } ] } -
Führen Sie die Create-Stack-Richtlinie aus aws iam create-policy und übergeben Sie sie als Parameter.
aws iam create-policy --policy-name testCreateStackPolicy --policy-document file://create-cloudformation-stack-policy.json -
Notieren Sie sich den Rollen-ARN, der von der Antwort zurückgegeben wird. Die Rolle arn ist im nächsten Schritt erforderlich.
-
-
Fügen Sie der Rolle die aws iam attach-role-policy-Richtlinie an.
aws iam attach-role-policy --role-name {Role name created above} --policy-arn {Policy ARN created above} -
Erstellen Sie einen CloudFormation Stack und geben Sie die erforderlichen Parameter ein:aws cloudformation create-stack.
Geben Sie Parameterwerte für jede ParameterKey Verwendung an ParameterValue.
aws cloudformation create-stack --capabilities CAPABILITY_NAMED_IAM --stack-name testDeploymentStack --template-url https://chime-sdk-assets.s3.amazonaws.com/public_templates/AmazonChimeSDKDataLake.yaml --parameters ParameterKey=S3BucketURI,ParameterValue={S3 URI} ParameterKey=DataLakeType,ParameterValue="Create call analytics datalake" ParameterKey=KinesisDataStreamName,ParameterValue={Name of Kinesis Data Stream} --role-arn {Role ARN created above}
Ressourcen, die durch das Data Lake-Setup erstellt wurden
In der folgenden Tabelle sind die Ressourcen aufgeführt, die beim Erstellen eines Data Lakes erstellt wurden.
Ressourcentyp |
Name und Beschreibung der Ressource |
Service-Name |
|---|---|---|
AWS Glue Glue-Datenkatalog-Datenbank |
GlueDatabaseName— Gruppiert logisch alle AWS Glue Glue-Datentabellen, die zu Call Insights und Voice Analytics gehören. |
Anrufanalysen, Sprachanalysen |
|
AWS Glue Glue-Datenkatalogtabellen |
amazon_chime_sdk_call_analytics_firehose_schema — Kombiniertes Schema für Sprachanalysen zur Anrufanalyse, das in die Kinesis Firehose eingespeist wird. |
Anrufanalysen, Sprachanalysen |
call_analytics_metadata — Schema für Anrufanalyse-Metadaten. Enthält SIPmetadata OneTimeMetadata und. |
Analytik anrufen |
|
| call_analytics_recording_metadata — Schema für Metadaten zur Aufnahme und Sprachverbesserung | Anrufanalysen, Sprachanalysen | |
transcribe_call_analytics — Schema für die Nutzlast „UtteranceEvent“ TranscribeCallAnalytics |
Rufen Sie Analytics auf |
|
transcribe_call_analytics_category_events — Schema für die Nutzlast „CategoryEvent“ TranscribeCallAnalytics |
Rufen Sie Analytics auf |
|
transcribe_call_analytics_post_call — Schema für die zusammenfassende Payload von Transcribe Call Analytics nach dem Anruf |
Analytik von Anrufen |
|
transcribe — Schema für Transcribe Payload |
Analytik aufrufen |
|
voice_analytics_status — Schema für Ereignisse, die für Sprachanalysen bereit sind |
Sprachanalyse |
|
speaker_search_status — Schema zur Identifizierung von Übereinstimmungen |
Sprachanalyse |
|
voice_tone_analysis_status — Schema für Ereignisse zur Stimmenanalyse |
Sprachanalyse |
|
Amazon Kinesis Data Firehose |
AmazonChimeSDK-Call-Analytics- |
Anrufanalysen, Sprachanalysen |
Amazon Athena Athena-Arbeitsgruppe |
GlueDatabaseName- AmazonChime SDKData Analytics — Logische Benutzergruppe zur Steuerung der Ressourcen, auf die sie bei der Ausführung von Abfragen Zugriff haben. |
Anrufanalysen, Sprachanalysen |
