Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Trainieren Sie Ihr erstes DeepRacer AWS-Modell
Diese exemplarische Vorgehensweise zeigt, wie Sie Ihr erstes Modell mit der DeepRacer AWS-Konsole trainieren.
Trainieren Sie ein Reinforcement-Learning-Modell mit der DeepRacer AWS-Konsole
Erfahren Sie, wo Sie in der DeepRacer AWS-Konsole die Schaltfläche Modell erstellen finden, um mit dem Modelltraining zu beginnen.
Um ein Reinforcement-Learning-Modell zu trainieren
-
Wenn Sie AWS zum ersten Mal verwenden DeepRacer, wählen Sie auf der Service-Landingpage die Option Modell erstellen oder im Hauptnavigationsbereich unter der Überschrift Reinforcement Learning die Option Erste Schritte aus.
-
Wählen Sie auf der Seite Erste Schritte mit Reinforcement-Learning unter Schritt 2: Modell erstellen die Option Modell erstellen aus.
Sie können auch im Hauptnavigationsbereich unter der Überschrift Reinforcement-Learning die Option Ihre Modelle auswählen. Wählen Sie auf der Seite Your Models (Ihre Modelle) die Option Create model (Modell erstellen) aus.
Geben Sie den Modellnamen und die Umgebung an
Benennen Sie Ihr Modell und erfahren Sie, wie Sie die für Sie passende Simulationsstrecke auswählen.
Um den Modellnamen und die Umgebung anzugeben
-
Geben Sie auf der Seite Modell erstellen unter Trainingsdetails einen Namen für Ihr Modell ein.
-
Fügen Sie optional eine Beschreibung der Ausbildungsstelle hinzu.
-
Weitere Informationen zum Hinzufügen optionaler Tags finden Sie unterTagging.
-
Wählen Sie unter Umgebungssimulation einen Kurs aus, der als Schulungsumgebung für Ihren DeepRacer AWS-Agenten dienen soll. Wählen Sie unter Track-Richtung die Option Im Uhrzeigersinn oder Gegen den Uhrzeigersinn aus. Wählen Sie anschließend Weiter.
Wählen Sie für die erste Ausführung eine Strecke mit einer einfachen Form und sanften Kurven aus. In späteren Iterationen können Sie komplexere Strecken auswählen, um die Modelle schrittweise zu verbessern. Um ein Modell für eine bestimmte Rennveranstaltung zu trainieren, wählen Sie die Strecke aus, die der Strecke der Veranstaltung am ähnlichsten ist.
-
Wählen Sie unten auf der Seite „Weiter“ aus.
Wähle einen Renntyp und einen Trainingsalgorhythmus
Die DeepRacer AWS-Konsole bietet drei Renntypen und zwei Trainingsalgorhythmen, aus denen Sie wählen können. Erfahren Sie, welche für Ihr Qualifikationsniveau und Ihre Trainingsziele geeignet sind.
Um einen Renntyp und einen Trainingsalgorhythmus auszuwählen
-
Wählen Sie auf der Seite Modell erstellen unter Renntyp die Option Zeitfahren, Objektvermeidung oder H ead-to-bot aus.
Für deinen ersten Lauf empfehlen wir, Time Trial zu wählen. Hinweise zur Optimierung der Sensorkonfiguration Ihres Agenten für diesen Renntyp finden Sie unterMaßgeschneiderte DeepRacer AWS-Schulungen für Zeitfahren.
-
Wählen Sie bei späteren Läufen optional die Option „Objektvermeidung“, um stationäre Hindernisse zu umgehen, die an festen oder zufälligen Stellen entlang der ausgewählten Strecke platziert sind. Weitere Informationen finden Sie unter Maßgeschneiderte DeepRacer AWS-Schulungen für Rennen zur Objektvermeidung.
-
Wählen Sie „Feste Position“, um Boxen an festen, vom Benutzer festgelegten Positionen auf den beiden Spuren der Strecke zu generieren, oder wählen Sie „Zufälliger Ort“, um Objekte zu generieren, die zu Beginn jeder Episode Ihrer Trainingssimulation zufällig auf die beiden Spuren verteilt werden.
-
Wählen Sie als Nächstes einen Wert für die Anzahl der Objekte auf einer Strecke.
-
Wenn Sie „Feste Position“ wählen, können Sie die Position der einzelnen Objekte auf der Spur anpassen. Wählen Sie für die Platzierung der Fahrspur zwischen der Innenspur und der Außenspur. Standardmäßig sind Objekte gleichmäßig über die Spur verteilt. Um zu ändern, wie weit sich ein Objekt zwischen Start- und Ziellinie befindet, geben Sie in das Feld Position (%) zwischen Start und Ziel einen Prozentsatz dieser Entfernung zwischen sieben und 90 ein.
-
-
Optional kannst du für anspruchsvollere Läufe Head-to-bot Rennen wählen, bei denen du gegen bis zu vier Bot-Fahrzeuge antrittst, die sich mit konstanter Geschwindigkeit bewegen. Weitere Informationen hierzu finden Sie unter Maßgeschneiderte DeepRacer AWS-Schulungen für head-to-bot Rennen.
-
Wähle unter Anzahl der Bot-Fahrzeuge auswählen aus, mit wie vielen Bot-Fahrzeugen dein Agent trainieren soll.
-
Wählen Sie als Nächstes die Geschwindigkeit in Millimetern pro Sekunde aus, mit der die Bot-Fahrzeuge auf der Strecke fahren sollen.
-
Aktivieren Sie optional das Kontrollkästchen Spurwechsel aktivieren, um den Bot-Fahrzeugen die Möglichkeit zu geben, alle 1-5 Sekunden nach dem Zufallsprinzip die Spur zu wechseln.
-
-
Wählen Sie unter Trainingsalgorithmus und Hyperparameter den Algorithmus Soft Actor Critic (SAC) oder Proximal Policy Optimization (PPO) aus. In der DeepRacer AWS-Konsole müssen SAC-Modelle in kontinuierlichen Aktionsbereichen trainiert werden. PPO-Modelle können entweder in kontinuierlichen oder diskreten Aktionsräumen trainiert werden.
-
Verwenden Sie unter Trainingsalgorithmus und Hyperparameter die standardmäßigen Hyperparameterwerte unverändert.
Um die Schulungsleistung zu verbessern, erweitern Sie später Hyperparameters (Hyperparameter) und ändern Sie die Standardwerte für Hyperparameter wie folgt:
-
Wählen Sie für Gradient Descent Batch Size (Gradientenabstieg-Batchgröße) die Option Available options (Verfügbare Optionen) aus.
-
Legen Sie für Number of epochs (Anzahl der Epochen) einen gültigen Wert fest.
-
Legen Sie für Learning rate (Lernrate) einen gültigen Wert fest.
-
Geben Sie für den SAC-Alphawert (nur SAC-Algorithmus) einen gültigen Wert ein.
-
Legen Sie für Entropy (Entropie) einen gültigen Wert fest.
-
Legen Sie für Discount factor (Abschlagfaktor) einen gültigen Wert fest.
-
Wählen Sie für Loss type (Loss-Typ) verfügbare Optionen aus.
-
Legen Sie für Number of experience episodes between each policy-updating iteration (Anzahl der Erfahrungsepisoden zwischen den einzelnen Strategieaktualisierungs-Iterationen) einen gültigen Wert fest.
Weitere Informationen zu Hyperparametern finden Sie unter Passen Sie Hyperparameter systematisch an.
-
-
Wählen Sie Weiter.
Definieren Sie den Aktionsraum
Wenn Sie sich auf der Seite Aktionsraum definieren dafür entschieden haben, mit dem Soft Actor Critic (SAC) -Algorithmus zu trainieren, ist Ihr Standard-Aktionsraum der kontinuierliche Aktionsraum. Wenn Sie sich für das Training mit dem PPO-Algorithmus (Proximal Policy Optimization) entschieden haben, wählen Sie zwischen Continuous Action Space und Discrete Action Space. Weitere Informationen darüber, wie die einzelnen Aktionsbereiche und Algorithmen das Trainingserlebnis des Agenten beeinflussen, finden Sie unter DeepRacer AWS-Aktionsraum und Belohnungsfunktion.
-
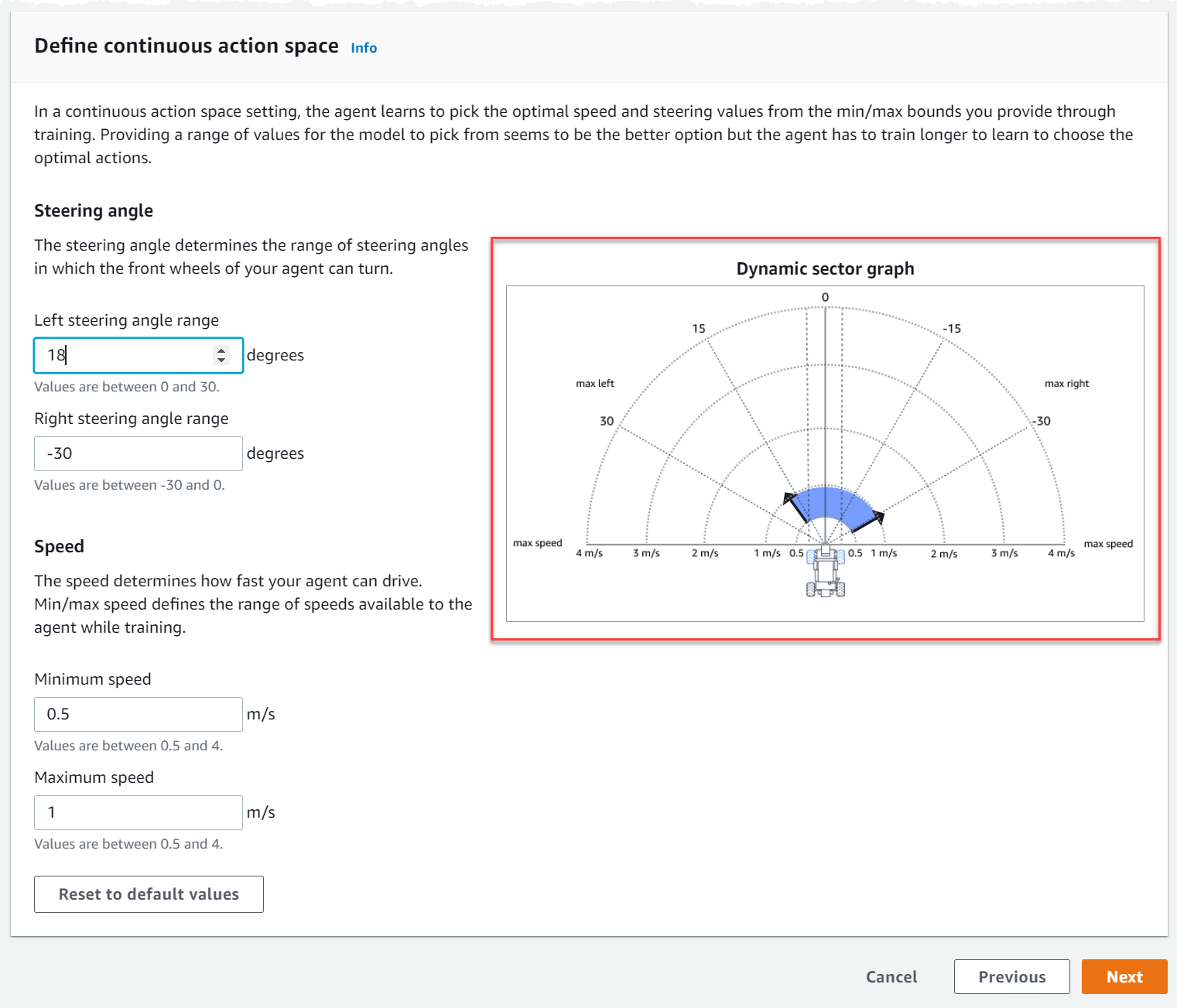
Wählen Sie unter Kontinuierlichen Aktionsraum definieren die Grade Ihres linken Lenkwinkelbereichs und des rechten Lenkwinkelbereichs aus.
Versuchen Sie, für jeden Lenkwinkelbereich unterschiedliche Grade einzugeben, und beobachten Sie, wie sich die Darstellung Ihres Bereichs ändert, um Ihre Auswahl im dynamischen Sektordiagramm darzustellen.
-
Geben Sie unter Geschwindigkeit eine Mindest- und Höchstgeschwindigkeit für Ihren Agenten in Millimetern pro Sekunde ein.
Beachten Sie, wie sich Ihre Änderungen im dynamischen Sektordiagramm widerspiegeln.
-
Wählen Sie optional Auf Standardwerte zurücksetzen, um unerwünschte Werte zu löschen. Wir empfehlen, verschiedene Werte in der Grafik auszuprobieren, um zu experimentieren und zu lernen.
-
Wählen Sie Weiter.
-
Wählen Sie einen Wert für die Granularität des Lenkwinkels aus der Dropdownliste aus.
-
Wählen Sie einen Wert in Grad zwischen 1 und 30 für den maximalen Lenkwinkel Ihres Agenten.
-
Wählen Sie aus der Dropdownliste einen Wert für die Granularität der Geschwindigkeit aus.
-
Wählen Sie für die Höchstgeschwindigkeit Ihres Agenten einen Wert in Millimetern pro Sekunde zwischen 0,1 und 4 aus.
-
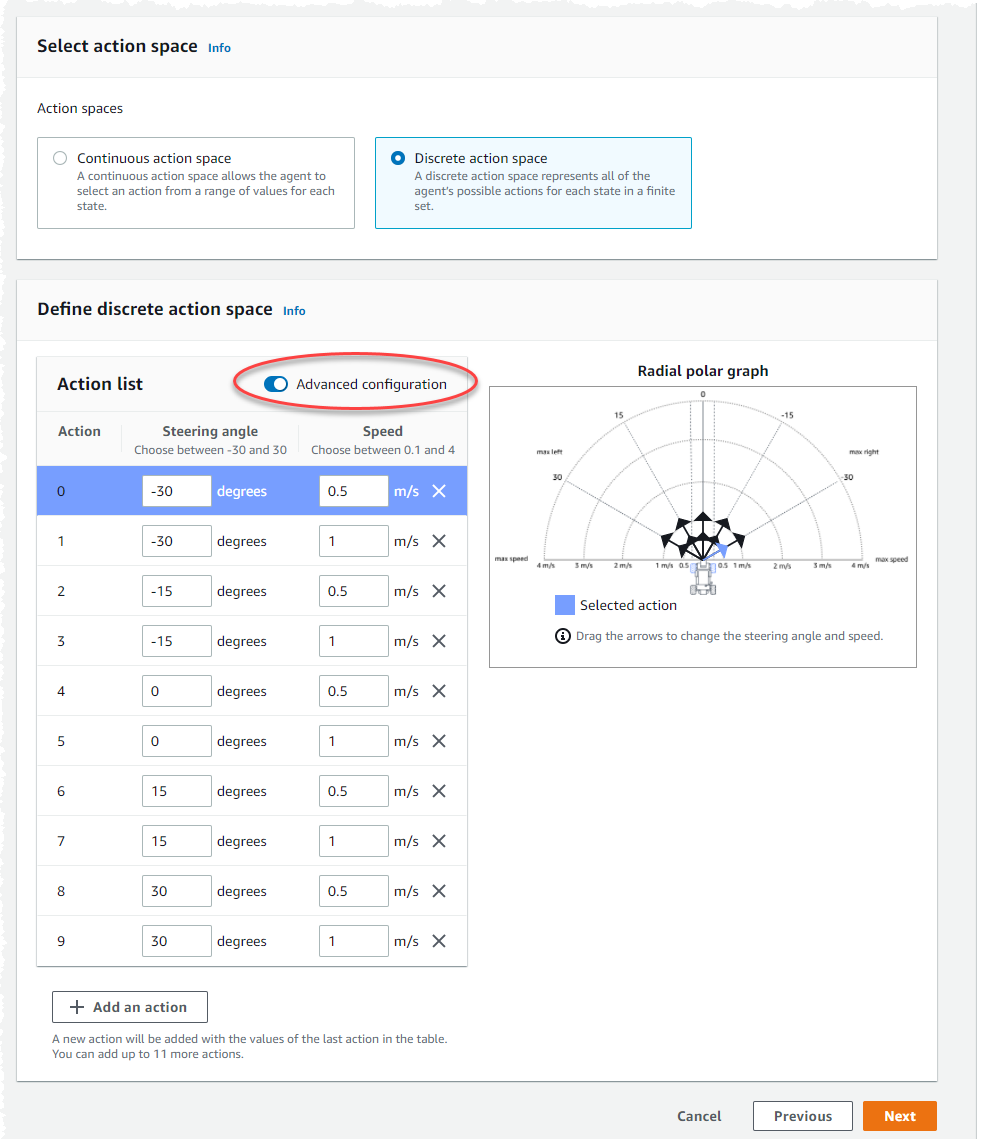
Verwenden Sie die standardmäßigen Aktionseinstellungen in der Aktionsliste oder schalten Sie optional die Option Erweiterte Konfiguration ein, um Ihre Einstellungen zu verfeinern. Wenn Sie „Zurück“ wählen oder „Erweiterte Konfiguration“ deaktivieren, nachdem Sie die Werte angepasst haben, gehen Ihre Änderungen verloren.
-
Geben Sie in der Spalte Lenkwinkel einen Wert in Grad zwischen -30 und 30 ein.
-
Geben Sie in der Spalte Geschwindigkeit einen Wert zwischen 0,1 und 4 in Millimetern pro Sekunde für bis zu neun Aktionen ein.
-
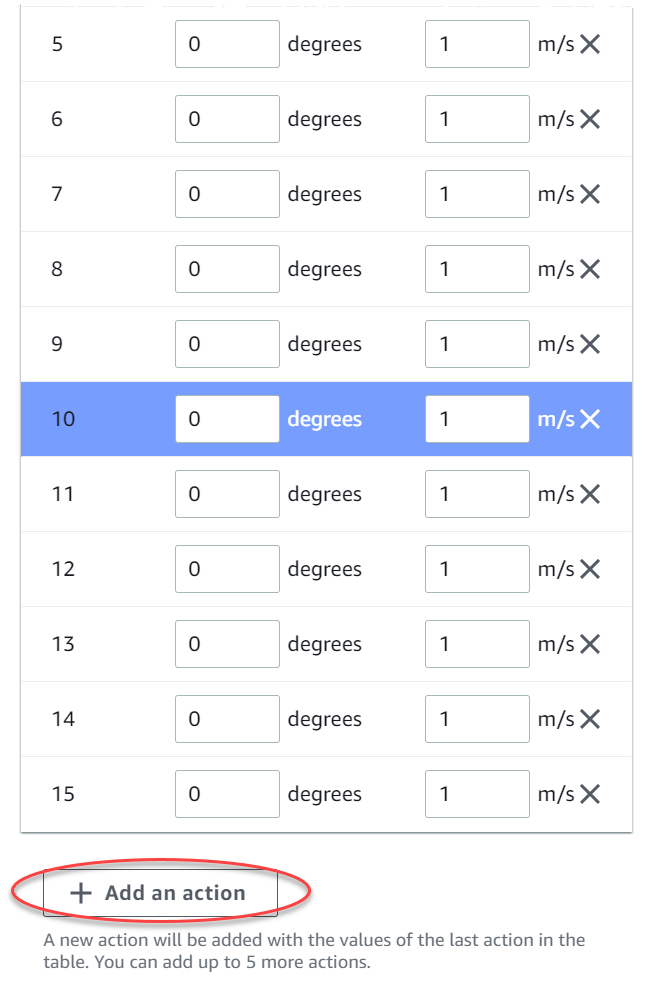
Wählen Sie optional Aktion hinzufügen aus, um die Anzahl der Zeilen in der Aktionsliste zu erhöhen.
-
Wählen Sie optional X in einer Zeile aus, um sie zu entfernen.
-
-
Wählen Sie Weiter.
Wählen Sie ein virtuelles Auto
Erfahren Sie, wie Sie mit virtuellen Autos beginnen können. Verdiene dir jeden Monat neue Custom-Autos, Lackierungen und Modifikationen, indem du in der Open Division antrittst.
Um ein virtuelles Auto auszuwählen
-
Wähle auf der Seite Fahrzeugschale und Sensorkonfiguration auswählen eine Schale aus, die mit deinem Renntyp und deinem Aktionsraum kompatibel ist. Wenn Sie in Ihrer Garage kein passendes Auto haben, gehen Sie im Hauptnavigationsbereich unter der Überschrift Reinforcement-Learning zu Ihrer Garage, um eines zu erstellen.
Für das Zeitfahrtraining benötigen Sie lediglich die Standard-Sensorkonfiguration und die Einlinsen-Kamera von The Original DeepRacer, aber alle anderen Gehäuse und Sensorkonfigurationen funktionieren, solange das Aktionsfeld passt. Weitere Informationen finden Sie unter Maßgeschneiderte DeepRacer AWS-Schulungen für Zeitfahren.
Für das Training zur Objektvermeidung sind Stereokameras hilfreich, aber eine einzelne Kamera kann auch verwendet werden, um stationären Hindernissen an festen Orten auszuweichen. Ein LiDAR-Sensor ist optional. Siehe DeepRacer AWS-Aktionsraum und Belohnungsfunktion.
Für das ead-to-botH-Training eignet sich neben einer Einzelkamera oder einer Stereokamera auch eine LiDAR-Einheit optimal, um tote Winkel zu erkennen und zu vermeiden, wenn Sie an anderen fahrenden Fahrzeugen vorbeifahren. Weitere Informationen hierzu finden Sie unter Maßgeschneiderte DeepRacer AWS-Schulungen für head-to-bot Rennen.
-
Wählen Sie Weiter.
Passen Sie Ihre Belohnungsfunktion an
Die Belohnungsfunktion ist das Herzstück von Reinforcement Learning. Lernen Sie, sie zu nutzen, um Ihrem Auto (Agenten) Anreize zu geben, bestimmte Maßnahmen zu ergreifen, während es die Strecke (Umgebung) erkundet. Sie können dieses Tool verwenden, um Ihr Auto zu ermutigen, eine Runde so schnell wie möglich zu beenden und es davon abzuhalten, von der Strecke abzukommen oder mit Objekten zu kollidieren.
So passen Sie Ihre Belohnungsfunktion an
-
Verwenden Sie auf der Seite Create model (Modell erstellen) unter Reward function (Belohnungsfunktion) das Standard-Belohnungsfunktionsbeispiel für Ihr erstes Modell unverändert.
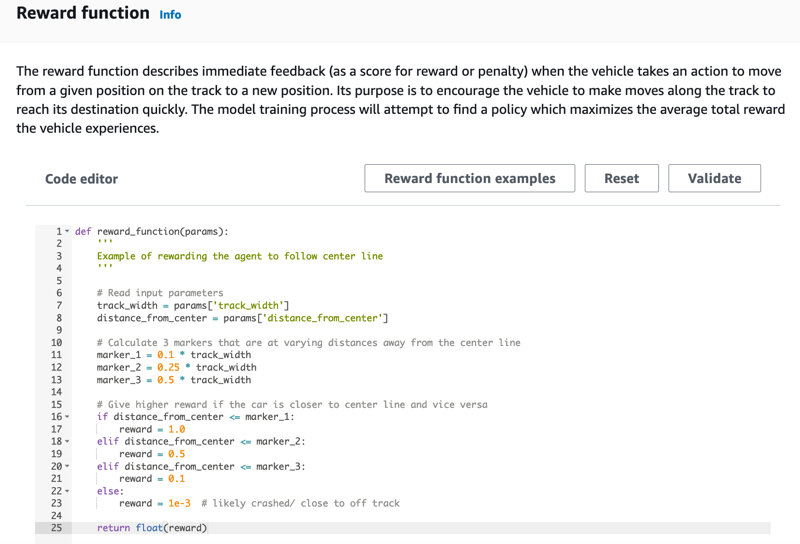
Später können Sie Reward function examples (Belohnungsfunktionsbeispiele) wählen, um eine andere Beispielfunktion auszuwählen und dann Use code (Code verwenden), um die ausgewählte Belohnungsfunktion zu akzeptieren.
Es gibt vier Beispielfunktionen, mit denen Sie beginnen können. Sie veranschaulichen, wie man der Gleismitte folgt (Standard), wie man den Agenten innerhalb der Gleisgrenzen hält, wie man Zick-Zack-Fahrten verhindert und wie man verhindert, dass man gegen stehende Hindernisse oder andere fahrende Fahrzeuge stößt.
Weitere Informationen zur Belohnungsfunktion finden Sie unter Referenz zur DeepRacer AWS-Prämienfunktion.
-
Lassen Sie unter Stoppbedingungen den Standardwert für maximale Zeit unverändert, oder legen Sie einen neuen Wert fest, um den Trainingsjob zu beenden, um zu verhindern, dass lange andauernde (und möglicherweise unkontrollierte) Trainingsjobs laufen.
Beim Experimentieren in der frühen Phase des Trainings sollten Sie mit einem kleinen Wert für diesen Parameter beginnen und dann das Training schrittweise verlängern.
-
Unter Automatisch an AWS einreichen DeepRacer, Dieses Modell nach Abschluss der Schulung DeepRacer automatisch an AWS senden und die Möglichkeit haben, Preise zu gewinnen, ist standardmäßig aktiviert. Optional können Sie sich von der Teilnahme an Ihrem Modell abmelden, indem Sie das Häkchen anklicken.
-
Wählen Sie unter Liga-Anforderungen Ihr Wohnsitzland aus und akzeptieren Sie die Allgemeinen Geschäftsbedingungen, indem Sie das Kästchen ankreuzen.
-
Wählen Sie Modell erstellen, um mit der Erstellung des Modells und der Bereitstellung der Trainingsjob-Instanz zu beginnen.
-
Achten Sie nach der Übermittlung darauf, dass der Schulungsauftrag initialisiert und anschließend ausgeführt wird.
Es dauert einige Minuten, bis der Initialisierungsvorgang von Initialisierung zu In Bearbeitung wechselt.
-
In Reward graph (Belohnungsdiagramm) und Simulation video stream (Simulationsvideo-Stream) können Sie den Fortschritt der Trainingsaufgabe beobachten. Sie können regelmäßig die Aktualisierungsschaltfläche neben Reward graph (Belohnungsdiagramm) auswählen, um Reward graph (Belohnungsdiagramm) zu aktualisieren, bis die Trainingsaufgabe beendet ist.
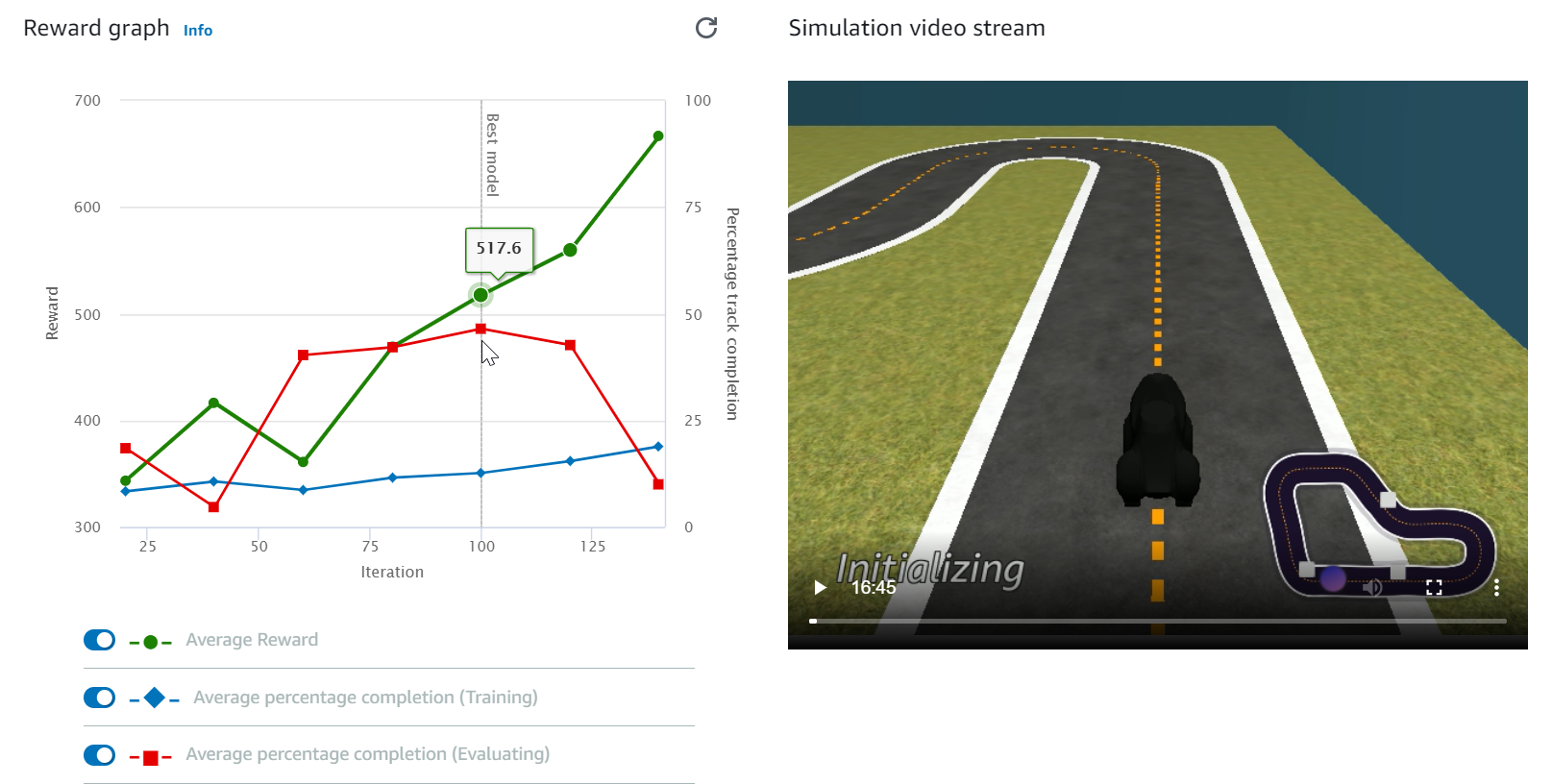
Der Trainingsjob wird in der AWS Cloud ausgeführt, sodass Sie die DeepRacer AWS-Konsole nicht geöffnet lassen müssen. Sie können jederzeit zur Konsole zurückkehren, um Ihr Modell zu überprüfen, während der Job ausgeführt wird.
Wenn das Simulationsvideostream-Fenster oder die Anzeige des Prämiendiagramms nicht mehr reagieren, aktualisieren Sie die Browserseite, um den Trainingsfortschritt zu aktualisieren.
