Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren von Daten aus PostgreSQL-Datenbanken mit homogenen Datenmigrationen in AWS DMS
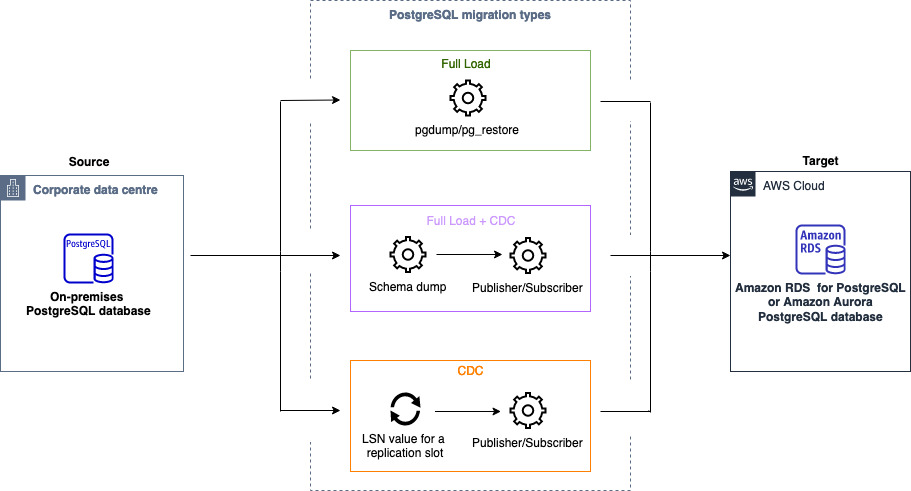
Sie können Homogene Datenbankmigrationen verwenden, um eine selbstverwaltete PostgreSQL-Datenbank zu RDS für MySQL oder Aurora MySQL zu migrieren. AWS DMS erstellt eine Serverless-Umgebung für Ihre Datenmigration. Für verschiedene Arten von Datenmigrationen verwendet AWS DMS verschiedene native PostgreSQL-Datenbanktools.
AWS DMS Verwendet bei homogenen Datenmigrationen vom Typ Volllast pg_dump, um Daten aus Ihrer Quelldatenbank zu lesen und sie auf der Festplatte zu speichern, die an die serverlose Umgebung angeschlossen ist. Nachdem alle Ihre Quelldaten AWS DMS gelesen wurden, verwendet es pg_restore in der Zieldatenbank, um Ihre Daten wiederherzustellen.
Wird bei homogenen Datenmigrationen vom Typ Full Load and Change Data Capture (CDC) AWS DMS verwendet, pg_dump um Schemaobjekte ohne Tabellendaten aus Ihrer Quelldatenbank zu lesen und sie auf der Festplatte zu speichern, die an die serverlose Umgebung angeschlossen ist. Anschließend werden Ihre pg_restore Schemaobjekte in der Zieldatenbank wiederhergestellt. Nach AWS DMS Abschluss des pg_restore Vorgangs wechselt es automatisch zu einem Herausgeber- und Abonnentenmodell für die logische Replikation mit der Initial Data Synchronization Option, die ursprünglichen Tabellendaten direkt von der Quelldatenbank in die Zieldatenbank zu kopieren, und initiiert dann die fortlaufende Replikation. Bei diesem Modell abonnieren ein oder mehrere Subscriber eine oder mehrere Veröffentlichungen auf einem Publisher-Knoten.
Für homogene Datenmigrationen vom Typ Change Data Capture (CDC) ist der native Startpunkt AWS DMS erforderlich, um die Replikation zu starten. Wenn Sie den systemeigenen Startpunkt angeben, werden die Änderungen von diesem Punkt aus AWS DMS erfasst. Wählen Sie alternativ in den Datenmigrationseinstellungen die Option Sofort aus, um den Startpunkt für die Replikation automatisch zu erfassen, wenn die eigentliche Datenmigration beginnt.
Anmerkung
Damit eine reine CDC-Migration ordnungsgemäß funktioniert, müssen alle Quelldatenbankschemata und -objekte bereits in der Zieldatenbank vorhanden sein. Das Ziel kann jedoch Objekte enthalten, die in der Quelle nicht vorhanden sind.
Sie können das folgende Codebeispiel verwenden, um den systemeigenen Startpunkt in Ihrer PostgreSQL-Datenbank abzurufen.
select confirmed_flush_lsn from pg_replication_slots where slot_name=‘migrate_to_target';
Diese Abfrage verwendet die pg_replication_slots-Ansicht in Ihrer PostgreSQL-Datenbank, um den LSN-Wert (Log Sequence Number) zu erfassen.
Nachdem AWS DMS Sie den Status Ihrer homogenen PostgreSQL-Datenmigration auf Gestoppt, Fehlgeschlagen oder Gelöscht gesetzt haben, werden der Herausgeber und die Replikation nicht entfernt. Wenn Sie die Migration nicht fortsetzen möchten, löschen Sie den Replikationsslot und den Publisher mithilfe des folgenden Befehls.
SELECT pg_drop_replication_slot('migration_subscriber_{ARN}'); DROP PUBLICATION publication_{ARN};
Das folgende Diagramm zeigt den Prozess der Verwendung homogener Datenmigrationen AWS DMS zur Migration einer PostgreSQL-Datenbank nach RDS für PostgreSQL oder Aurora PostgreSQL.
Bewährte Methoden für die Verwendung einer PostgreSQL-Datenbank als Quelle für homogene Datenmigrationen
Um die anfängliche Datensynchronisierung auf Abonnentenseite für die FLCDC-Aufgabe zu beschleunigen, müssen Sie und anpassen.
max_logical_replication_workersmax_sync_workers_per_subscriptionWenn Sie diese Werte erhöhen, wird die Geschwindigkeit der Tabellensynchronisierung erhöht.max_logical_replication_workers — Gibt die maximale Anzahl logischer Replikationsworker an. Dazu gehören sowohl die Apply-Worker auf Abonnentenseite als auch die Workers für die Tabellensynchronisation.
max_sync_workers_per_subscription — Eine Erhöhung wirkt sich
max_sync_workers_per_subscriptionnur auf die Anzahl der Tabellen aus, die parallel synchronisiert werden, nicht auf die Anzahl der Worker pro Tabelle.
Anmerkung
max_logical_replication_workerssollte nicht überschreitenmax_worker_processesund sollte kleiner oder gleich sein.max_sync_workers_per_subscriptionmax_logical_replication_workersBei der Migration großer Tabellen sollten Sie erwägen, diese mithilfe von Auswahlregeln in separate Aufgaben aufzuteilen. Sie können beispielsweise große Tabellen in separate Einzelaufgaben und kleine Tabellen in eine weitere einzelne Aufgabe unterteilen.
Überwachen Sie die Festplatten- und CPU-Auslastung auf Abonnentenseite, um eine optimale Leistung zu gewährleisten.
