Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Theorie der Kubernetes-Skalierung
Nodes im Vergleich zur Abwanderungsrate
Wenn wir über die Skalierbarkeit von Kubernetes sprechen, beziehen wir uns oft darauf, wie viele Knoten es in einem einzelnen Cluster gibt. Interessanterweise ist dies selten die nützlichste Metrik, um die Skalierbarkeit zu verstehen. Beispielsweise würde ein 5.000-Knoten-Cluster mit einer großen, aber festen Anzahl von Pods die Steuerungsebene nach der ersten Einrichtung nicht stark stress. Wenn wir jedoch einen Cluster mit 1.000 Knoten nehmen und versuchen würden, in weniger als einer Minute 10.000 kurzlebige Arbeitsplätze zu schaffen, würde das die Kontrollebene nachhaltig unter Druck setzen.
Es kann irreführend sein, einfach die Anzahl der Knoten zu verwenden, um die Skalierung zu verstehen. Es ist besser, in Bezug auf die Änderungsrate zu denken, die innerhalb eines bestimmten Zeitraums stattfindet (verwenden wir für diese Diskussion ein 5-Minuten-Intervall, da dies normalerweise standardmäßig in Prometheus-Abfragen verwendet wird). Lassen Sie uns untersuchen, warum wir, wenn wir das Problem anhand der Änderungsrate eingrenzen, eine bessere Vorstellung davon bekommen, was wir anpassen müssen, um den gewünschten Umfang zu erreichen.
Denken Sie in Abfragen pro Sekunde
Kubernetes verfügt über eine Reihe von Schutzmechanismen für jede Komponente — Kubelet, Scheduler, Kube Controller Manager und API-Server —, um zu verhindern, dass das nächste Glied in der Kubernetes-Kette überlastet wird. Kubelet verfügt beispielsweise über ein Flag, mit dem Aufrufe an den API-Server mit einer bestimmten Geschwindigkeit gedrosselt werden. Diese Schutzmechanismen werden im Allgemeinen, aber nicht immer, in Form von Abfragen ausgedrückt, die pro Sekunde erlaubt sind, oder QPS.
Bei der Änderung dieser QPS-Einstellungen ist große Vorsicht geboten. Die Beseitigung eines Engpasses, z. B. der Abfragen pro Sekunde auf einem Kubelet, hat Auswirkungen auf andere nachgelagerte Komponenten. Dies kann und wird das System ab einer bestimmten Geschwindigkeit überfordern. Daher ist es entscheidend, jeden Teil der Servicekette zu verstehen und zu überwachen, um Workloads auf Kubernetes erfolgreich zu skalieren.
Anmerkung
Der API-Server verfügt über ein komplexeres System mit der Einführung von API-Priorität und Fairness, auf die wir separat eingehen werden.
Anmerkung
Vorsicht, einige Metriken scheinen die richtige Wahl zu sein, messen aber in Wirklichkeit etwas anderes. kubelet_http_inflight_requestsBezieht sich beispielsweise nur auf den Metrikserver in Kubelet, nicht auf die Anzahl der Anfragen von Kubelet an Apiserver-Anfragen. Dies könnte dazu führen, dass wir das QPS-Flag auf dem Kubelet falsch konfigurieren. Eine Abfrage von Audit-Logs für ein bestimmtes Kubelet wäre eine zuverlässigere Methode, um Metriken zu überprüfen.
Skalierung verteilter Komponenten
Da EKS ein verwalteter Service ist, teilen wir die Kubernetes-Komponenten in zwei Kategorien auf: AWS-verwaltete Komponenten, zu denen etcd, Kube Controller Manager und der Scheduler gehören (im linken Teil des Diagramms), und vom Kunden konfigurierbare Komponenten wie Kubelet, Container Runtime und die verschiedenen Operatoren, die AWS aufrufen, APIs wie die Netzwerk- und Speichertreiber (im rechten Teil des Diagramms). Wir belassen den API-Server in der Mitte, obwohl er von AWS verwaltet wird, da die Einstellungen für API-Priorität und Fairness von Kunden konfiguriert werden können.
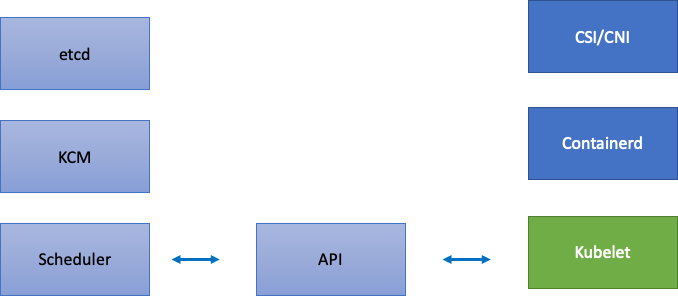
Engpässe im Upstream- und Downstream-Bereich
Bei der Überwachung der einzelnen Services ist es wichtig, Metriken in beide Richtungen zu betrachten, um nach Engpässen zu suchen. Lassen Sie uns am Beispiel von Kubelet lernen, wie das geht. Kubelet kommuniziert sowohl mit dem API-Server als auch mit der Container-Laufzeit. Wie und was müssen wir überwachen, um festzustellen, ob bei einer der Komponenten ein Problem auftritt?
Wie viele Pods pro Knoten
Wenn wir uns Skalierungszahlen ansehen, z. B. wie viele Pods auf einem Knoten ausgeführt werden können, könnten wir die 110 Pods pro Knoten, die Upstream unterstützt, für bare Münze nehmen.
Ihr Workload ist jedoch wahrscheinlich komplexer als das, was in einem Skalierbarkeitstest in Upstream getestet wurde. Um sicherzustellen, dass wir die Anzahl der Pods, die wir in der Produktion ausführen möchten, bedienen können, sollten wir sicherstellen, dass das Kubelet mit der Containerd-Laufzeit „Schritt hält“.
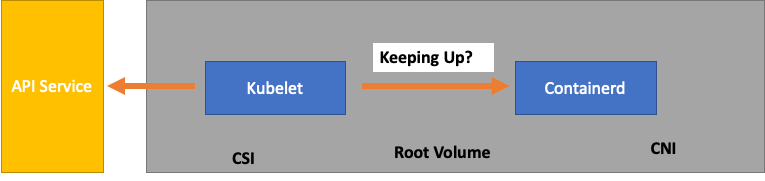
Der Einfachheit halber erhält das Kubelet den Status der Pods aus der Container-Laufzeit (in unserem Fall Containerd). Was wäre, wenn wir zu viele Pods hätten, die ihren Status zu schnell ändern würden? Wenn die Änderungsrate zu hoch ist, kann es bei Anfragen [an die Container-Laufzeit] zu einem Timeout kommen.
Anmerkung
Kubernetes entwickelt sich ständig weiter, dieses Subsystem wird derzeit geändert. https://github.com/kubernetes/Erweiterungen/Probleme/3386

In der obigen Grafik sehen wir eine flache Linie, die angibt, dass wir gerade den Timeout-Wert für die Metrik für die Dauer der Generierung von Pod-Lebenszyklus-Ereignissen erreicht haben. Wenn Sie dies in Ihrem eigenen Cluster sehen möchten, könnten Sie die folgende PromQL-Syntax verwenden.
increase(kubelet_pleg_relist_duration_seconds_bucket{instance="$instance"}[$__rate_interval])
Wenn wir dieses Timeout-Verhalten beobachten, wissen wir, dass wir den Knoten über das Limit gebracht haben, zu dem er fähig war. Wir müssen die Ursache des Timeouts beheben, bevor wir weitermachen können. Dies könnte erreicht werden, indem die Anzahl der Pods pro Knoten reduziert oder nach Fehlern gesucht wird, die möglicherweise zu einer hohen Anzahl von Wiederholungsversuchen führen (was sich auf die Abwanderungsrate auswirkt). Die wichtige Erkenntnis ist, dass Metriken der beste Weg sind, um zu verstehen, ob ein Knoten in der Lage ist, die Abwanderungsrate der zugewiesenen Pods im Vergleich zur Verwendung einer festen Anzahl zu bewältigen.
Skalieren nach Metriken
Das Konzept, Metriken zur Systemoptimierung zu verwenden, ist zwar alt, wird aber zu Beginn der Kubernetes-Reise oft übersehen. Anstatt uns auf bestimmte Zahlen zu konzentrieren (d. h. 110 Pods pro Knoten), konzentrieren wir uns darauf, die Metriken zu finden, die uns helfen, Engpässe in unserem System zu finden. Wenn wir die richtigen Schwellenwerte für diese Metriken kennen, können wir uns darauf verlassen, dass unser System optimal konfiguriert ist.
Die Auswirkungen von Änderungen
Ein häufiges Muster, das uns in Schwierigkeiten bringen könnte, besteht darin, uns auf den ersten Metrik- oder Protokollfehler zu konzentrieren, der verdächtig aussieht. Als wir sahen, dass das Kubelet früher eine Zeitüberschreitung hatte, konnten wir zufällige Dinge ausprobieren, wie zum Beispiel die Rate pro Sekunde zu erhöhen, die das Kubelet senden darf, usw. Es ist jedoch ratsam, sich das Gesamtbild von allem anzusehen, was hinter dem Fehler liegt, den wir zuerst finden. Nehmen Sie jede Änderung zielgerichtet und datengestützt vor.
Dem Kubelet nachgeschaltet wäre die Containerd-Runtime (Pod-Fehler), DaemonSets wie z. B. der Speichertreiber (CSI) und der Netzwerktreiber (CNI), die mit der API kommunizieren, usw. EC2
Lassen Sie uns unser früheres Beispiel fortsetzen, bei dem Kubelet nicht mit der Laufzeit Schritt hält. Es gibt eine Reihe von Punkten, an denen wir einen Knoten so dicht zusammenpacken könnten, dass er Fehler auslöst.
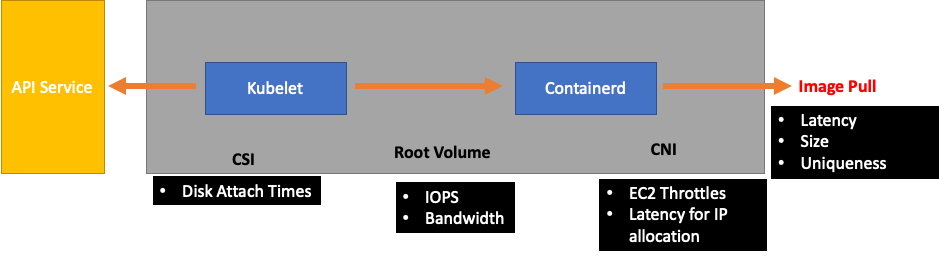
Bei der Entwicklung der richtigen Knotengröße für unsere Workloads sind dies easy-to-overlook Signale, die das System möglicherweise unnötig belasten und so sowohl unseren Umfang als auch unsere Leistung einschränken.
Die Kosten unnötiger Fehler
Kubernetes-Controller zeichnen sich durch Wiederholungsversuche aus, wenn Fehler auftreten. Dies ist jedoch mit Kosten verbunden. Diese erneuten Versuche können den Druck auf Komponenten wie den Kube Controller Manager erhöhen. Es ist ein wichtiger Bestandteil von Skalentests, solche Fehler zu erkennen.
Wenn weniger Fehler auftreten, ist es einfacher, Probleme im System zu erkennen. Indem wir regelmäßig sicherstellen, dass unsere Cluster vor größeren Vorgängen (wie Upgrades) fehlerfrei sind, können wir die Fehlerbehebung bei unvorhergesehenen Ereignissen vereinfachen.
Wir erweitern unsere Sichtweise
In großen Clustern mit 1.000 Knoten möchten wir nicht einzeln nach Engpässen suchen. In PromQL können wir mithilfe einer Funktion namens topk die höchsten Werte in einem Datensatz ermitteln. K ist eine Variable und wir platzieren die Anzahl der gewünschten Elemente. Hier verwenden wir drei Knoten, um eine Vorstellung davon zu bekommen, ob alle Kubelets im Cluster gesättigt sind. Wir haben uns bis zu diesem Zeitpunkt mit der Latenz befasst. Lassen Sie uns nun sehen, ob das Kubelet Ereignisse verwirft.
topk(3, increase(kubelet_pleg_discard_events{}[$__rate_interval]))
Diese Aussage aufschlüsseln.
-
Wir verwenden die Grafana-Variable
$__rate_interval, um sicherzustellen, dass sie die vier benötigten Stichproben erhält. Dadurch wird ein komplexes Thema beim Monitoring mit einer einfachen Variablen umgangen. -
topkgeben Sie uns nur die besten Ergebnisse und die Zahl 3 begrenzt diese Ergebnisse auf drei. Dies ist eine nützliche Funktion für clusterweite Metriken. -
{}sagen Sie uns, dass es keine Filter gibt. Normalerweise würden Sie den Jobnamen unabhängig von der Scraping-Regel eingeben. Da diese Namen jedoch variieren, lassen wir das Feld leer.
Das Problem in zwei Hälften teilen
Um einen Engpass im System zu beheben, verfolgen wir den Ansatz, eine Metrik zu finden, die uns zeigt, dass vor- oder nachgelagerte Probleme vorliegen, da wir das Problem auf diese Weise in zwei Hälften teilen können. Dies wird auch ein zentraler Grundsatz dafür sein, wie wir unsere Metrikdaten anzeigen.
Ein guter Ausgangspunkt für diesen Prozess ist der API-Server, da wir so feststellen können, ob ein Problem mit einer Client-Anwendung oder der Control Plane vorliegt.
