Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Effizienz von Knoten und Workloads
Wenn wir effizient mit unseren Workloads und Nodes umgehen, reduzieren wir complexity/cost gleichzeitig die Leistung und Skalierbarkeit. Bei der Planung dieser Effizienz müssen viele Faktoren berücksichtigt werden, und es ist am einfachsten, Kompromisse im Vergleich zu einer Best-Practice-Einstellung für jede Funktion in Betracht zu ziehen. Lassen Sie uns diese Kompromisse im folgenden Abschnitt eingehend untersuchen.
Knotenauswahl
Durch die Verwendung etwas größerer Knoten (4-12x) wird der verfügbare Speicherplatz für die Ausführung von Pods erhöht, da dadurch der Prozentsatz des Knotens reduziert wird, der für „Overhead“ DaemonSets
Anmerkung
Da k8s in der Regel horizontal skaliert wird, ist es für die meisten Anwendungen nicht sinnvoll, die Auswirkungen auf die Leistung von Knoten der NUMA-Größe zu berücksichtigen, weshalb ein Bereich unterhalb dieser Knotengröße empfohlen wird.
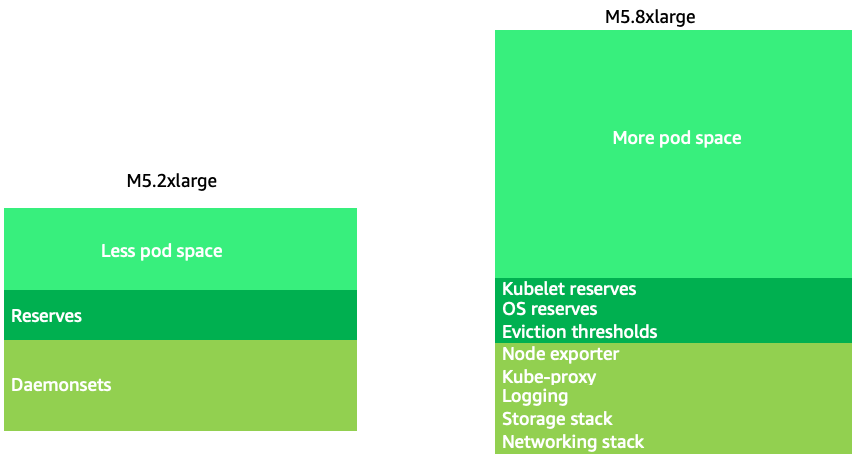
Große Knoten ermöglichen uns einen höheren Prozentsatz an nutzbarem Speicherplatz pro Knoten. Dieses Modell kann jedoch auf die Spitze getrieben werden, indem der Knoten mit so vielen Pods ausgestattet wird, dass dadurch Fehler auftreten oder der Knoten überlastet wird. Die Überwachung der Knotensättigung ist der Schlüssel zur erfolgreichen Verwendung größerer Knotengrößen.
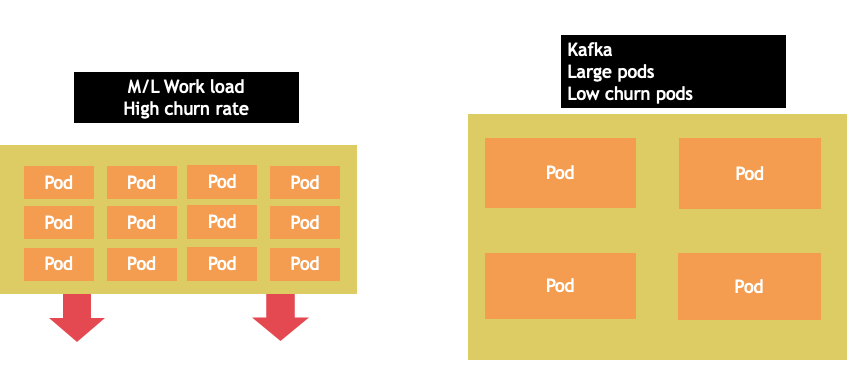
Die Knotenauswahl ist selten ein Patentrezept. Oft ist es am besten, Workloads mit stark unterschiedlichen Abwanderungsraten auf verschiedene Knotengruppen aufzuteilen. Kleine Batch-Workloads mit einer hohen Abwanderungsrate würden am besten von der 4xlarge-Instance-Familie bedient werden, während eine umfangreiche Anwendung wie Kafka, die 8 vCPUs benötigt und eine niedrige Abwanderungsrate aufweist, besser von der 12xlarge-Familie bedient werden könnte.
Anmerkung
Ein weiterer Faktor, der bei sehr großen Knoten berücksichtigt werden muss, ist, dass CGROUPS die Gesamtzahl der vCPUs nicht vor der containerisierten Anwendung verbergen. Dynamische Laufzeiten können oft eine unbeabsichtigte Anzahl von Betriebssystem-Threads erzeugen, was zu einer Latenz führt, die schwer zu beheben ist. Für diese Anwendungen wird CPU-Pinning
Knoten Bin-packing
Regeln für Kubernetes im Vergleich zu Linux
Es gibt zwei Regelwerke, die wir beim Umgang mit Workloads auf Kubernetes beachten müssen. Die Regeln des Kubernetes-Schedulers, der den Anforderungswert verwendet, um Pods auf einem Knoten zu planen, und dann, was passiert, nachdem der Pod geplant wurde. Das ist der Bereich von Linux, nicht von Kubernetes.
Sobald der Kubernetes-Scheduler fertig ist, übernimmt ein neues Regelwerk, der Linux Completely Fair Scheduler (CFS). Die wichtigste Erkenntnis ist, dass Linux CFS nicht das Konzept eines Kerns hat. Wir werden erörtern, warum das Denken in Kernen zu großen Problemen bei der Skalierung von Workloads führen kann.
In Kernen denken
Die Verwirrung beginnt, weil der Kubernetes-Scheduler das Konzept der Kerne hat. Aus Sicht des Kubernetes-Schedulers würde der Knoten so aussehen, wenn wir uns einen Knoten mit 4 NGINX-Pods ansehen würden, von denen jeder die Anforderung eines Core-Sets hat.
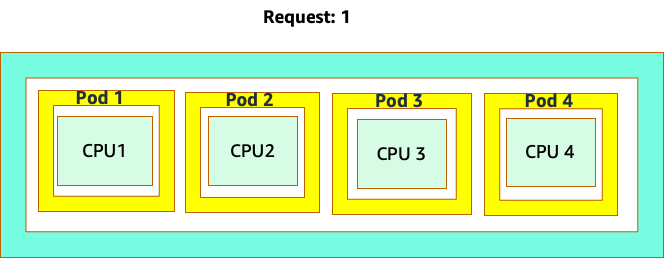
Lassen Sie uns jedoch ein Gedankenexperiment durchführen, um zu untersuchen, wie unterschiedlich das aus einer Linux-CFS-Perspektive aussieht. Das Wichtigste, an das Sie denken sollten, wenn Sie das Linux-CFS-System verwenden, ist: Busy-Container (CGROUPS) sind die einzigen Container, die auf das Share-System angerechnet werden. In diesem Fall ist nur der erste Container ausgelastet, sodass er alle 4 Kerne auf dem Knoten verwenden darf.
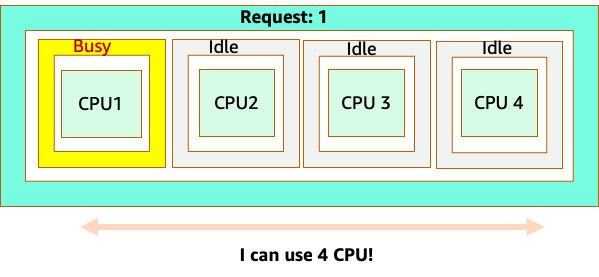
Warum ist das wichtig? Nehmen wir an, wir haben unsere Leistungstests in einem Entwicklungscluster durchgeführt, in dem eine NGINX-Anwendung der einzige ausgelastete Container auf diesem Knoten war. Wenn wir die App in die Produktion verlagern, würde Folgendes passieren: Die NGINX-Anwendung benötigt 4 vCPU-Ressourcen, da jedoch alle anderen Pods auf dem Knoten ausgelastet sind, ist die Leistung unserer App eingeschränkt.
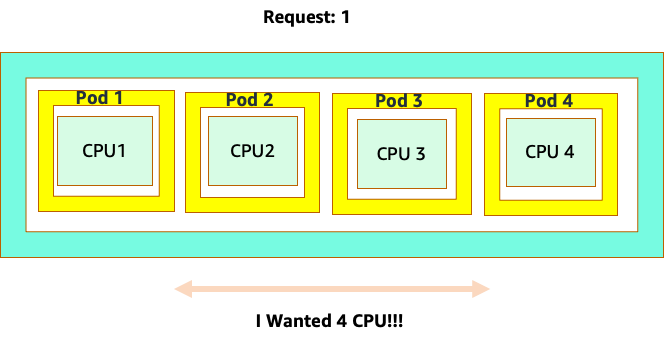
Diese Situation würde dazu führen, dass wir unnötig mehr Container hinzufügen müssten, weil wir nicht zulassen würden, dass unsere Anwendungen nach ihrem „`Sweet Spot“ skaliert werden. Lassen Sie uns dieses wichtige Konzept von a etwas "sweet spot" genauer untersuchen.
Richtige Dimensionierung der Anwendung
Jede Anwendung hat einen bestimmten Punkt, an dem sie keinen Verkehr mehr aufnehmen kann. Eine Überschreitung dieses Punktes kann die Verarbeitungszeiten verlängern und sogar den Datenverkehr verringern, wenn dieser Punkt deutlich überschritten wird. Dieser Wert wird als Sättigungspunkt der Anwendung bezeichnet. Um Skalierungsprobleme zu vermeiden, sollten wir versuchen, die Anwendung zu skalieren, bevor sie ihren Sättigungspunkt erreicht. Nennen wir diesen Punkt den Sweet Spot.
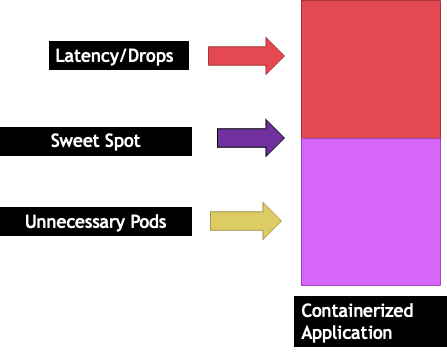
Wir müssen jede unserer Anwendungen testen, um herauszufinden, was für sie am besten geeignet ist. Hier wird es keine allgemeingültige Anleitung geben, da jede Anwendung anders ist. Während dieser Tests versuchen wir, die beste Metrik zu finden, die den Sättigungspunkt unserer Anwendungen angibt. Häufig werden Nutzungskennzahlen verwendet, um anzuzeigen, dass eine Anwendung ausgelastet ist. Dies kann jedoch schnell zu Skalierungsproblemen führen (wir werden dieses Thema in einem späteren Abschnitt ausführlich behandeln). Sobald wir diesen „Sweet Spot“ haben, können wir ihn nutzen, um unsere Workloads effizient zu skalieren.
Was würde umgekehrt passieren, wenn wir weit vor dem Sweet Spot hochskalieren und unnötige Pods erstellen würden? Lassen Sie uns das im nächsten Abschnitt untersuchen.
Ausbreitung der Hülsen
Schauen wir uns das erste Beispiel auf der linken Seite an, um zu sehen, wie das Erstellen unnötiger Pods schnell außer Kontrolle geraten kann. Die korrekte vertikale Skalierung dieses Containers beansprucht etwa zwei vCPUs, wenn 100 Anfragen pro Sekunde verarbeitet werden. Wenn wir jedoch den Wert der Anfragen zu gering bereitstellen würden, indem wir Anfragen auf einen halben Kern setzen, bräuchten wir jetzt 4 Pods für jeden Pod, den wir tatsächlich benötigen. Verschärft wird dieses Problem noch dadurch, dass, wenn unser HPA
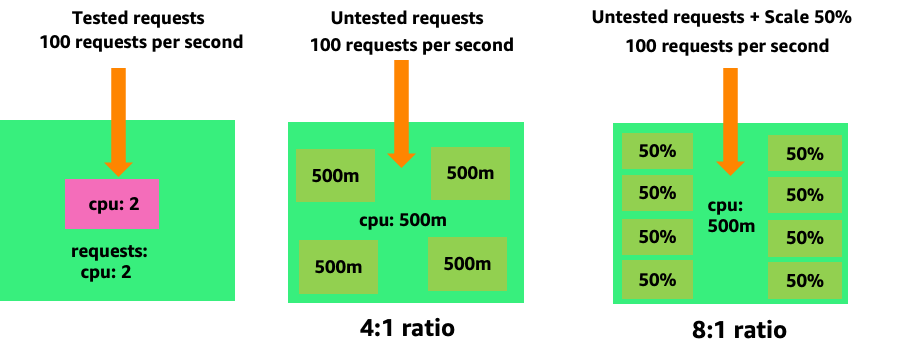
Wenn wir dieses Problem vergrößern, können wir schnell erkennen, wie es außer Kontrolle geraten kann. Eine Bereitstellung von zehn Pods, deren Sweet Spot falsch eingestellt war, könnte schnell zu 80 Pods und der zusätzlichen Infrastruktur führen, die für deren Betrieb erforderlich ist.
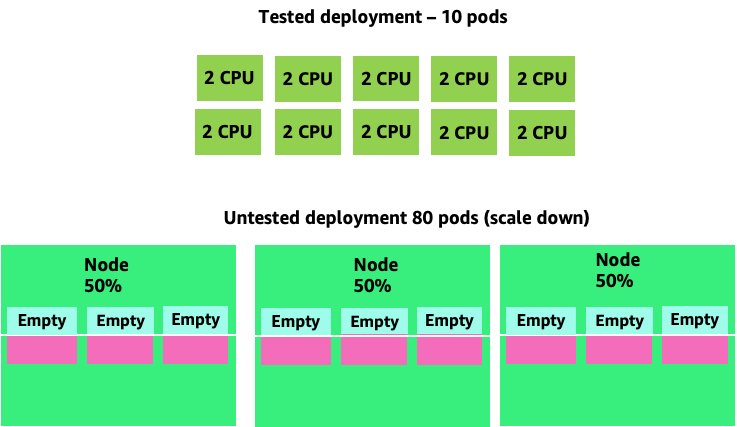
Nachdem wir nun verstanden haben, welche Auswirkungen es hat, wenn Anwendungen nicht in ihrem optimalen Zustand arbeiten können, wollen wir zur Knotenebene zurückkehren und uns fragen, warum dieser Unterschied zwischen dem Kubernetes-Scheduler und Linux CFS so wichtig ist.
Bei der Hoch- und Herunterskalierung mit HPA können wir ein Szenario haben, in dem wir viel Speicherplatz haben, um mehr Pods zuzuweisen. Dies wäre eine schlechte Entscheidung, da der links abgebildete Knoten bereits zu 100% CPU-Auslastung hat. In einem unrealistischen, aber theoretisch möglichen Szenario könnten wir das andere Extrem haben, bei dem unser Knoten vollständig voll ist, unsere CPU-Auslastung jedoch Null ist.
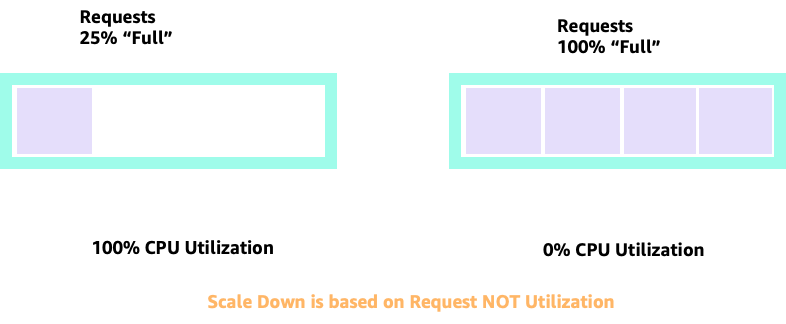
Anfragen einrichten
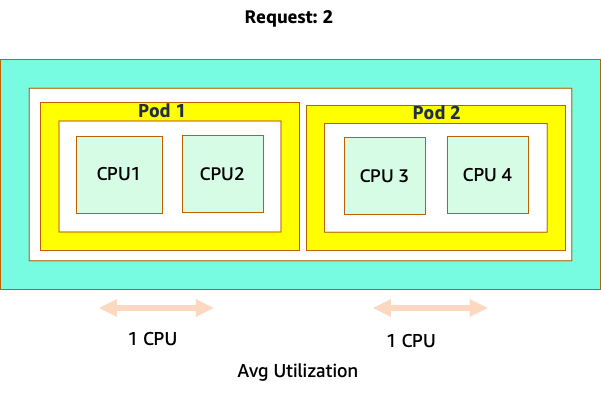
Es wäre verlockend, die Anfrage auf den für diese Anwendung geltenden „Sweet Spot“ -Wert zu setzen. Dies würde jedoch zu Ineffizienzen führen, wie in der Abbildung unten dargestellt. Hier haben wir den Anforderungswert auf 2 vCPU gesetzt, die durchschnittliche Auslastung dieser Pods beträgt jedoch die meiste Zeit nur 1 CPU. Diese Einstellung würde dazu führen, dass wir 50% unserer CPU-Zyklen verschwenden würden, was inakzeptabel wäre.
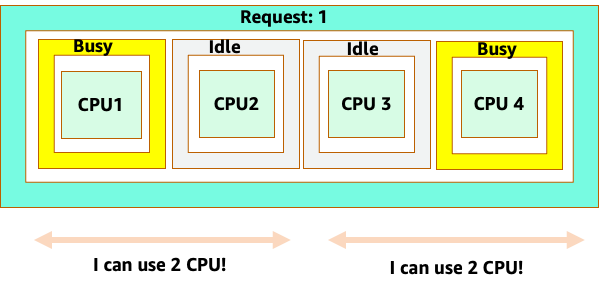
Dies bringt uns zur komplexen Antwort auf das Problem. Die Nutzung von Containern kann nicht im luftleeren Raum betrachtet werden. Man muss die anderen Anwendungen berücksichtigen, die auf dem Knoten ausgeführt werden. Im folgenden Beispiel werden Container, bei denen es sich um Burst-Container handelt, mit zwei Containern mit niedriger CPU-Auslastung vermischt, für die möglicherweise nur wenig Speicherplatz zur Verfügung steht. Auf diese Weise ermöglichen wir es den Containern, ihren optimalen Standort zu erreichen, ohne den Knoten zu belasten.
Das wichtige Konzept, das man aus all dem mitnehmen kann, ist, dass die Verwendung des Kubernetes-Scheduler-Konzepts der Kerne, um die Leistung von Linux-Containern zu verstehen, zu schlechten Entscheidungen führen kann, da sie nicht miteinander verwandt sind.
Anmerkung
Linux CFS hat seine Stärken. Dies gilt insbesondere für I/O basierte Workloads. Wenn Ihre Anwendung jedoch volle Kerne ohne Nebenkosten verwendet und keine I/O Anforderungen gestellt werden, kann CPU-Pinning diesen Prozess erheblich vereinfachen und ist mit diesen Einschränkungen empfehlenswert.
Auslastung versus Sättigung
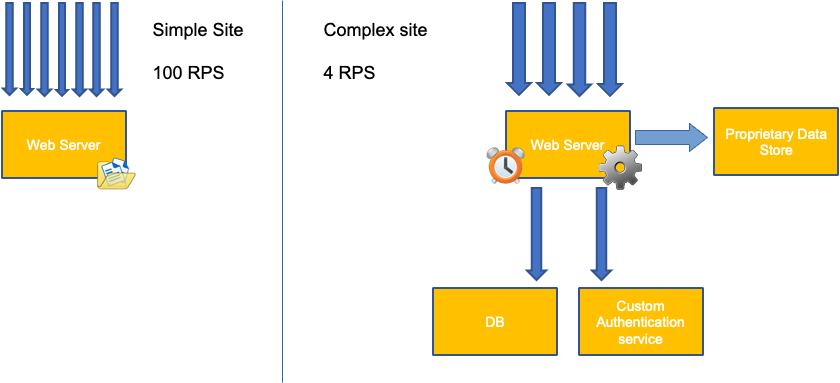
Ein häufiger Fehler bei der Anwendungsskalierung besteht darin, nur die CPU-Auslastung für Ihre Skalierungsmetrik zu verwenden. In komplexen Anwendungen ist dies fast immer ein schlechter Indikator dafür, dass eine Anwendung tatsächlich mit Anfragen überlastet ist. Im Beispiel auf der linken Seite sehen wir, dass alle unsere Anfragen tatsächlich den Webserver erreichen, sodass die CPU-Auslastung mit der Sättigung gut abschneidet.
In realen Anwendungen ist es wahrscheinlich, dass einige dieser Anfragen von einer Datenbankschicht oder einer Authentifizierungsebene usw. bearbeitet werden. In diesem häufigeren Fall stellen Sie fest, dass die CPU die Nachverfolgung nicht voll ausgelastet hat, da die Anfrage von anderen Entitäten bearbeitet wird. In diesem Fall ist die CPU ein sehr schlechter Indikator für die Sättigung.
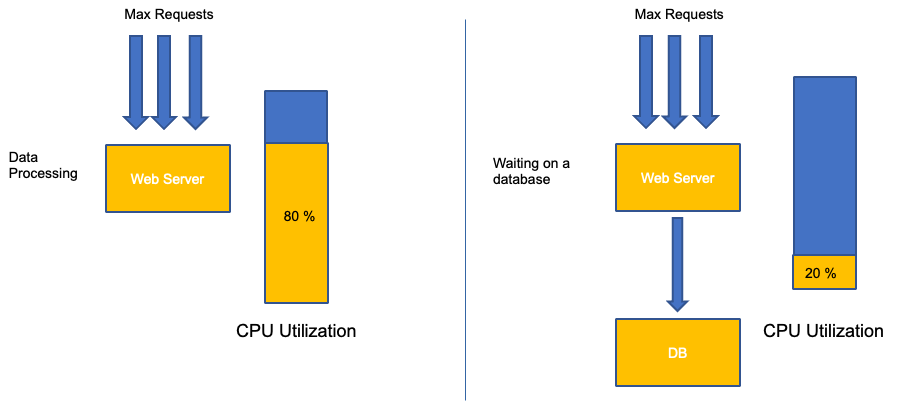
Die Verwendung der falschen Metrik bei der Anwendungsleistung ist der Hauptgrund für unnötige und unvorhersehbare Skalierung in Kubernetes. Bei der Auswahl der richtigen Sättigungsmetrik für die Art der Anwendung, die Sie verwenden, ist große Vorsicht geboten. Es ist wichtig zu beachten, dass es keine allgemeingültige Empfehlung gibt, die für alle geeignet ist. Abhängig von der verwendeten Sprache und der Art der jeweiligen Anwendung gibt es unterschiedliche Messwerte für die Sättigung.
Wir denken vielleicht, dass dieses Problem nur bei der CPU-Auslastung liegt, aber auch andere gängige Messwerte wie die Anfrage pro Sekunde können auf genau das gleiche Problem zurückzuführen sein, das oben erörtert wurde. Beachten Sie, dass die Anfrage auch auf DB-Ebenen oder Authentifizierungsebenen gehen kann und nicht direkt von unserem Webserver bedient wird. Daher ist sie eine schlechte Metrik für die tatsächliche Auslastung des Webservers selbst.
Leider gibt es keine einfachen Antworten, wenn es darum geht, die richtige Sättigungsmetrik auszuwählen. Hier sind einige Richtlinien, die Sie berücksichtigen sollten:
-
Verstehen Sie Ihre Sprache Runtime — Sprachen mit mehreren Betriebssystem-Threads reagieren anders als Single-Thread-Anwendungen und wirken sich daher unterschiedlich auf den Knoten aus.
-
Machen Sie sich mit der korrekten vertikalen Skala vertraut — wie viel Puffer benötigen Sie für die vertikale Skalierung Ihrer Anwendungen, bevor Sie einen neuen Pod skalieren?
-
Welche Metriken spiegeln wirklich die Sättigung Ihrer Anwendung wider? — Die Sättigungsmetrik für einen Kafka Producer wäre etwas ganz anderes als für eine komplexe Webanwendung.
-
Wie wirken sich alle anderen Anwendungen auf dem Knoten gegenseitig aus? Die Anwendungsleistung erfolgt nicht im luftleeren Raum, die anderen Workloads auf dem Knoten haben erhebliche Auswirkungen.
Um diesen Abschnitt abzuschließen, wäre es leicht, die obigen Ausführungen als zu komplex und unnötig abzutun. Es kann oft vorkommen, dass wir ein Problem haben, uns aber der wahren Natur des Problems nicht bewusst sind, weil wir die falschen Messwerte verwenden. Im nächsten Abschnitt werden wir uns ansehen, wie das passieren könnte.
Knotensättigung
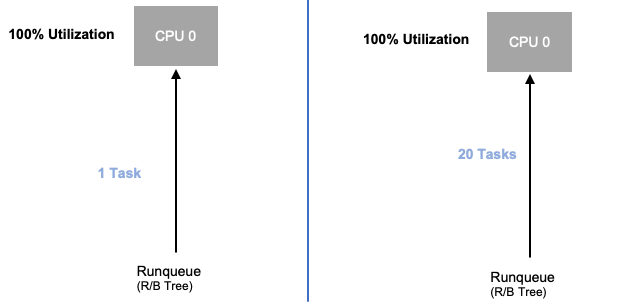
Nachdem wir uns nun mit der Anwendungssättigung befasst haben, wollen wir dasselbe Konzept aus der Sicht der Knoten betrachten. Schauen wir uns zwei CPUs an, die zu 100% ausgelastet sind, um den Unterschied zwischen Auslastung und Sättigung zu erkennen.
Die vCPU auf der linken Seite ist zu 100% ausgelastet, es warten jedoch keine anderen Aufgaben darauf, auf dieser vCPU ausgeführt zu werden. Aus rein theoretischer Sicht ist dies also ziemlich effizient. In der Zwischenzeit warten im zweiten Beispiel 20 Single-Thread-Anwendungen darauf, von einer vCPU verarbeitet zu werden. Bei allen 20 Anwendungen kommt es jetzt zu einer gewissen Latenz, während sie darauf warten, dass sie an der Reihe sind, von der vCPU verarbeitet zu werden. Mit anderen Worten, die vCPU auf der rechten Seite ist gesättigt.
Wir würden dieses Problem nicht nur nicht sehen, wenn wir uns nur die Auslastung ansehen würden, sondern wir könnten diese Latenz auch auf etwas zurückführen, das nichts damit zu tun hat, wie z. B. Netzwerke, was uns auf den falschen Weg führen würde.
Wenn die Gesamtzahl der Pods erhöht wird, die zu einem bestimmten Zeitpunkt auf einem Knoten ausgeführt werden, ist es wichtig, die Sättigungsmetriken und nicht nur die Nutzungsmetriken zu betrachten, da wir leicht übersehen können, dass ein Knoten überlastet ist. Für diese Aufgabe können wir Messwerte zur Information über den Druckausfall verwenden, wie in der folgenden Tabelle dargestellt.
PromQL — Blockiert I/O
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
Anmerkung
Weitere Informationen zu Messwerten zum Stillstand bei Druckausfällen finden Sie unter* https://facebookmicrosites.github.io/psi/docs/overview
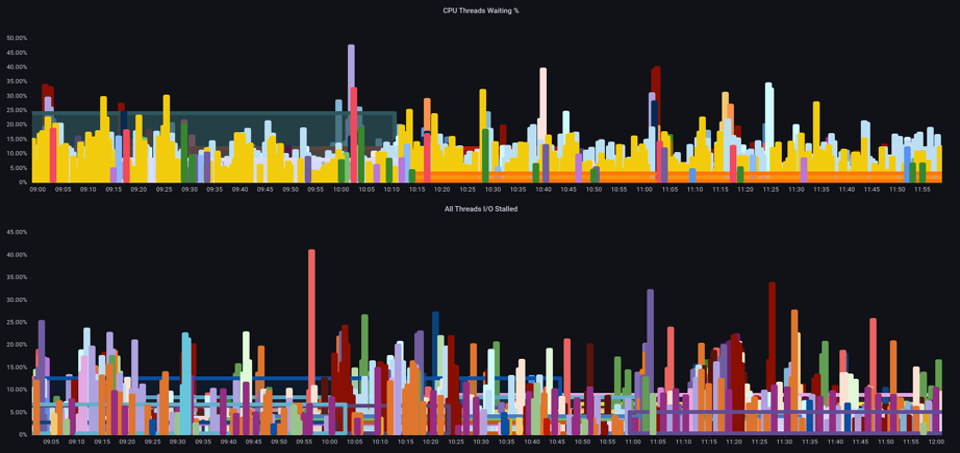
Anhand dieser Metriken können wir feststellen, ob Threads auf die CPU warten oder ob sogar jeder Thread auf der Box angehalten ist und auf Ressourcen wie Speicher oder I/O wartet. Zum Beispiel konnten wir sehen, auf wie viel Prozent jeder Thread auf der Instance I/O über einen Zeitraum von 1 Minute angehalten wurde.
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
Anhand dieser Metrik können wir in der obigen Tabelle sehen, dass jeder Thread auf der Box in 45% der Fälle zum Stillstand kam, wenn er I/O an der Hochwassermarke wartete, was bedeutet, dass wir all diese CPU-Zyklen in dieser Minute weggeworfen haben. Wenn wir verstehen, dass dies geschieht, können wir einen erheblichen Teil der vCPU-Zeit zurückgewinnen und so die Skalierung effizienter gestalten.
HPA V2
Es wird empfohlen, die autoscaling/v2 Version der HPA-API zu verwenden. Bei den älteren Versionen der HPA-API konnte es in bestimmten Randfällen zu Verzögerungen bei der Skalierung kommen. Es war auch auf Pods beschränkt, die sich bei jedem Skalierungsschritt nur verdoppelten, was bei kleinen Bereitstellungen, die schnell skaliert werden mussten, zu Problemen führte.
Autoscaling/v2 ermöglicht uns mehr Flexibilität bei der Berücksichtigung mehrerer Kriterien für die Skalierung und ermöglicht uns ein hohes Maß an Flexibilität bei der Verwendung benutzerdefinierter und externer Metriken (keine K8s-Metriken).
Als Beispiel können wir auf den höchsten von drei Werten skalieren (siehe unten). Wir skalieren, wenn die durchschnittliche Auslastung aller Pods über 50% liegt, wenn benutzerdefinierte Metriken die Pakete pro Sekunde des Eingangs den Durchschnitt von 1.000 überschreiten oder das Eingangsobjekt 10.000 Anfragen pro Sekunde überschreitet.
Anmerkung
Dies dient nur dazu, die Flexibilität der Auto-Scaling-API zu demonstrieren. Wir empfehlen, nicht zu komplexe Regeln zu verwenden, die in der Produktion schwierig zu beheben sein können.
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
Wir haben jedoch die Gefahr erkannt, die mit der Verwendung solcher Metriken für komplexe Webanwendungen verbunden ist. In diesem Fall wären wir besser bedient, wenn wir benutzerdefinierte oder externe Metriken verwenden würden, die die Auslastung unserer Anwendung im Vergleich zur Auslastung genau wiedergeben. HPAv2 ermöglicht dies, indem es die Möglichkeit hat, nach jeder beliebigen Metrik zu skalieren. Wir müssen diese Metrik jedoch immer noch finden und zur Verwendung nach Kubernetes exportieren.
Wir können uns zum Beispiel die Anzahl der aktiven Thread-Warteschlangen in Apache ansehen. Dadurch entsteht oft ein „glatteres“ Skalierungsprofil (mehr zu diesem Begriff in Kürze). Wenn ein Thread aktiv ist, spielt es keine Rolle, ob dieser Thread auf einer Datenbankebene wartet oder eine Anfrage lokal bearbeitet. Wenn alle Anwendungs-Threads verwendet werden, ist das ein gutes Zeichen dafür, dass die Anwendung überlastet ist.
Wir können diese Thread-Erschöpfung als Signal verwenden, um einen neuen Pod mit einem vollständig verfügbaren Thread-Pool zu erstellen. Dies gibt uns auch die Kontrolle darüber, wie groß der Puffer sein soll, den die Anwendung in Zeiten mit hohem Datenverkehr aufnehmen soll. Wenn wir beispielsweise einen Thread-Pool von insgesamt 10 hätten, hätte die Skalierung bei 4 verwendeten Threads gegenüber 8 verwendeten Threads große Auswirkungen auf den Puffer, den wir bei der Skalierung der Anwendung zur Verfügung haben. Eine Einstellung von 4 wäre für eine Anwendung sinnvoll, die unter hoher Last schnell skaliert werden muss, wobei eine Einstellung von 8 unsere Ressourcen effizienter einsetzen würde, wenn wir genügend Zeit für die Skalierung hätten, da die Anzahl der Anfragen im Laufe der Zeit langsam und nicht stark zunimmt.
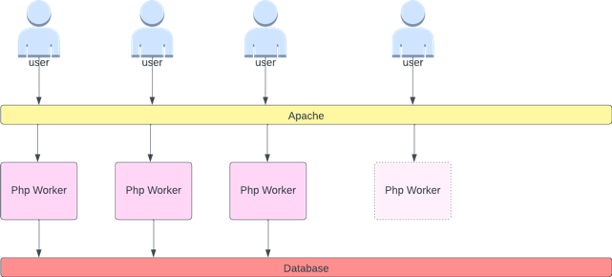
Was meinen wir mit dem Begriff „glatt“, wenn es um Skalierung geht? Beachten Sie die folgende Tabelle, in der wir die CPU als Metrik verwenden. Die Pods in dieser Bereitstellung steigen innerhalb kurzer Zeit sprunghaft an und reichen von 50 Pods bis hin zu 250 Pods, um dann sofort wieder herunterskaliert zu werden. Diese äußerst ineffiziente Skalierung ist die Hauptursache für die Abwanderung von Clustern.
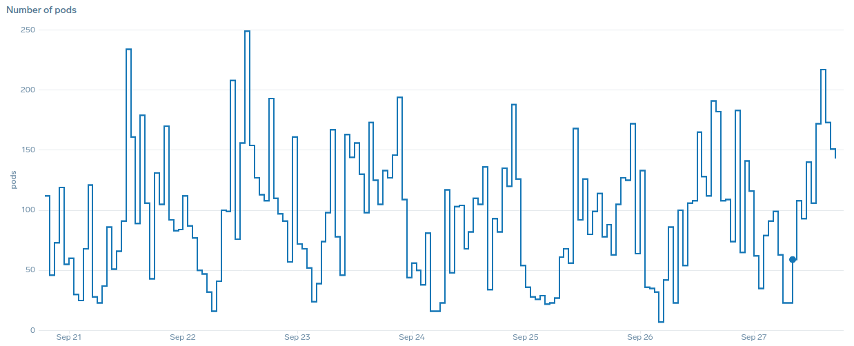
Beachten Sie, dass wir nach der Umstellung auf eine Metrik, die den korrekten Sweetspot unserer Anwendung (mittlerer Teil des Diagramms) widerspiegelt, problemlos skalieren können. Unsere Skalierung ist jetzt effizient, und unsere Pods können mit dem Spielraum, den wir durch die Anpassung der Anforderungseinstellungen geschaffen haben, vollständig skalieren. Jetzt erledigt eine kleinere Gruppe von Pods die Arbeit, die Hunderte von Pods zuvor erledigt haben. Daten aus der Praxis zeigen, dass dies der wichtigste Faktor für die Skalierbarkeit von Kubernetes-Clustern ist.
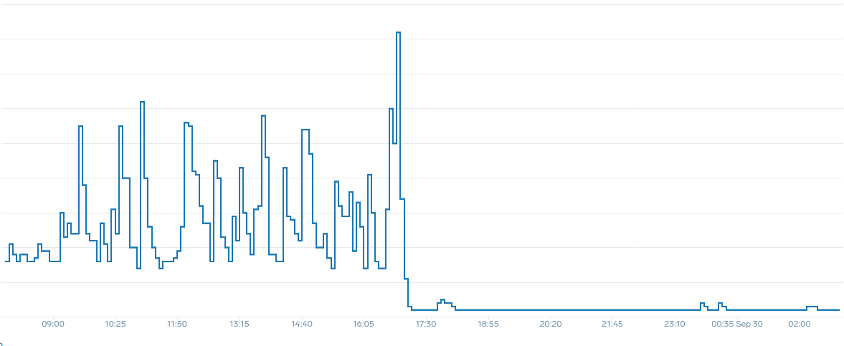
Die wichtigste Erkenntnis ist, dass die CPU-Auslastung nur eine Dimension der Anwendungs- und Knotenleistung ist. Die Verwendung der CPU-Auslastung als alleinigen Gesundheitsindikator für unsere Knoten und Anwendungen führt zu Problemen bei Skalierung, Leistung und Kosten, die allesamt eng miteinander verknüpft sind. Je leistungsfähiger die Anwendung und die Knoten sind, desto weniger müssen Sie skalieren, was wiederum Ihre Kosten senkt.
Wenn Sie die richtigen Sättigungsmetriken für die Skalierung Ihrer speziellen Anwendung finden und verwenden, können Sie auch die tatsächlichen Engpässe für diese Anwendung überwachen und entsprechende Warnmeldungen auslösen. Wenn dieser wichtige Schritt übersprungen wird, sind Berichte über Leistungsprobleme nur schwer, wenn nicht gar unmöglich nachzuvollziehen.
CPU-Grenzwerte festlegen
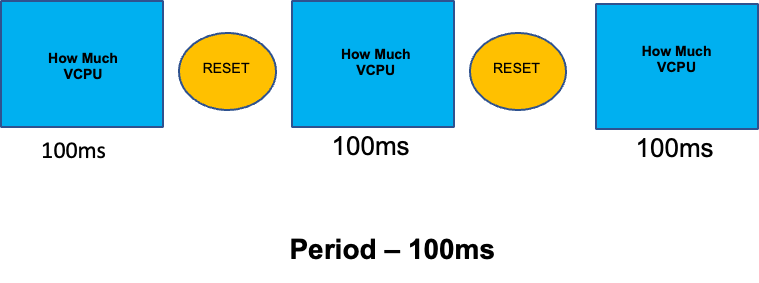
Um diesen Abschnitt über missverstandene Themen abzurunden, werden wir uns mit CPU-Limits befassen. Kurz gesagt, Grenzwerte sind Metadaten, die mit dem Container verknüpft sind, der über einen Zähler verfügt, der alle 100 ms zurückgesetzt wird. Auf diese Weise kann Linux nachverfolgen, wie viele CPU-Ressourcen knotenweit von einem bestimmten Container in einem Zeitraum von 100 ms genutzt werden.
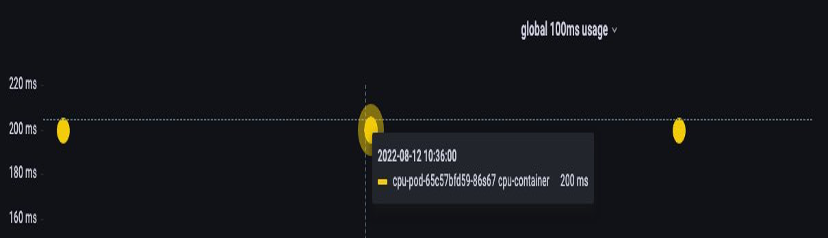
Ein häufiger Fehler beim Setzen von Grenzwerten ist die Annahme, dass die Anwendung Single-Thread-fähig ist und nur auf der ihr „`zugewiesenen“ vCPU läuft. Im obigen Abschnitt haben wir gelernt, dass CFS keine Kerne zuweist, und dass ein Container, der große Thread-Pools ausführt, in Wirklichkeit alle verfügbaren vCPUs auf der Box plant.
Wenn 64 Betriebssystem-Threads auf 64 verfügbaren Kernen laufen (aus Sicht eines Linux-Knotens), machen wir die Gesamtsumme der verbrauchten CPU-Zeit in einem Zeitraum von 100 ms ziemlich hoch, nachdem die auf all diesen 64 Kernen laufende Zeit zusammengezählt wurde. Da dies möglicherweise nur während eines Garbage-Collection-Prozesses passiert, kann es ziemlich leicht sein, so etwas zu übersehen. Aus diesem Grund ist es notwendig, Metriken zu verwenden, um sicherzustellen, dass wir im Laufe der Zeit die richtige Nutzung haben, bevor wir versuchen, ein Limit festzulegen.
Zum Glück können wir genau sehen, wie viel vCPU von allen Threads in einer Anwendung verwendet wird. Wir werden die Metrik container_cpu_usage_seconds_total für diesen Zweck verwenden.
Da die Drosselungslogik alle 100 ms erfolgt und es sich bei dieser Metrik um eine Metrik pro Sekunde handelt, werden wir PromQL entsprechend diesem Zeitraum von 100 ms anpassen. Wenn Sie sich eingehend mit dieser PromQL-Aussage befassen möchten, lesen Sie bitte den folgenden Blog.
PromQL-Abfrage:
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

Sobald wir das Gefühl haben, dass wir den richtigen Wert haben, können wir das Limit für die Produktion festlegen. Dann muss geprüft werden, ob unsere Anwendung aufgrund eines Unerwarteten gedrosselt wird. Wir können das tun, indem wir uns Folgendes ansehen container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10
Arbeitsspeicher
Die Speicherzuweisung ist ein weiteres Beispiel, bei dem es leicht ist, das Kubernetes-Scheduling-Verhalten mit dem CGroup-Verhalten von Linux zu verwechseln. Dies ist ein differenzierteres Thema, da die Art und Weise, wie CGroup v2 unter Linux mit Speicher umgeht, große Änderungen vorgenommen hat und Kubernetes seine Syntax geändert hat, um dies widerzuspiegeln. Weitere Informationen finden Sie in diesem Blog.
Im Gegensatz zu CPU-Anfragen bleiben Speicheranforderungen ungenutzt, nachdem der Scheduling-Prozess abgeschlossen ist. Das liegt daran, dass wir Speicher in CGroup v1 nicht auf die gleiche Weise komprimieren können wie mit der CPU. Damit bleiben uns nur noch Speicherlimits übrig, die als Ausfallschutz gegen Speicherlecks dienen sollen, indem sie den Pod vollständig beenden. Dabei handelt es sich um ein Alles-oder-nichts-Konzept, aber uns wurden jetzt neue Möglichkeiten aufgezeigt, dieses Problem zu lösen.
Zunächst ist es wichtig zu verstehen, dass das Einstellen der richtigen Speichermenge für Container nicht so einfach ist, wie es scheint. Das Dateisystem unter Linux verwendet Speicher als Cache, um die Leistung zu verbessern. Dieser Cache wird mit der Zeit größer, und es kann schwierig sein, zu wissen, wie viel Speicher für den Cache einfach nützlich ist, aber ohne nennenswerte Auswirkungen auf die Anwendungsleistung zurückgewonnen werden kann. Dies führt häufig zu einer Fehlinterpretation der Speichernutzung.
Die Fähigkeit, Speicher zu „komprimieren“, war einer der Hauptgründe für CGroup v2. Weitere Informationen darüber, warum CGroup V2 notwendig war, finden Sie in Chris Downs Präsentation
Zum Glück hat Kubernetes jetzt das Konzept von und unter. memory.min memory.high requests.memory Dies gibt uns die Möglichkeit, diesen zwischengespeicherten Speicher aggressiv für andere Container freizugeben. Sobald der Container die Speicherobergrenze erreicht hat, kann der Kernel den Speicher dieses Containers bis zu dem auf festgelegten Wert aggressiv zurückfordern. memory.min Das gibt uns mehr Flexibilität, wenn ein Knoten unter Speicherdruck gerät.
Die zentrale Frage lautet: Auf welchen Wert memory.min soll gesetzt werden? Hier kommen die Kennzahlen zum Stillstand des Speicherdrucks ins Spiel. Wir können diese Metriken verwenden, um zu erkennen, dass Speicher auf Containerebene überlastet wird. Dann können wir Controller wie fbtaxmemory.min indem wir nach diesem Speicherüberhang suchen, und den memory.min Wert dynamisch auf diese Einstellung setzen.
Zusammenfassung
Um den Abschnitt zusammenzufassen, lassen sich die folgenden Konzepte leicht miteinander verbinden:
-
Auslastung und Sättigung
-
Linux-Leistungsregeln mit Kubernetes Scheduler-Logik
Es muss sehr sorgfältig darauf geachtet werden, diese Konzepte voneinander zu trennen. Leistung und Skalierbarkeit sind tief miteinander verknüpft. Unnötige Skalierung führt zu Leistungsproblemen, was wiederum zu Skalierungsproblemen führt.
