Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erweiterte Skalierung für Amazon EMR
Ab Amazon EMR auf EC2 Version 7.0 können Sie Advanced Scaling nutzen, um die Ressourcennutzung Ihres Clusters zu kontrollieren. Advanced Scaling führt eine Nutzungs- und Leistungsskala ein, mit der Sie Ihre Ressourcennutzung und Ihr Leistungsniveau an Ihre Geschäftsanforderungen anpassen können. Der von Ihnen festgelegte Wert bestimmt, ob Ihr Cluster stärker auf Ressourcenschonung oder auf Skalierung zur Bewältigung service-level-agreement (SLA) sensibler Workloads ausgerichtet ist, bei denen eine schnelle Fertigstellung entscheidend ist. Wenn der Skalierungswert angepasst wird, interpretiert die verwaltete Skalierung Ihre Absicht und skaliert intelligent, um die Ressourcen zu optimieren. Weitere Informationen zur verwalteten Skalierung finden Sie unter Managed Scaling für Amazon EMR konfigurieren.
Erweiterte Skalierungseinstellungen
Der Wert, den Sie für Advanced Scaling festgelegt haben, optimiert Ihren Cluster an Ihre Anforderungen. Die Werte liegen im Bereich von 1 bis 100. Mögliche Werte sind 1, 25, 50, 75 und 100. Wenn Sie den Index auf andere Werte als diese festlegen, führt dies zu einem Validierungsfehler.
Skalierungswerte entsprechen Strategien zur Ressourcennutzung. In der folgenden Liste werden mehrere davon definiert:
Optimierte Nutzung [1] — Diese Einstellung verhindert eine übermäßige Bereitstellung von Ressourcen. Verwenden Sie einen niedrigen Wert, wenn Sie die Kosten niedrig halten und einer effizienten Ressourcennutzung Priorität einräumen möchten. Dies führt dazu, dass der Cluster weniger aggressiv skaliert wird. Dies eignet sich gut für den Anwendungsfall, in dem regelmäßig Arbeitslastspitzen auftreten und Sie nicht möchten, dass die Ressourcen zu schnell ansteigen.
Ausgewogen [50] — Dadurch wird ein ausgewogenes Verhältnis zwischen Ressourcennutzung und Arbeitsleistung erreicht. Diese Einstellung eignet sich für konstante Workloads, bei denen die meisten Phasen über eine stabile Laufzeit verfügen. Sie eignet sich auch für Workloads mit einer Mischung aus Phasen mit kurzer und langer Laufzeit. Wir empfehlen, mit dieser Einstellung zu beginnen, wenn Sie sich nicht sicher sind, welche Sie wählen sollen.
Leistungsoptimiert [100] — Bei dieser Strategie wird Leistung priorisiert. Der Cluster wird aggressiv skaliert, um sicherzustellen, dass Jobs schnell abgeschlossen werden und die Leistungsziele erreicht werden. Performance Optimized eignet sich für service-level-agreement (SLA-) sensible Workloads, bei denen eine schnelle Laufzeit entscheidend ist.
Anmerkung
Die verfügbaren Zwischenwerte bieten einen Mittelweg zwischen den Strategien zur Feinabstimmung des Advanced Scaling-Verhaltens Ihres Clusters.
Vorteile der erweiterten Skalierung
Da Ihre Umgebung und Ihre Anforderungen unterschiedlich sind, z. B. sich ändernde Datenmengen, Anpassungen der Kostenziele und SLA-Implementierungen, kann die Clusterskalierung Ihnen helfen, Ihre Clusterkonfiguration so anzupassen, dass Sie Ihre Ziele erreichen. Zu den wichtigsten Vorteilen gehören:
Verbesserte detaillierte Steuerung — Mit der Einführung der Einstellung für die Auslastung und Leistung können Sie das Skalierungsverhalten Ihres Clusters ganz einfach an Ihre Anforderungen anpassen. Sie können je nach Ihren Nutzungsmustern nach oben skalieren, um den Bedarf an Rechenressourcen zu decken, oder nach unten skalieren, um Ressourcen zu sparen.
Verbesserte Kostenoptimierung — Sie können je nach Bedarf einen niedrigen Nutzungswert wählen, um Ihre Kostenziele leichter zu erreichen.
Erste Schritte mit der Optimierung
Einrichtung und Konfiguration
Gehen Sie wie folgt vor, um den Leistungsindex festzulegen und Ihre Skalierungsstrategie zu optimieren.
Mit dem folgenden Befehl wird ein vorhandener Cluster mit der nutzungsoptimierten
[1]Skalierungsstrategie aktualisiert:aws emr put-managed-scaling-policy --cluster-id 'cluster-id' \ --managed-scaling-policy '{ "ComputeLimits": { "UnitType": "Instances", "MinimumCapacityUnits": 1, "MaximumCapacityUnits": 2, "MaximumOnDemandCapacityUnits": 2, "MaximumCoreCapacityUnits": 2 }, "ScalingStrategy": "ADVANCED", "UtilizationPerformanceIndex": "1" }' \ --region "region-name"Die Attribute
ScalingStrategyundUtilizationPerformanceIndexsind neu und für die Skalierungsoptimierung relevant. Sie können verschiedene Skalierungsstrategien auswählen, indem Sie die entsprechenden Werte (1, 25, 50, 75 und 100) für dasUtilizationPerformanceIndexAttribut in der Richtlinie für verwaltete Skalierung festlegen.Um zur Standardstrategie für verwaltete Skalierung zurückzukehren, führen Sie den
put-managed-scaling-policyBefehl aus, ohne die Attribute und einzubeziehen.ScalingStrategyUtilizationPerformanceIndex(Dies ist optional.) Dieses Beispiel zeigt, wie das geht:aws emr put-managed-scaling-policy \ --cluster-id 'cluster-id' \ --managed-scaling-policy '{"ComputeLimits":{"UnitType":"Instances","MinimumCapacityUnits":1,"MaximumCapacityUnits":2,"MaximumOnDemandCapacityUnits":2,"MaximumCoreCapacityUnits":2}}' \ --region "region-name"
Verwendung von Überwachungsmetriken zur Nachverfolgung der Cluster-Auslastung
Ab EMR-Version 7.3.0 veröffentlicht Amazon EMR vier neue Metriken zu Arbeitsspeicher und virtueller CPU. Sie können diese verwenden, um die Cluster-Auslastung über verschiedene Skalierungsstrategien hinweg zu messen. Diese Metriken sind für jeden Anwendungsfall verfügbar, aber Sie können die hier bereitgestellten Details zur Überwachung von Advanced Scaling verwenden.
Zu den verfügbaren hilfreichen Metriken gehören die folgenden:
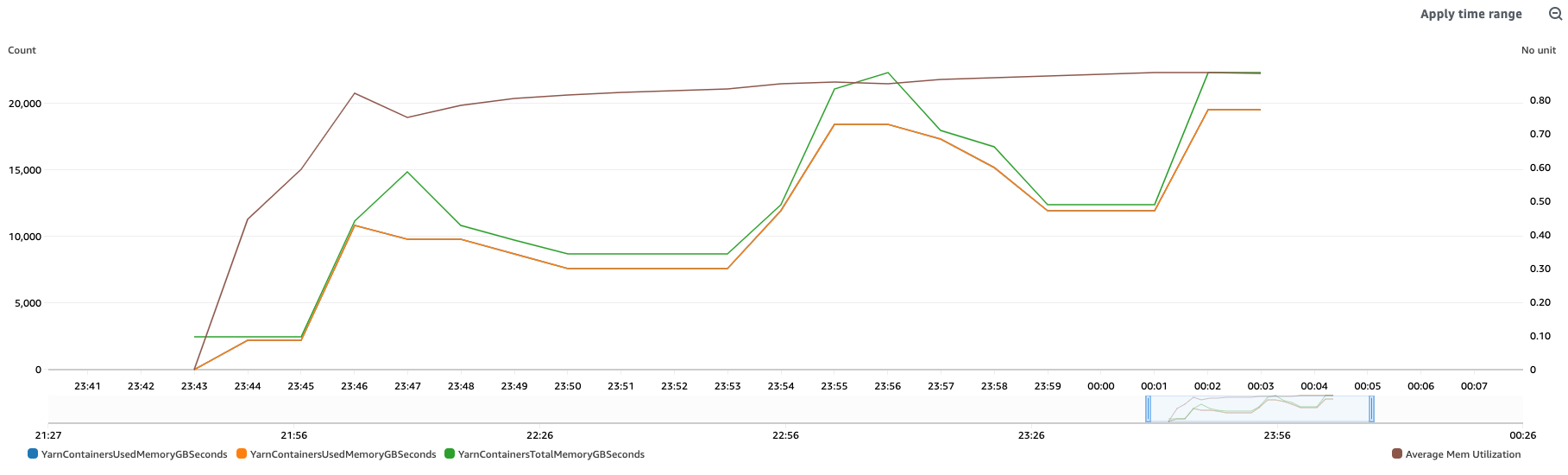
YarnContainersUsedMemoryGBSeconds— Speichermenge, die von Anwendungen verbraucht wird, die von YARN verwaltet werden.
YarnContainersTotalMemoryGBSeconds— Gesamtspeicherkapazität, die YARN innerhalb des Clusters zugewiesen wurde.
YarnNodesUsedVCPUSeconds— VCPU-Sekunden insgesamt für jede von YARN verwaltete Anwendung.
YarnNodesTotalVCPUSeconds— Aggregierte Gesamt-VCPU-Sekunden für den verbrauchten Speicher, einschließlich des Zeitfensters, in dem Yarn nicht bereit ist.
Sie können Ressourcenmetriken mit Amazon CloudWatch Logs Insights analysieren. Zu den Funktionen gehört eine speziell entwickelte Abfragesprache, mit der Sie Kennzahlen extrahieren können, die für die Ressourcennutzung und Skalierung spezifisch sind.
Die folgende Abfrage, die Sie in der Amazon CloudWatch Konsole ausführen können, verwendet metrische Mathematik, um die durchschnittliche Speicherauslastung (e1) zu berechnen, indem die laufende Summe des verbrauchten Speichers (e2) durch die laufende Summe des Gesamtspeichers (e3) dividiert wird:
{ "metrics": [ [ { "expression": "e2/e3", "label": "Average Mem Utilization", "id": "e1", "yAxis": "right" } ], [ { "expression": "RUNNING_SUM(m1)", "label": "RunningTotal-YarnContainersUsedMemoryGBSeconds", "id": "e2", "visible": false } ], [ { "expression": "RUNNING_SUM(m2)", "label": "RunningTotal-YarnContainersTotalMemoryGBSeconds", "id": "e3", "visible": false } ], [ "AWS_EMR_ManagedResize", "YarnContainersUsedMemoryGBSeconds", "ACCOUNT_ID", "793684541905", "COMPONENT", "ManagerService", "JOB_FLOW_ID", "cluster-id", { "id": "m1", "label": "YarnContainersUsedMemoryGBSeconds" } ], [ ".", "YarnContainersTotalMemoryGBSeconds", ".", ".", ".", ".", ".", ".", { "id": "m2", "label": "YarnContainersTotalMemoryGBSeconds" } ] ], "view": "timeSeries", "stacked": false, "region": "region", "period": 60, "stat": "Sum", "title": "Memory Utilization" }
Um Protokolle abzufragen, können Sie CloudWatch in der AWS Konsole auswählen. Weitere Informationen zum Schreiben von Abfragen für CloudWatch finden Sie unter Analysieren von Protokolldaten mit CloudWatch Logs Insights im Amazon CloudWatch Logs-Benutzerhandbuch.
Die folgende Abbildung zeigt diese Metriken für einen Beispielcluster:
Überlegungen und Einschränkungen
Die Effektivität von Skalierungsstrategien kann je nach Ihren individuellen Workload-Merkmalen und der Cluster-Konfiguration variieren. Wir empfehlen Ihnen, mit der Skalierungseinstellung zu experimentieren, um einen optimalen Indexwert für Ihren Anwendungsfall zu ermitteln.
Amazon EMR Advanced Scaling eignet sich besonders gut für Batch-Workloads. Für SQL/Data-Warehousing- und Streaming-Workloads empfehlen wir die Verwendung der Standardstrategie für verwaltete Skalierung, um eine optimale Leistung zu erzielen.
Die leistungsoptimierte Skalierungsstrategie ermöglicht eine schnellere Auftragsausführung, indem hohe Rechenressourcen über einen längeren Zeitraum aufrechterhalten werden als die standardmäßige Strategie für verwaltete Skalierung. Dieser Modus priorisiert die schnelle Skalierung, um den Ressourcenanforderungen gerecht zu werden, was zu einer schnelleren Auftragsabwicklung führt. Dies kann im Vergleich zur Standardstrategie zu höheren Kosten führen.
In Fällen, in denen der Cluster bereits optimiert und voll ausgelastet ist, bietet die Aktivierung von Advanced Scaling möglicherweise keine zusätzlichen Vorteile. In einigen Situationen kann die Aktivierung von Advanced Scaling zu erhöhten Kosten führen, da die Workloads länger laufen können. In diesen Fällen empfehlen wir, die Standardstrategie für verwaltete Skalierung zu verwenden, um eine optimale Ressourcenzuweisung und Kosteneffizienz zu gewährleisten.
Im Zusammenhang mit verwalteter Skalierung verlagert sich der Schwerpunkt auf die Ressourcennutzung im Laufe der Ausführungszeit, da die Einstellung von leistungsoptimiert [100] auf auslastungsoptimiert [1] geändert wird. Es ist jedoch wichtig zu beachten, dass die Ergebnisse je nach Art der Arbeitslast und der Topologie des Clusters variieren können. Um optimale Ergebnisse für Ihren Anwendungsfall sicherzustellen, empfehlen wir dringend, die Skalierungsstrategien mit Ihren Workloads zu testen, um die am besten geeignete Einstellung zu ermitteln.
Der PerformanceUtilizationIndexakzeptiert nur die folgenden Werte:
1
25
50
75
100
Alle anderen übermittelten Werte führen zu einem Validierungsfehler.
