Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Funktionsweise von Iceberg
Iceberg verfolgt einzelne Datendateien in einer Tabelle statt in Verzeichnissen. Auf diese Weise können Autoren Datendateien an Ort und Stelle erstellen (Dateien werden nicht verschoben oder geändert). Außerdem können Autoren der Tabelle nur in einem expliziten Commit Dateien hinzufügen. Der Tabellenstatus wird in Metadatendateien beibehalten. Bei allen Änderungen am Tabellenstatus wird eine neue Metadatendatei erstellt, die die älteren Metadaten atomar ersetzt. Die Tabellenmetadatendatei verfolgt das Tabellenschema, die Partitionierungskonfiguration und andere Eigenschaften.
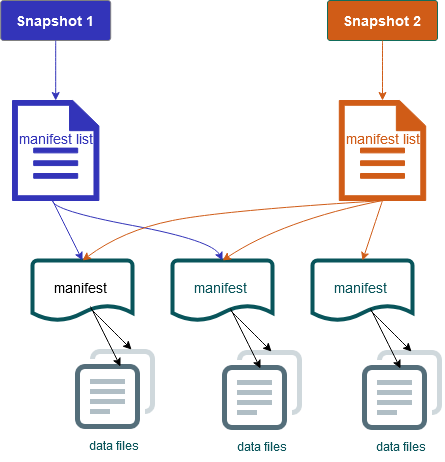
Sie enthält auch Snapshots des Tabelleninhalts. Jeder Snapshot ist ein vollständiger Satz von Datendateien in der Tabelle zu einem bestimmten Zeitpunkt. Snapshots sind in der Metadatendatei aufgeführt, aber die Dateien in einem Snapshot werden in separaten Manifestdateien gespeichert. Die atomaren Übergänge von einer Tabellenmetadatendatei zur nächsten ermöglichen die Isolierung von Snapshots. Leser verwenden den Snapshot, der aktuell war, als sie die Tabellenmetadaten geladen haben. Leser sind von Änderungen erst betroffen, wenn sie den Vorgang aktualisieren und einen neuen Speicherort für Metadaten auswählen. Datendateien in Snapshots werden in einer oder mehreren Manifestdateien gespeichert, die eine Zeile für jede Datendatei in der Tabelle, ihre Partitionsdaten und ihre Metriken enthalten. Ein Snapshot ist die Vereinigung aller Dateien in ihren Manifesten. Manifestdateien können auch von Snapshots gemeinsam genutzt werden, um zu vermeiden, dass Metadaten, die sich selten ändern, neu geschrieben werden.
Iceberg-Snapshot-Diagramm
Iceberg bietet folgende Features:
-
Unterstützt ACID-Transaktionen und Zeitreisen in Ihrem Amazon-S3-Data-Lake.
-
Commit-Wiederholungen profitieren von den Leistungsvorteilen optimistischer Parallelität
. -
Die Konfliktlösung auf Dateiebene führt zu einer hohen Parallelität.
-
Mit Min-Max-Statistiken pro Spalte in Metadaten können Sie Dateien überspringen, was die Leistung bei selektiven Abfragen steigert.
-
Sie können Tabellen in flexiblen Partitionslayouts organisieren, wobei die Partitionsentwicklung Aktualisierungen von Partitionsschemas ermöglicht. Abfragen und Datenvolumen können sich dann ändern, ohne auf physische Verzeichnisse angewiesen zu sein.
-
Unterstützt die Weiterentwicklung und Durchsetzung von Schemas
. -
Iceberg-Tabellen dienen als idempotente Senken und wiederspielbare Quellen. Dies ermöglicht Streaming und Batch-Support mit exakt einmal verwendeten Pipelines. Idempotente Senken verfolgen Schreiboperationen, die in der Vergangenheit erfolgreich waren. Daher kann die Senke im Falle eines Fehlers erneut Daten anfordern und Daten löschen, wenn sie mehrfach gesendet wurden.
-
Zeigen Sie Verlauf und Herkunft an, einschließlich Tabellenentwicklung, Operationsverlauf und Statistiken für jeden Commit.
-
Migrieren Sie von einem vorhandenen Datensatz mit einer Auswahl an Datenformaten (Parquet, ORC, Avro) und Analyse-Engine (Spark, Trino, PrestoDB, Flink, Hive).
