Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Arbeiten mit Flink-Aufträgen von Zeppelin in Amazon EMR
Einführung
Amazon-EMR-Versionen 6.10.0 und höher unterstützen die Apache Zeppelin-Integration mit Apache Flink. Sie können Flink-Aufträge interaktiv über Zeppelin-Notebooks einreichen. Mit dem Flink-Interpreter können Sie Flink-Abfragen ausführen, Flink-Streaming- und Batch-Aufträge definieren und die Ausgabe in Zeppelin-Notebooks visualisieren. Der Flink-Interpreter basiert auf der Flink-REST-API. Auf diese Weise können Sie von der Zeppelin-Umgebung aus auf Flink-Aufträge zugreifen und diese bearbeiten, um eine Datenverarbeitung und -analyse in Echtzeit durchzuführen.
In Flink Interpreter gibt es vier Unterinterpreter. Sie dienen unterschiedlichen Zwecken, befinden sich aber alle in der JVM und teilen sich dieselben vorkonfigurierten Einstiegspunkte zu Flink (ExecutionEnviroment, StreamExecutionEnvironment, BatchTableEnvironment, StreamTableEnvironment). Die Interpreter sind wie folgt:
-
%flink– ErzeugtExecutionEnvironment,StreamExecutionEnvironment,BatchTableEnvironment,StreamTableEnvironmentund stellt eine Scala-Umgebung bereit -
%flink.pyflink– Stellt eine Python-Umgebung bereit -
%flink.ssql– Stellt eine Streaming-SQL-Umgebung bereit -
%flink.bsql– Stellt eine Batch-SQL-Umgebung bereit
Voraussetzungen
-
Die Zeppelin-Integration mit Flink wird für Cluster unterstützt, die mit Amazon EMR 6.10.0 und höher erstellt wurden.
-
Um Webschnittstellen, die auf EMR-Clustern gehostet werden, wie für diese Schritte erforderlich, anzuzeigen, müssen Sie einen SSH-Tunnel konfigurieren, der eingehenden Zugriff ermöglicht. Weitere Informationen finden Sie unter Konfigurieren von Proxy-Einstellungen, um auf dem Primärknoten gehostete Websites anzeigen zu lassen.
Zeppelin-Flink auf einem EMR-Cluster konfigurieren
Gehen Sie wie folgt vor, um Apache Flink auf Apache Zeppelin für die Ausführung auf einem EMR-Cluster zu konfigurieren:
-
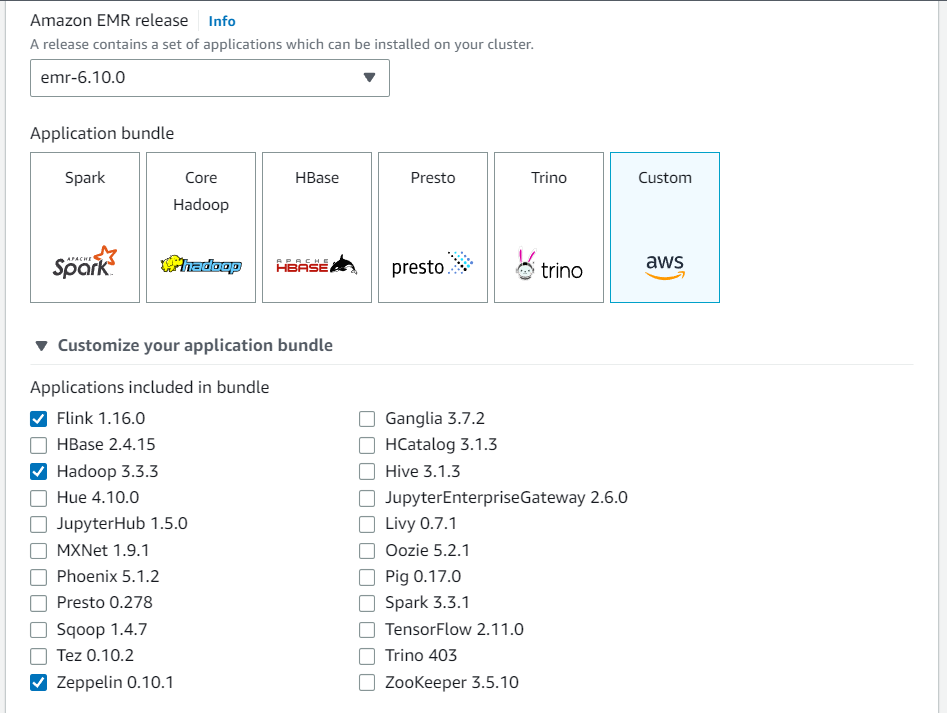
Erstellen Sie einen neuen Cluster von der Amazon-EMR-Konsole aus. Wählen Sie emr-6.10.0 oder höher für die Amazon-EMR-Version aus. Wählen Sie dann, ob Sie Ihr Anwendungspaket mit der Option Benutzerdefiniert anpassen möchten. Nehmen Sie mindestens Flink, Hadoop und Zeppelin in Ihr Paket auf.
-
Erstellen Sie den Rest Ihres Clusters mit den Einstellungen, die Sie bevorzugen.
-
Sobald Ihr Cluster läuft, wählen Sie den Cluster in der Konsole aus, um seine Details anzuzeigen, und öffnen Sie die Registerkarte Anwendungen. Wählen Sie Zeppelin im Bereich Benutzeroberflächen für Anwendungen aus, um die Zeppelin-Weboberfläche zu öffnen. Stellen Sie sicher, dass Sie den Zugriff auf die Zeppelin-Weboberfläche mit einem SSH-Tunnel zum Primärknoten und einer Proxyverbindung eingerichtet haben, wie in Voraussetzungen beschrieben.
-
Jetzt können Sie eine neue Notiz in einem Zeppelin-Notebook mit Flink als Standardinterpreter erstellen.

-
In den folgenden Codebeispielen wird veranschaulicht, wie Flink-Jobs von einem Zeppelin-Notebook aus ausgeführt werden.
Führen Sie Flink-Aufträge mit Zeppelin-Flink auf einem EMR-Cluster aus
-
Beispiel 1, Flink Scala
a) WordCount Batch-Beispiel (SCALA)
%flink val data = benv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .groupBy(0) .sum(1) .print()b) WordCount Streaming-Beispiel (SCALA)
%flink val data = senv.fromElements("hello world", "hello flink", "hello hadoop") data.flatMap(line => line.split("\\s")) .map(w => (w, 1)) .keyBy(0) .sum(1) .print senv.execute()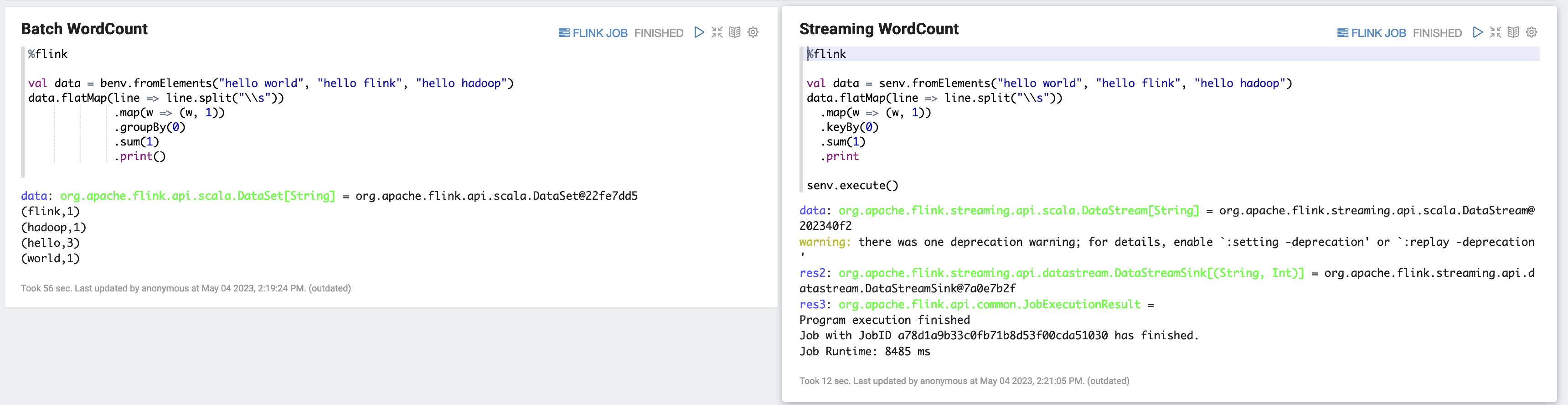
-
Beispiel 2, Flink Streaming SQL
%flink.ssql SET 'sql-client.execution.result-mode' = 'tableau'; SET 'table.dml-sync' = 'true'; SET 'execution.runtime-mode' = 'streaming'; create table dummy_table ( id int, data string ) with ( 'connector' = 'filesystem', 'path' = 's3://s3-bucket/dummy_table', 'format' = 'csv' ); INSERT INTO dummy_table SELECT * FROM (VALUES (1, 'Hello World'), (2, 'Hi'), (2, 'Hi'), (3, 'Hello'), (3, 'World'), (4, 'ADD'), (5, 'LINE')); SELECT * FROM dummy_table;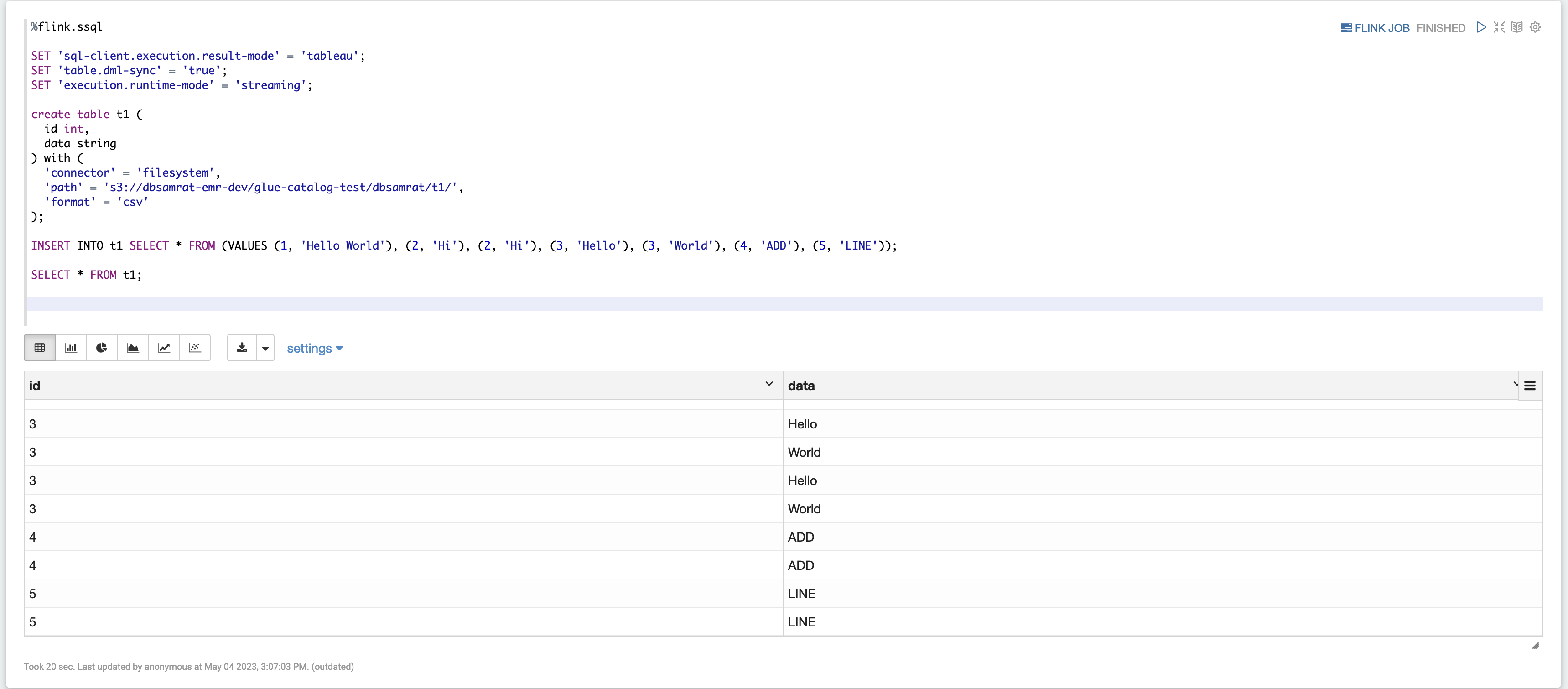
-
Beispiel 3, Pyflink. Beachten Sie, dass Sie Ihre eigene Beispieltextdatei mit dem Namen
word.txtin Ihren S3-Bucket hochladen müssen.%flink.pyflink import argparse import logging import sys from pyflink.common import Row from pyflink.table import (EnvironmentSettings, TableEnvironment, TableDescriptor, Schema, DataTypes, FormatDescriptor) from pyflink.table.expressions import lit, col from pyflink.table.udf import udtf def word_count(input_path, output_path): t_env = TableEnvironment.create(EnvironmentSettings.in_streaming_mode()) # write all the data to one file t_env.get_config().set("parallelism.default", "1") # define the source if input_path is not None: t_env.create_temporary_table( 'source', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .build()) .option('path', input_path) .format('csv') .build()) tab = t_env.from_path('source') else: print("Executing word_count example with default input data set.") print("Use --input to specify file input.") tab = t_env.from_elements(map(lambda i: (i,), word_count_data), DataTypes.ROW([DataTypes.FIELD('line', DataTypes.STRING())])) # define the sink if output_path is not None: t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('filesystem') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .option('path', output_path) .format(FormatDescriptor.for_format('canal-json') .build()) .build()) else: print("Printing result to stdout. Use --output to specify output path.") t_env.create_temporary_table( 'sink', TableDescriptor.for_connector('print') .schema(Schema.new_builder() .column('word', DataTypes.STRING()) .column('count', DataTypes.BIGINT()) .build()) .build()) @udtf(result_types=[DataTypes.STRING()]) def split(line: Row): for s in line[0].split(): yield Row(s) # compute word count tab.flat_map(split).alias('word') \ .group_by(col('word')) \ .select(col('word'), lit(1).count) \ .execute_insert('sink') \ .wait() logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s") word_count("s3://s3_bucket/word.txt", "s3://s3_bucket/demo_output.txt")
-
Wählen Sie FLINK JOB in der Zeppelin-Benutzeroberfläche, um auf die Flink-Web-UI zuzugreifen und diese anzusehen.

-
Wenn Sie FLINK JOB wählen, gelangen Sie zur Flink Web Console in einer anderen Registerkarte Ihres Browsers.