Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erstellen eines regelbasierten Abgleichsworkflows mit dem Regeltyp „Erweitert“
Das folgende Verfahren zeigt, wie Sie mithilfe der Konsole oder der API einen regelbasierten Abgleichsworkflow mit dem Regeltyp Advanced erstellen. AWS Entity Resolution CreateMatchingWorkflow
- Console
-
So erstellen Sie mithilfe der Konsole einen regelbasierten Abgleichsworkflow mit dem Regeltyp Advanced
-
Melden Sie sich bei der an AWS Management Console und öffnen Sie die AWS Entity Resolution Konsole unter. https://console.aws.amazon.com/entityresolution/
-
Wählen Sie im linken Navigationsbereich unter Workflows die Option Matching aus.
-
Wählen Sie auf der Seite Abgleichende Workflows in der oberen rechten Ecke die Option Passenden Workflow erstellen aus.
-
Gehen Sie für Schritt 1: Passende Workflow-Details angeben wie folgt vor:
-
Geben Sie einen passenden Workflow-Namen und optional eine Beschreibung ein.
-
Wählen Sie für Dateneingabe eine AWS Glue Datenbank aus der Dropdownliste, wählen Sie die AWS Glue Tabelle und dann die entsprechende Schemazuordnung aus.
Sie können bis zu 19 Dateneingaben hinzufügen.
Anmerkung
Um erweiterte Regeln verwenden zu können, müssen Ihre Schemazuordnungen die folgenden Anforderungen erfüllen:
-
Jedes Eingabefeld muss einem eindeutigen Übereinstimmungsschlüssel zugeordnet werden, sofern die Felder nicht zusammen gruppiert sind.
-
Wenn Eingabefelder zusammen gruppiert sind, können sie denselben Abgleichsschlüssel verwenden.
Die folgende Schemazuordnung wäre beispielsweise für erweiterte Regeln gültig:
firstName: { matchKey: 'name', groupName: 'name' }lastName: { matchKey: 'name', groupName: 'name' }In diesem Fall sind die
lastNameFelderfirstNameund zusammen gruppiert und haben den gleichen Namen (Match Key), was zulässig ist.Überprüfen Sie Ihre Schemazuordnungen und aktualisieren Sie sie so, dass sie dieser one-to-one Abgleichsregel entsprechen, sofern die Felder nicht ordnungsgemäß gruppiert sind, um erweiterte Regeln verwenden zu können.
-
Wenn Ihre Datentabelle eine DELETE-Spalte enthält, muss der Typ der Schemazuordnung lauten,
Stringund Sie dürfen kein und haben.matchKeygroupName
-
-
Die Option Daten normalisieren ist standardmäßig ausgewählt, sodass Dateneingaben vor dem Abgleich normalisiert werden. Wenn Sie Daten nicht normalisieren möchten, deaktivieren Sie die Option Daten normalisieren.
Anmerkung
Die Normalisierung wird nur für die folgenden Szenarien unter Schema-Mapping erstellen unterstützt:
-
Wenn die folgenden Namensuntertypen gruppiert sind: Vorname, Zweiter Vorname, Nachname.
-
Wenn die folgenden Adressuntertypen gruppiert sind: Straße 1, Straße 2, Straße 3, Stadt, Bundesland, Land, Postleitzahl.
-
Wenn die folgenden Telefonuntertypen gruppiert sind: Telefonnummer, Landesvorwahl des Telefons.
-
-
Um die Zugriffsberechtigungen für den Dienst festzulegen, wählen Sie eine Option und ergreifen Sie die empfohlene Maßnahme.
Option Empfohlene Aktion Erstellen und verwenden Sie eine neue Servicerolle -
AWS Entity Resolution erstellt eine Servicerolle mit der erforderlichen Richtlinie für diese Tabelle.
-
Der Standardname der Servicerolle lautet
entityresolution-matching-workflow-<timestamp>. -
Sie müssen über die erforderlichen Berechtigungen verfügen, um Rollen zu erstellen und Richtlinien anzuhängen.
-
Wenn Ihre Eingabedaten verschlüsselt sind, können Sie die Option Diese Daten werden mit einem KMS-Schlüssel verschlüsselt auswählen und dann einen AWS KMS Schlüssel eingeben, der zur Entschlüsselung Ihrer Dateneingabe verwendet wird.
Verwenden Sie eine vorhandene Servicerolle -
Wählen Sie einen vorhandenen Servicerollennamen aus der Dropdownliste aus.
Die Liste der Rollen wird angezeigt, wenn Sie berechtigt sind, Rollen aufzulisten.
Wenn Sie nicht berechtigt sind, Rollen aufzulisten, können Sie den Amazon-Ressourcennamen (ARN) der Rolle eingeben, die Sie verwenden möchten.
Wenn es keine vorhandenen Servicerollen gibt, ist die Option „Eine bestehende Servicerolle verwenden“ nicht verfügbar.
-
Rufen Sie die Servicerolle auf, indem Sie auf den externen Link In IAM anzeigen klicken.
Versucht standardmäßig AWS Entity Resolution nicht, die bestehende Rollenrichtlinie zu aktualisieren, um die erforderlichen Berechtigungen hinzuzufügen.
-
-
(Optional) Um Tags für die Ressource zu aktivieren, wählen Sie Neues Tag hinzufügen aus und geben Sie dann das Schlüssel - und Wertepaar ein.
-
Wählen Sie Weiter aus.
-
-
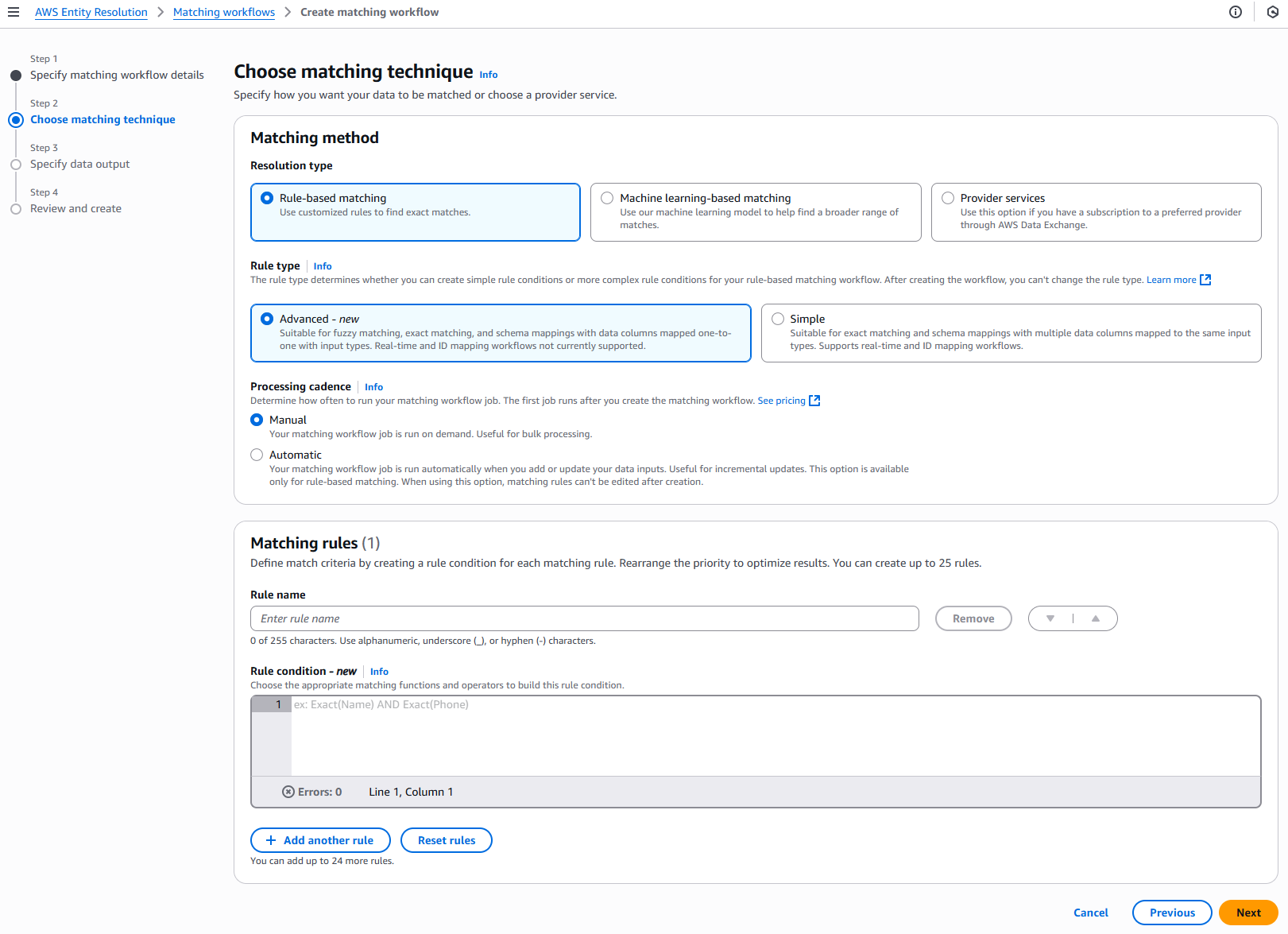
Für Schritt 2: Passende Technik wählen:
-
Wählen Sie unter Abgleichmethode die Option Regelbasierter Abgleich aus.
-
Wählen Sie als Regeltyp die Option Erweitert aus.
-
Wählen Sie für den Verarbeitungsrhythmus eine der folgenden Optionen aus.
-
Wählen Sie Manuell, um bei Bedarf einen Workflow für ein Massenupdate auszuführen
-
Wählen Sie Automatisch, um einen Workflow auszuführen, sobald sich neue Daten in Ihrem S3-Bucket befinden
Anmerkung
Wenn Sie Automatisch wählen, stellen Sie sicher, dass Sie EventBridge Amazon-Benachrichtigungen für Ihren S3-Bucket aktiviert haben. Anweisungen zur Aktivierung EventBridge von Amazon mithilfe der S3-Konsole finden Sie unter Enabling Amazon EventBridge im Amazon S3 S3-Benutzerhandbuch.
-
-
Geben Sie für Abgleichsregeln einen Regelnamen ein und erstellen Sie dann die Regelbedingung, indem Sie je nach Ziel die entsprechenden Abgleichsfunktionen und Operatoren aus der Dropdownliste auswählen.
Sie können bis zu 25 Regeln erstellen.
Sie müssen eine Fuzzy-Matching-Funktion (Cosinus, Levenshtein oder Soundex) mit einer exakten Matching-Funktion (Exact,) mithilfe des AND-Operators kombinieren. ExactManyToMany
Anhand der folgenden Tabelle können Sie entscheiden, welche Art von Funktion oder Operator Sie je nach Ziel verwenden möchten.
Ihr Ziel Empfohlene Funktion oder empfohlener Bediener Empfohlener optionaler Modifikator Vorteile Findet identische Zeichenketten bei genauen Daten, aber nicht bei leeren Werten. Exact (Genau) EmptyValues=Prozess Ordnet identische Zeichenketten auf genaue Daten zu und ignoriert leere Werte. Exakt ( matchKey)EmptyValues=Ignorieren Ordnet mehrere Datensätze anhand von Zuordnungsschlüsseln zu. Geeignet für flexible Paarungen. Limit: 15 passende Schlüssel ExactManyToMany( matchKey,matchKey, ...)– Messen Sie die Ähnlichkeit zwischen numerischen Repräsentationen von Daten, stimmen aber nicht mit leeren Werten überein. Geeignet für Text, Zahlen oder eine Mischung aus beidem. Kosinus EmptyValues=Prozess Einfach, effizient.
Funktioniert gut mit Langtext, wenn es mit der TF-IDF-Gewichtung kombiniert wird.
Gut für den exakten wortbasierten Abgleich.
Messen Sie die Ähnlichkeit zwischen numerischen Darstellungen von Daten und ignorieren Sie leere Werte. Kosinus ( matchKey,threshold,...)EmptyValues=Ignorieren Geht gut mit Tippfehlern, Rechtschreibfehlern und Transpositionen um.
Wirksam bei einer Vielzahl von PII-Typen.
Gut für kurze Zeichenketten (z. B. Namen oder Telefonnummern).
Zählen Sie die Mindestanzahl der Änderungen, die erforderlich sind, um ein Wort in ein anderes umzuwandeln, aber bei leeren Werten keine Übereinstimmung gefunden wird. Geeignet für Text mit leichten Unterschieden in der Schreibweise. Levenshtein EmptyValues=Prozess Zählen Sie die Mindestanzahl der Änderungen, die erforderlich sind, um ein Wort in ein anderes zu ändern, und ignorieren Sie leere Werte. Levenshtein ( matchKey,,threshold...)EmptyValues=Ignorieren Vergleichen und ordnen Sie Textzeichenfolgen danach zu, wie ähnlich sie klingen, aber bei leeren Werten nicht übereinstimmen. Geeignet für Text mit Variationen in der Schreibweise oder Aussprache. Soundex EmptyValues=Prozess Wirksam für den phonetischen Abgleich und die Identifizierung ähnlich klingender Wörter.
Schnell und rechnerisch günstig.
Gut geeignet, um Namen mit ähnlicher Aussprache, aber unterschiedlicher Schreibweise zusammenzubringen.
Vergleichen und ordnen Sie Textzeichenfolgen danach zu, wie ähnlich sie klingen, und ignorieren Sie leere Werte. Soundex () matchKeyEmptyValues=Ignorieren Kombinieren Sie Funktionen. UND – Separate Funktionen. ODER – Gruppieren Sie Bedingungen, um verschachtelte Bedingungen zu erstellen. (…) – Beispiel Regelbedingung, die bei Telefonnummern und E-Mails übereinstimmt
Im Folgenden finden Sie ein Beispiel für eine Regelbedingung, bei der Datensätze zu Telefonnummern (Telefonzuweisungsschlüssel) und E-Mail-Adressen (Abgleichsschlüssel für E-Mail-Adressen) abgeglichen werden:
Exact(Phone,EmptyValues=Process) AND Levenshtein("Email address",2)
Die Telefonzuordnungstaste verwendet die Funktion Exakter Abgleich, um identische Zeichenketten zuzuordnen. Die Taste Phone Match verarbeitet leere Werte beim Abgleich mit dem Modifikator EmptyValues=Process.
Der Abgleichsschlüssel für E-Mail-Adressen verwendet die Levenshtein-Vergleichsfunktion, um Daten mit Rechtschreibfehlern abzugleichen, wobei der standardmäßige Schwellenwert für den Levenshtein-Entfernungsalgorithmus von 2 verwendet wird. Der Abgleichsschlüssel für E-Mails verwendet keine optionalen Modifikatoren.
Der AND-Operator kombiniert die Genaue Übereinstimmungsfunktion und die Levenshtein-Matching-Funktion.
Beispiel Regelbedingung, die zur Durchführung des Matchkey-Matchings verwendet wird ExactManyToMany
Im Folgenden finden Sie ein Beispiel für eine Regelbedingung, die Datensätze in drei Adressfeldern (HomeAddressMatch-Schlüssel, Match-Schlüssel und BillingAddressMatch-Schlüssel) ShippingAddressabgleicht, um mögliche Treffer zu finden, indem geprüft wird, ob irgendwelche von ihnen identische Werte haben.
Der
ExactManyToManyOperator wertet alle möglichen Kombinationen der angegebenen Adressfelder aus, um genaue Übereinstimmungen zwischen zwei oder mehr beliebigen Adressen zu ermitteln. Beispielsweise würde er erkennen, ob die entwederHomeAddressmit oder übereinstimmenBillingAddressoderShippingAddressob alle drei Adressen exakt übereinstimmen.ExactManyToMany(HomeAddress, BillingAddress, ShippingAddress)Beispiel Regelbedingung, die Clustering verwendet
Beim erweiterten regelbasierten Abgleich mit Fuzzy-Bedingungen gruppiert das System Datensätze zunächst auf der Grundlage exakter Treffer in Clustern. Sobald diese anfänglichen Cluster gebildet sind, wendet das System Fuzzy-Matching-Filter an, um weitere Treffer innerhalb jedes Clusters zu identifizieren. Für eine optimale Leistung sollten Sie anhand Ihrer Datenmuster exakte Übereinstimmungsbedingungen auswählen, um gut definierte Ausgangscluster zu erstellen.
Im Folgenden finden Sie ein Beispiel für eine Regelbedingung, die mehrere exakte Treffer mit einer Fuzzy-Match-Anforderung kombiniert. Mithilfe von
ANDOperatoren wird überprüft, ob die drei Felder —FullName, Geburtsdatum (DOB) undAddress— zwischen den Datensätzen exakt übereinstimmen. Es ermöglicht auch geringfügige Abweichungen imInternalIDFeld unter Verwendung einer Levenshtein-Distanz von.1Die Levenshtein-Distanz gibt die Mindestanzahl von Änderungen an einzelnen Zeichen an, die erforderlich sind, um eine Zeichenfolge in eine andere zu ändern. Ein Abstand von 1 bedeutet,InternalIDsdass ein Treffer gefunden wird, der sich nur um ein Zeichen unterscheidet (z. B. ein einziger Tippfehler, eine Löschung oder eine Einfügung). Diese Kombination von Bedingungen hilft bei der Identifizierung von Datensätzen, bei denen es sehr wahrscheinlich ist, dass sie dieselbe Entität repräsentieren, auch wenn der Identifier kleine Abweichungen aufweist.Exact(FullName) AND Exact(DOB) AND Exact(Address) and Levenshtein(InternalID, 1) -
Wählen Sie Weiter aus.
-
-
Für Schritt 3: Datenausgabe und Format angeben:
-
Wählen Sie für Datenausgabeziel und -format den Amazon S3 S3-Speicherort für die Datenausgabe und ob das Datenformat Normalisierte Daten oder Originaldaten sein soll.
-
Wenn Sie unter Verschlüsselung die Verschlüsselungseinstellungen anpassen wählen, geben Sie den AWS KMS Schlüssel ARN ein.
-
Sehen Sie sich die vom System generierte Ausgabe an.
-
Entscheiden Sie für die Datenausgabe, welche Felder Sie einschließen, ausblenden oder maskieren möchten, und ergreifen Sie dann die empfohlenen Maßnahmen, die Ihren Zielen entsprechen.
Ihr Ziel Empfohlene Aktion Felder einbeziehen Behalten Sie den Ausgabestatus bei „Eingeschlossen“ bei. Felder ausblenden (von der Ausgabe ausschließen) Wählen Sie das Ausgabefeld und dann Ausblenden aus. Felder maskieren Wählen Sie das Ausgabefeld und dann Hash-Ausgabe aus. Setzen Sie die vorherigen Einstellungen zurück Klicken Sie auf Reset (Zurücksetzen). -
Wählen Sie Weiter aus.
-
-
Für Schritt 4: Überprüfen und erstellen:
-
Überprüfen Sie die Auswahlen, die Sie für die vorherigen Schritte getroffen haben, und bearbeiten Sie sie gegebenenfalls.
-
Wählen Sie Create and run aus.
Es wird eine Meldung angezeigt, die darauf hinweist, dass der passende Workflow erstellt und der Job gestartet wurde.
-
-
Sehen Sie sich auf der Seite mit den entsprechenden Workflow-Details auf der Registerkarte Metriken unter Metriken für den letzten Job Folgendes an:
-
Die Job-ID.
-
Der Status des passenden Workflow-Jobs: In Warteschlange, In Bearbeitung, Abgeschlossen, Fehlgeschlagen
-
Die Zeit, in der der Workflow-Job abgeschlossen wurde.
-
Die Anzahl der verarbeiteten Datensätze.
-
Die Anzahl der nicht verarbeiteten Datensätze.
-
Das IDs generierte eindeutige Match.
-
Die Anzahl der Eingabedatensätze.
Sie können auch die Job-Metriken für übereinstimmende Workflow-Jobs, die zuvor ausgeführt wurden, unter dem Jobverlauf anzeigen.
-
-
Nachdem der passende Workflow-Job abgeschlossen ist (Status ist Abgeschlossen), können Sie zur Registerkarte Datenausgabe wechseln und dann Ihren Amazon S3 S3-Standort auswählen, um die Ergebnisse anzuzeigen.
-
(Nur manueller Verarbeitungstyp) Wenn Sie einen regelbasierten Abgleichs-Workflow mit dem Verarbeitungstyp Manuell erstellt haben, können Sie den Abgleichs-Workflow jederzeit ausführen, indem Sie auf der Seite mit den entsprechenden Workflow-Details die Option Workflow ausführen wählen.
-
(Nur automatischer Verarbeitungstyp) Wenn Ihre Datentabelle eine DELETE-Spalte enthält, dann:
-
Datensätze, die
truein der DELETE-Spalte auf gesetzt sind, werden gelöscht. -
Datensätze, die
falsein der DELETE-Spalte auf gesetzt sind, werden in S3 aufgenommen.
Weitere Informationen finden Sie unter Schritt 1: Bereiten Sie Datentabellen von Erstanbietern vor.
-
-
- API
-
Um mithilfe der API einen regelbasierten Abgleichs-Workflow mit dem Regeltyp Advanced zu erstellen
Anmerkung
Standardmäßig verwendet der Workflow die Standardverarbeitung (Batch-) Verarbeitung. Um die inkrementelle (automatische) Verarbeitung zu verwenden, müssen Sie sie explizit konfigurieren.
-
Öffnen Sie ein Terminal oder eine Befehlszeile, um die API-Anfrage zu stellen.
-
Erstellen Sie eine POST-Anfrage an den folgenden Endpunkt:
/matchingworkflows -
Stellen Sie im Anforderungsheader den Inhaltstyp auf application/json ein.
-
Geben Sie für den Anfragetext die folgenden erforderlichen JSON-Parameter an:
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "stringWobei gilt:
-
workflowName(erforderlich) — Muss eindeutig sein und zwischen 1—255 Zeichen und dem Muster [a-zA-Z_0-9-] * entsprechen -
inputSourceConfig(erforderlich) — Liste mit 1—20 Eingangsquellenkonfigurationen -
outputSourceConfig(erforderlich) — Genau eine Konfiguration der Ausgangsquelle -
resolutionTechniques(erforderlich) — Für den regelbasierten Abgleich auf „RULE_MATCHING“ als ResolutionType setzen -
roleArn(erforderlich) — ARN der IAM-Rolle für die Workflow-Ausführung -
ruleConditionProperties(erforderlich) — Liste der Regelbedingungen und Name der passenden Regel.
Zu den optionalen Parametern gehören:
-
description— Bis zu 255 Zeichen -
incrementalRunConfig— Konfiguration des inkrementellen Ausführungstyps -
tags— Bis zu 200 Schlüssel-Wert-Paare
-
-
(Optional) Um die inkrementelle Verarbeitung anstelle der standardmäßigen Standardverarbeitung (Batch) zu verwenden, fügen Sie dem Hauptteil der Anfrage den folgenden Parameter hinzu:
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
Senden Sie die Anforderung .
-
Bei Erfolg erhalten Sie eine Antwort mit dem Statuscode 200 und einem JSON-Text, der Folgendes enthält:
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
Wenn der Anruf nicht erfolgreich ist, erhalten Sie möglicherweise einen der folgenden Fehler:
-
400 — ConflictException wenn der Workflow-Name bereits existiert
-
400 — ValidationException wenn die Eingabe nicht validiert werden kann
-
402 — ExceedsLimitException wenn die Kontolimits überschritten werden
-
403 — AccessDeniedException wenn Sie keinen ausreichenden Zugriff haben
-
429 — ThrottlingException wenn die Anfrage gedrosselt wurde
-
500 — InternalServerException wenn ein interner Dienstausfall vorliegt
-
-
