Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: Verwenden eines SageMaker Notebooks mit Ihrem Entwicklungsendpunkt
In AWS Glue können Sie einen Entwicklungsendpunkt und anschließend ein SageMaker Notebook erstellen, das Ihnen bei der Entwicklung Ihrer ETL- und Machine-Leaning-Skripte unterstützt. Bei einem SageMaker-Notebook handelt es sich um eine vollständig verwaltete Machine-Learning-Compute-Instance, auf der die Jupyter-Notebook-Anwendung ausgeführt wird.
-
Klicken Sie in der AWS Glue-Konsole auf Dev endpoints (Entwicklungsendpunkte), um zur Liste der Entwicklungsendpunkte zu navigieren.
-
Aktivieren Sie das Kontrollkästchen neben dem Namen eines Entwicklungsendpunkts, den Sie verwenden möchten, und wählen Sie im Menü Action (Aktion) die Option Create SageMaker notebook (SageMaker-Notebook erstellen).
-
Füllen Sie die Seite Create and configure a notebook (Notebook erstellen und konfigurieren) wie folgt aus:
-
Geben Sie einen Namen für das Notebook ein.
-
Überprüfen Sie unter Attach to development endpoint (An Entwicklungsendpunkt anfügen) den Entwicklungsendpunkt.
-
Erstellen Sie eine IAM-Rolle (AWS Identity and Access Management) oder wählen Sie eine aus.
Es wird empfohlen, eine Rolle zu erstellen. Wenn Sie eine vorhandene Rolle verwenden, stellen Sie sicher, dass sie über die erforderlichen Berechtigungen verfügt. Weitere Informationen finden Sie unter Schritt 6: Erstellen einer IAM-Richtlinie für SageMaker-Notebooks.
-
(Optional) Wählen Sie eine VPC, ein Subnetz und eine oder mehrere Sicherheitsgruppen aus.
-
(Optional) Wählen Sie einen AWS Key Management Service-Verschlüsselungsschlüssel.
-
(Optional) Fügen Sie Tags für die Notebook-Instance hinzu.
-
-
Klicken Sie auf Create Notebook (Notebook erstellen). Wählen Sie auf der Seite Notebooks das Aktualisierungssymbol oben rechts aus, und fahren Sie fort, bis der Status angezeigt wird
Ready. -
Aktivieren Sie das Kontrollkästchen neben dem neuen Notebooknamen, und wählen Sie Open notebook (Notebook öffnen).
-
Erstellen eines neuen Notebooks: Wählen Sie auf der Seite jupyter New (Neu) und dann Sparkmagic (PySpark) aus.
Ihr Bildschirm sollte jetzt wie folgt aussehen.
-
(Optional) Wählen Sie oben auf der Seite Untitled (Ohne Titel), und geben Sie dem Notebook einen Namen.
-
Um eine Spark-Anwendung zu starten, geben Sie den folgenden Befehl in das Notebook ein, und wählen Sie dann in der Symbolleiste Run (Ausführen) aus.
sparkNach einer kurzen Verzögerung sollten Sie die folgende Antwort sehen:
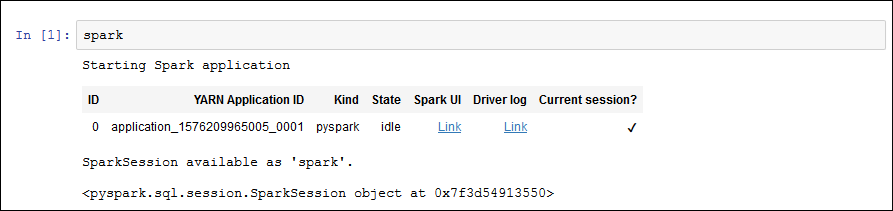
-
Erstellen Sie einen dynamischen Frame, und führen Sie eine Abfrage aus: Kopieren, Einfügen und Ausführen des folgenden Codes, der die Anzahl und das Schema der
persons_json-Tabelle ausgibt.import sys from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.transforms import * glueContext = GlueContext(SparkContext.getOrCreate()) persons_DyF = glueContext.create_dynamic_frame.from_catalog(database="legislators", table_name="persons_json") print ("Count: ", persons_DyF.count()) persons_DyF.printSchema()
