Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Tutorial: Erstellen einer Machine Learning-Transformation mit AWS Glue
Dieses Tutorial führt Sie durch die Aktionen zum Erstellen und Verwalten einer Machine Learning(ML)-Transformation mit AWS Glue. Bevor Sie dieses Tutorial verwenden, sollten Sie mit dem Hinzufügen von Crawlern und Aufträgen und dem Bearbeiten von Skripts mithilfe der AWS Glue-Konsole vertraut sein. Sie sollten auch wissen, wie Dateien gesucht und zur Amazon Simple Storage Service (Amazon S3)-Konsole heruntergeladen werden.
In diesem Beispiel erstellen Sie eine FindMatches-Transformation zur Suche nach übereinstimmenden Datensätzen, trainieren sie im Identifizieren übereinstimmender und nicht übereinstimmender Datensätze und verwenden sie in einem AWS Glue-Auftrag. Der AWS Glue-Auftrag schreibt eine neue Amazon-S3-Datei mit einer zusätzlichen Spalte mit dem Namen match_id.
Die in diesem Tutorial verwendeten Quelldaten befinden sich in einer Datei mit dem Namen dblp_acm_records.csv. Diese Datei ist eine modifizierte Version akademischer Publikationen (DBLP und ACM), die aus dem DBLP ACM-Originaldatensatzdblp_acm_records.csv ist eine CSV-Datei (durch Kommas voneinander getrennte Werte) im UTF-8-Format ohne BOM (Byte-Order Mark, Markierung der Byte-Reihenfolge).
Eine zweite Datei, dblp_acm_labels.csv, ist eine Labeling-Beispieldatei mit übereinstimmenden und nicht übereinstimmenden Datensätzen, mit der die Transformation im Rahmen des Tutorials trainiert wird.
Themen
Schritt 1: Crawlen der Quelldaten
Durchforsten Sie zunächst die Amazon-S3-CSV-Quelldatei, um eine entsprechende Metadatendatei in Data Catalog zu erstellen.
Wichtig
Um den Crawler dazu anzuweisen, eine Tabelle für ausschließlich die CSV-Datei zu erstellen, speichern Sie die CSV-Quelldaten in einem anderen Amazon-S3-Ordner als andere Dateien.
Melden Sie sich bei der an AWS Management Console und öffnen Sie die AWS Glue Konsole unter https://console.aws.amazon.com/glue/
. -
Wählen Sie im Navigationsbereich Crawlers (Crawler) und anschließend Add crawler (Crawler hinzufügen) aus.
-
Befolgen Sie die Anweisungen des Assistenten zum Erstellen und Ausführen eines Crawlers mit dem Namen
demo-crawl-dblp-acmmit Ausgabe zur Datenbankdemo-db-dblp-acm. Wenn der Assistent ausgeführt wird, erstellen Sie die Datenbankdemo-db-dblp-acm, sofern sie noch nicht vorhanden ist. Wählen Sie einen Amazon S3 S3-Include-Pfad für Beispieldaten in der aktuellen AWS Region. Fürus-east-1lautet der Amazon-S3-Include-Pfad zur Quelldatei beispielsweises3://ml-transforms-public-datasets-us-east-1/dblp-acm/records/dblp_acm_records.csv.Wenn der Crawler erfolgreich ist, erstellt er die Tabelle
dblp_acm_records_csvmit den folgenden Spalten: id (ID), title (Titel), authors (Autoren), venue (Ort), year (Jahr) und source (Quelle).
Schritt 2: Hinzufügen einer Machine Learning-Transformation
Fügen Sie als Nächstes eine Machine Learning-Transformation hinzu, die auf dem Schema Ihrer Datenquellentabelle basiert, die von dem Crawler mit dem Namen demo-crawl-dblp-acm erstellt wurde.
-
Wählen Sie auf der AWS Glue-Konsole im Navigationsbereich unter Datenintegration und ETL die Optionen Datenklassifizierungstools > Datensatzabgleich und anschließend Transformation hinzufügen aus. Folgen Sie dem Assistenten beim Erstellen einer
Find matches-Transformation mit den folgenden Eigenschaften.-
Geben Sie für Transform Name (Transformationsname) den Namen
demo-xform-dblp-acmein. Dies ist der Name der Transformation, der bei der Suche nach Übereinstimmungen in den Quelldaten verwendet wird. -
Wählen Sie für IAM role (IAM-Rolle) eine IAM-Rolle aus, die zum Zugriff auf die Amazon-S3-Quelldaten, Labeling-Datei und AWS Glue-API-Operationen berechtigt ist. Weitere Informationen finden Sie unter Erstellen einer IAM-Rolle für AWS Glue im AWS Glue -Entwicklerhandbuch.
-
Wählen Sie als Datenquelle die Tabelle mit dem Namen dblp_acm_records_csv in der Datenbank aus. demo-db-dblp-acm
-
Wählen Sie für Primary key (Primärschlüssel) die Primärschlüsselspalte für die Tabelle id aus.
-
Wählen Sie im Assistenten Finish (Fertig stellen) und kehren Sie zur Liste ML transforms (ML-Transformationen) zurück.
Schritt 3: Trainieren Ihrer Machine Learning-Transformation
Als Nächstes trainieren Sie Ihre Machine Learning-Transformation bei der Verwendung der Labeling-Beispieldatei des Tutorials.
Eine Machine Language-Transformation kann erst dann in einem ETL-Auftrag (Extract, Transform and Load, Extrahieren, Transformieren und Laden) verwendet werden, wenn ihr Status Ready for use (Einsatzbereit) lautet. Sie müssen Ihre Transformation als Vorbereitung anhand von Beispielen übereinstimmender und nicht übereinstimmender Datensätze darin trainieren, wie übereinstimmende und nicht übereinstimmende Datensätze zu identifizieren sind. Zum Trainieren Ihrer Transformation können Sie Generate a label file (Eine Labling-Datei generieren) wählen, Labels hinzufügen und danach Upload label file (Labeling-Datei hochladen) wählen. In diesem Tutorial verwenden Sie die Beispiel-Labeling-Datei dblp_acm_labels.csv. Weitere Informationen über den Labeling-Prozess finden Sie unter Labeling.
-
Wählen Sie im Navigationsbereich der AWS Glue-Konsole die Option Datensatzabgleich aus.
-
Wählen Sie die
demo-xform-dblp-acm-Transformation aus und klicken Sie dann auf Action (Aktion) und Teach (Trainieren). Befolgen Sie die Anweisungen des Assistenten zum Trainieren IhrerFind matches-Transformation. Wählen Sie auf der Eigenschaftsseite der Transformation I have labels (Im Besitz von Labels). Wählen Sie einen Amazon S3 S3-Pfad zur Musteretikettierungsdatei in der aktuellen AWS Region. Beispiel: Für
us-east-1laden Sie die bereitgestellte Labeling-Datei aus dem Amazon-S3-Pfads3://ml-transforms-public-datasets-us-east-1/dblp-acm/labels/dblp_acm_labels.csvmit der Option overwrite (Überschreiben), um vorhandene Labels zu überschreiben. Die Labeling-Datei muss sich in Amazon S3 in derselben Region wie die AWS Glue-Konsole befinden.Beim Hochladen einer Labeling-Datei wird in AWS Glue eine Aufgabe zum Hinzufügen oder Überschreiben der Labels gestartet, mit der die Transformation bei der Verarbeitung der Datenquelle trainiert wird.
Wählen Sie auf der letzten Seite des Assistenten Finish (Fertig stellen) und kehren Sie zur Liste ML transforms (ML-Transformationen) zurück.
Schritt 4: Beurteilen der Qualität Ihrer Machine Learning-Transformation
Anschließend können Sie die Qualität Ihrer Machine Learning-Transformation beurteilen. Die Qualität hängt vom Ausmaß des bisher von Ihnen vorgenommenen Labeling ab. Weitere Informationen zur Beurteilung der Qualität finden Sie unter Schätzen der Qualität.
-
Wählen Sie in der AWS Glue-Konsole im Navigationsbereich unter Datenintegration und ETL die Optionen Datenklassifizierungstools > Datensatzabgleich aus.
-
Wählen Sie die Transformation
demo-xform-dblp-acmund danach die Registerkarte Estimate quality (Qualität beurteilen) aus. Diese Registerkarte zeigt die aktuellen Qualitätsbeurteilungen für die Transformation an, sofern verfügbar. Wählen Sie Estimate quality (Qualität beurteilen), um eine Aufgabe zur Beurteilung der Qualität der Transformation zu starten. Die Genauigkeit der Qualitätsbeurteilung basiert auf dem Labeling der Quelldaten.
Navigieren Sie zur Registerkarte History (Verlauf). In diesem Bereich werden Aufgabenausführungen für die Transformation aufgelistet, einschließlich der Aufgabe Estimating quality (Qualitätsbeurteilung). Um weitere Einzelheiten zur Ausführung zur erhalten, wählen Sie Logs (Protokolle). Stellen Sie sicher, dass der Status der Ausführung Succeeded (Erfolgreich) lautet, wenn sie beendet ist.
Schritt 5: Hinzufügen und Ausführen eines Auftrags mit Ihrer Machine Learning-Transformation
In diesem Schritt verwenden Sie Ihre Machine Learning-Transformation zum Hinzufügen und Ausführen eines Auftrags in AWS Glue. Wenn dier Transformation demo-xform-dblp-acm Ready for use (Betriebsbereit) ist, können Sie sie in einem ETL-Auftrag verwenden.
-
Wählen Sie im Navigationsbereich der AWS Glue-Konsole die Option Jobs (Aufträge) aus.
-
Wählen Sie Add job (Auftrag hinzufügen) und befolgen Sie die Schritte im Assistenten zum Erstellen eines ETL-Spark-Auftrags mit einem generierten Skript. Wählen Sie die folgenden Eigenschaftswerte für Ihre Transformation aus:
-
Wählen Sie unter Name den Beispieljob in diesem Tutorial aus demo-etl-dblp-acm.
-
Wählen Sie unter IAM role (IAM-Rolle) eine IAM-Rolle mit der Berechtigung für die Amazon-S3-Quelldaten, die Labeling-Datei und AWS Glue-API-Operationen aus. Weitere Informationen finden Sie unter Erstellen einer IAM-Rolle für AWS Glue im AWS Glue -Entwicklerhandbuch.
-
Wählen Sie für ETL language (ETL-Sprache) die Option Scala aus. Das ist die Programmiersprache im ETL-Skript.
-
Wählen Sie als Namen der Skriptdatei die Option demo-etl-dblp-acm. Das ist der Dateiname der Scala-Skript (identisch mit dem Auftragsnamen).
-
Wählen Sie unter Data source (Datenquelle) als Quelle dblp_acm_records_csv aus. Die von Ihnen ausgewählte Datenquelle muss mit dem Datenquellen-Schema der Machine-Learning-Transformation übereinstimmen.
-
Wählen Sie unter Transform type (Transformationstyp) die Option Find matching records (Übereinstimmende Datensätze suchen) aus, um einen Auftrag mit einer Machine Learning-Transformation zu erstellen.
-
Deaktivieren Sie Remove duplicate records (Doppelte Datensätze entfernen). Doppelte Datensätze sollen nicht entfernt werden, da den geschriebenen Ausgabedatensätzen ein zusätziches
match_id-Feld hinzugefügt wird. -
Wählen Sie für Transformieren die Transformation für maschinelles Lernen aus demo-xform-dblp-acm, die für den Job verwendet wird.
-
Wählen Sie für Create tables in your data target (Tabellen in Ihren Zieldaten erstellen) das Erstellen von Tabellen mit den folgenden Eigenschaften:
-
Data store type (Datenspeichertyp) —
Amazon S3 -
Format —
CSV -
Compression type (Komprimierungstyp) —
None -
Zielpfad — Der Amazon S3 S3-Pfad, in den die Ausgabe des Jobs geschrieben wird (in der aktuellen AWS Konsolenregion)
-
-
-
Wählen Sie Save Job und edit script (Auftrag speichern und Skript bearbeiten), um die Skript-Editor-Seite anzuzeigen.
-
Bearbeiten Sie das Skript, um eine Anweisung hinzufügen, die verlasst, dass die Ausgabe zu Target path (Zielpfad) in eine einzelne Partitionsdatei geschrieben wird. Fügen Sie diese Anweisung unmittelbar nach der Anweisung ein, mit der die
FindMatches-Tansformation ausgeführt wird. Die Anweisung gleicht der folgenden.val single_partition = findmatches1.repartition(1)Sie müssen die Anweisung
.writeDynamicFrame(findmatches1)so ändern, dass die Ausgabe als.writeDynamicFrame(single_partion)geschrieben wird. -
Wählen Sie nach dem Bearbeiten des Skripts Save (Speichern). Das geänderte Skript sieht in etwa wie der folgende Code, aber angepasst an Ihre Umgebung, aus.
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.errors.CallSite import com.amazonaws.services.glue.ml.FindMatches import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import org.apache.spark.SparkContext import scala.collection.JavaConverters._ object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) // @type: DataSource // @args: [database = "demo-db-dblp-acm", table_name = "dblp_acm_records_csv", transformation_ctx = "datasource0"] // @return: datasource0 // @inputs: [] val datasource0 = glueContext.getCatalogSource(database = "demo-db-dblp-acm", tableName = "dblp_acm_records_csv", redshiftTmpDir = "", transformationContext = "datasource0").getDynamicFrame() // @type: FindMatches // @args: [transformId = "tfm-123456789012", emitFusion = false, survivorComparisonField = "<primary_id>", transformation_ctx = "findmatches1"] // @return: findmatches1 // @inputs: [frame = datasource0] val findmatches1 = FindMatches.apply(frame = datasource0, transformId = "tfm-123456789012", transformationContext = "findmatches1", computeMatchConfidenceScores = true)// Repartition the previous DynamicFrame into a single partition. val single_partition = findmatches1.repartition(1)// @type: DataSink // @args: [connection_type = "s3", connection_options = {"path": "s3://aws-glue-ml-transforms-data/sal"}, format = "csv", transformation_ctx = "datasink2"] // @return: datasink2 // @inputs: [frame = findmatches1] val datasink2 = glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions("""{"path": "s3://aws-glue-ml-transforms-data/sal"}"""), transformationContext = "datasink2", format = "csv").writeDynamicFrame(single_partition) Job.commit() } } Wählen Sie Run job (Auftrag ausführen), um die Auftragsausführung zu starten. Überprüfen Sie den Status des Auftrags in der Auftragsliste. Wenn der Auftrag abgeschlossen ist, wurde die Registerkarte ML transform (ML-Transformation), History (Verlauf) um eine neueRun ID (Ausführungs-ID)-Zeile vom Typ ETL job (ETL-Auftrag) erweitert.
Navigieren Sie zur Registerkarte Jobs (Aufträge), History (Verlauf). In diesem Bereich werden Auftragsausführungen aufgelistet. Um weitere Einzelheiten zur Ausführung zur erhalten, wählen Sie Logs (Protokolle). Stellen Sie sicher, dass der Status der Ausführung Succeeded (Erfolgreich) lautet, wenn sie beendet ist.
Schritt 6: Überprüfen der Ausgabedaten von Amazon S3
In diesem Schritt überprüfen Sie die Ausgabe der Auftragsausführung in dem Amazon-S3-Bucket, den Sie beim Hinzufügen des Auftrags ausgewählt haben. Sie können die Ausgabedatei auf Ihren lokalen Computer herunterladen und überprüfen, ob übereinstimmende Datensätze identifiziert wurden.
Öffnen Sie die Amazon S3 S3-Konsole unter https://console.aws.amazon.com/s3/
. Laden Sie die Ziel-Ausgabedatei des Auftrags
demo-etl-dblp-acmherunter. Öffnen Sie die Datei in einer Tabellenkalkulationsanwendung (Sie müssen möglicherweise die Dateierweiterung.csvanhängen, damit die Datei ordnunsgemäß geöffnet wird).Die folgende Abbildung zeigt einen Ausschnitt der Ausgabe in Microsoft Excel.
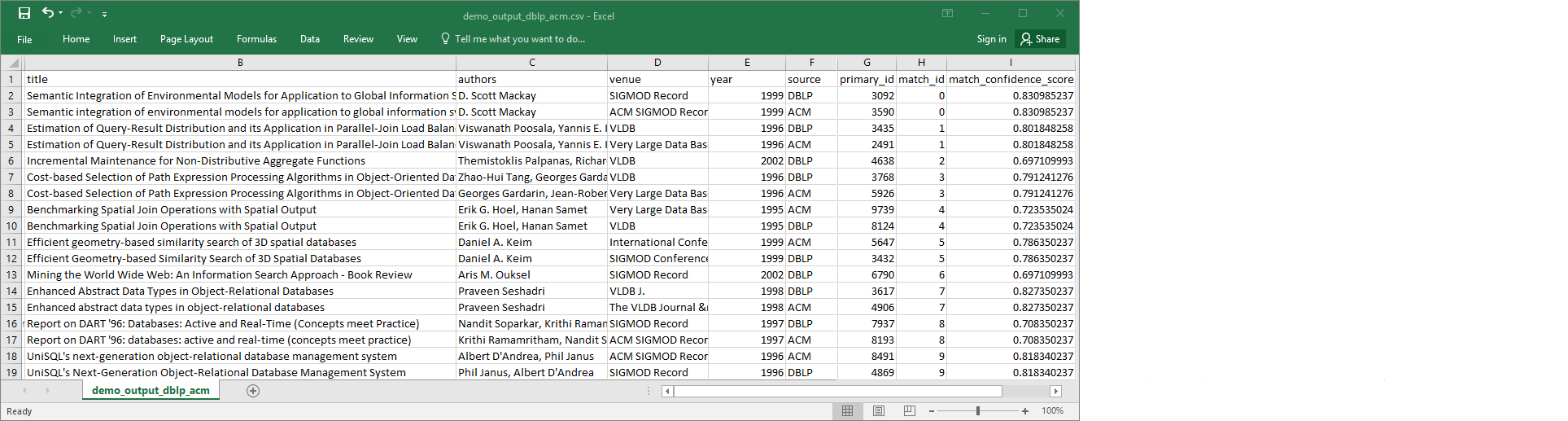
Die Datenquelle und die Zieldatei besitzen beide 4 911 Datensätze. Die Transformation
Find matchesfügt jedoch eine weitere Spalte mit dem Namenmatch_idzur Identifizierung übereinstimmender Datensätze in der Ausgabe hinzu. Zeilen mit derselbenmatch_idwerden als übereinstimmende Datensätze angesehen. Dermatch_confidence_scoreist eine Zahl zwischen 0 und 1, die eine Schätzung der Qualität der vonFind matchesgefundenen Übereinstimmungen liefert.-
Sortieren Sie die Ausgabedatei nach
match_id, damit übereinstimmende Datensätze leicht ersichtlich sind. Vergleichen Sie die Werte in den anderen Spalten, um festzustellen, ob Sie den Ergebnissen der TransformationFind matcheszustimmen. Wenn dies nicht der Fall ist, können Sie die Transformation durch Hinzufügen weiterer Labels weiter trainieren.Sie können die Datei auch nach einem anderen Feld, z B.
title, sortieren, um festzustellen, ob Datensätze mit ähnlichen Titeln dieselbematch_idbesitzen.
