Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Überwachen mit AWS Glue Beobachtbarkeitsmetriken
Anmerkung
AWS Glue Messwerte zur Beobachtbarkeit sind verfügbar unter AWS Glue 4.0 und spätere Versionen.
Verwenden Sie AWS Glue Messwerte zur Beobachtbarkeit, um Einblicke in das zu gewinnen, was in Ihrem Inneren passiert AWS Glue für Apache Spark-Jobs, um die Triaging und Analyse von Problemen zu verbessern. Beobachtbarkeitsmetriken werden über Amazon CloudWatch -Dashboards visualisiert und können verwendet werden, um die Ursache von Fehlern zu analysieren und Leistungsengpässe zu diagnostizieren. Sie können den Zeitaufwand für das Debuggen von Problemen reduzieren, sodass Sie sich darauf konzentrieren können, Probleme schneller und effektiver zu lösen.
AWS Glue Observability bietet Amazon CloudWatch Metriken, die in die folgenden vier Gruppen unterteilt sind:
-
Zuverlässigkeit (d. h. Fehlerklassen) – Identifizieren Sie ganz einfach die häufigsten Fehlerursachen in einem bestimmten Zeitraum, die Sie möglicherweise beheben möchten.
-
Leistung (d. h. Schiefe) – Identifizieren Sie Leistungsengpässe und wenden Sie Optimierungsmethoden an. Wenn Sie beispielsweise Leistungseinbußen aufgrund von Auftragsschiefe feststellen, können Sie die adaptive Abfrageausführung von Spark aktivieren und den Schwellenwert für schiefe Verknüpfungen anpassen.
-
Durchsatz (d. h. Durchsatz pro Quelle/Senke) – Überwachen Sie Trends bei Lese- und Schreibvorgängen. Sie können auch Amazon CloudWatch Alarme für Anomalien konfigurieren.
-
Ressourcenauslastung (d. h. Mitarbeiter, Speicher- und Festplattennutzung) – Lokalisieren Sie Aufträge mit geringer Kapazitätsauslastung auf effiziente Weise. Möglicherweise möchten Sie Folgendes aktivieren AWS Glue auto-scaling für diese Jobs.
Erste Schritte mit AWS Glue Beobachtbarkeitsmetriken
Anmerkung
Die neuen Metriken sind standardmäßig aktiviert in AWS Glue Studio console.
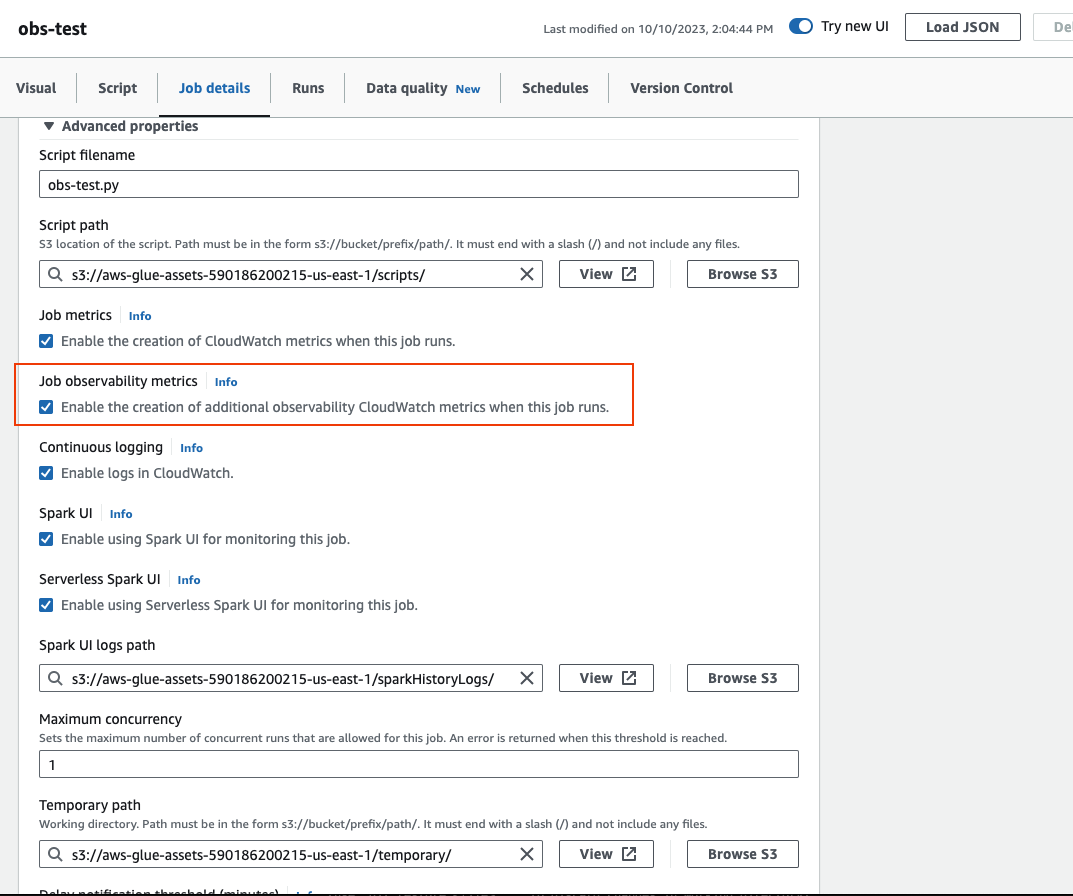
Um Beobachtbarkeitsmetriken zu konfigurieren in AWS Glue Studio:
-
Loggen Sie sich ein bei AWS Glue Konsole und wählen Sie im Konsolenmenü ETL-Jobs aus.
-
Klicken Sie im Bereich Ihre Aufträge auf den Namen des gewünschten Auftrags.
-
Wählen Sie die Registerkarte Job details (Auftragsdetails) aus.
-
Scrollen Sie nach unten, wählen Sie Erweiterte Eigenschaften und dann Metriken zur Auftragsbeobachtbarkeit aus.
Um zu aktivieren AWS Glue Messwerte zur Beobachtbarkeit unter Verwendung von AWS CLI:
-
Fügen Sie der
--default-arguments-Zuordnung in der JSON-Eingabedatei den folgenden Schlüsselwert hinzu:--enable-observability-metrics, true
Die Verwendung von AWS Glue observability
Weil die AWS Glue Observability-Metriken werden über bereitgestellt. Sie können die Amazon CloudWatch Konsole Amazon CloudWatch, das SDK oder die API verwenden AWS CLI, um die Datenpunkte der Observability-Metriken abzufragen. Ein Beispiel für einen Anwendungsfall finden Sie unter Verwenden von Glue Observability zur Überwachung der Ressourcennutzung zur Kostensenkung
Die Verwendung von AWS Glue Beobachtbarkeit in der Konsole Amazon CloudWatch
Um Metriken in der Amazon CloudWatch Konsole abzufragen und zu visualisieren:
-
Öffnen Sie die Amazon CloudWatch Konsole und wählen Sie Alle Metriken aus.
-
Wählen Sie unter Benutzerdefinierte Namespaces AWS Glue.
-
Wählen Sie „Metriken zur Auftragsbeobachtbarkeit“, „Beobachtbarkeitsmetriken pro Quelle“ oder „Beobachtbarkeitsmetriken pro Senke“ aus.
-
Suchen Sie nach dem gewünschten Metrik- und Auftragsnamen sowie der Auftragsausführungs-ID und wählen Sie sie aus.
-
Konfigurieren Sie auf der Registerkarte Grafische Metriken Ihre bevorzugte Statistik, den Zeitraum und andere Optionen.

Um eine Observability-Metrik abzufragen, verwenden Sie AWS CLI:
-
Erstellen Sie eine JSON-Datei mit einer Metrikdefinition und ersetzen Sie
your-Glue-job-nameundyour-Glue-job-run-idmit Ihren Werten.$ cat multiplequeries.json [ { "Id": "avgWorkerUtil_0", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-A>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-A>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } }, { "Id": "avgWorkerUtil_1", "MetricStat": { "Metric": { "Namespace": "Glue", "MetricName": "glue.driver.workerUtilization", "Dimensions": [ { "Name": "JobName", "Value": "<your-Glue-job-name-B>" }, { "Name": "JobRunId", "Value": "<your-Glue-job-run-id-B>" }, { "Name": "Type", "Value": "gauge" }, { "Name": "ObservabilityGroup", "Value": "resource_utilization" } ] }, "Period": 1800, "Stat": "Minimum", "Unit": "None" } } ] -
Führen Sie den Befehl
get-metric-dataaus:$ aws cloudwatch get-metric-data --metric-data-queries file: //multiplequeries.json \ --start-time '2023-10-28T18: 20' \ --end-time '2023-10-28T19: 10' \ --region us-east-1 { "MetricDataResults": [ { "Id": "avgWorkerUtil_0", "Label": "<your-label-for-A>", "Timestamps": [ "2023-10-28T18:20:00+00:00" ], "Values": [ 0.06718750000000001 ], "StatusCode": "Complete" }, { "Id": "avgWorkerUtil_1", "Label": "<your-label-for-B>", "Timestamps": [ "2023-10-28T18:50:00+00:00" ], "Values": [ 0.5959183673469387 ], "StatusCode": "Complete" } ], "Messages": [] }
Beobachtbarkeitsmetriken
AWS Glue Observability erstellt Amazon CloudWatch alle 30 Sekunden ein Profil der folgenden Metriken und sendet sie. Einige dieser Metriken können in der AWS Glue Studio Seite „Überwachung von Auftragsausführungen“.
| Metrik | Beschreibung | Kategorie |
|---|---|---|
| glue.driver.skewness.stage |
Metrikkategorie: job_performance Abweichungen bei der Ausführung von Spark-Phasen: Diese Metrik erfasst Abweichungen bei der Ausführung, die durch schiefe Eingabedaten oder durch eine Transformation (z. B. schiefe Verknüpfung) verursacht werden. Die Werte dieser Metrik fallen in den Bereich [0, unendlich[, wobei 0 bedeutet, dass der Unterschied zwischen der maximalen und der mittleren Ausführungszeit von Aufgaben in der Phase weniger beträgt als ein bestimmter Phasenabweichungsfaktor. Der Standardabweichungsfaktor von Phasen ist „5“ und wird mit dieser Spark-Konfiguration überschrieben: spark.metrics.conf.driver.source.glue.jobPerformance.skewnessFactor Ein Wert von 1 für die Phasenabweichung bedeutet, dass der Unterschied das Doppelte des Abweichungsfaktors der Phase beträgt. Der Wert der Stufenschiefe wird alle 30 Sekunden aktualisiert, um die aktuelle Schiefe widerzuspiegeln. Der Wert am Ende der Phase spiegelt die Schiefe der letzten Phase wider. Gültige Abmessungen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (job_performance) Gültige Statistiken: Durchschnitt, Maximum, Minimum, Prozent Einheit: Anzahl |
job_performance |
| glue.driver.skewness.job |
Metrikkategorie: job_performance Die Auftragsabweichung ist der gewichtete Durchschnitt der Abweichungen in den Auftragsphasen. Der gewichtete Durchschnitt misst Phasen, deren Ausführung länger dauert, eine größere Bedeutung bei. Auf diese Weise soll der Ausnahmefall vermieden werden, bei dem eine stark abweichende Phase im Vergleich zu anderen Phasen tatsächlich nur für eine sehr kurze Zeit ausgeführt wird (und ihre Abweichung daher für die gesamte Auftragsleistung nicht signifikant ist und es sich nicht lohnt, diese Abweichung zu beheben). Diese Metrik wird nach Abschluss jeder Phase aktualisiert, sodass der letzte Wert die tatsächliche Gesamtabweichung des Auftrags widerspiegelt. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (job_performance) Gültige Statistiken: Durchschnitt, Maximum, Minimum, Prozent Einheit: Anzahl |
job_performance |
| glue.succeed.ALL |
Metrikkategorie: Fehler Gesamtzahl der erfolgreichen Auftragsausführungen, für ein vollständiges Bild der Fehlerkategorien Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Anzahl) und ObservabilityGroup (Fehler) Gültige Statistiken: SUM Einheit: Anzahl |
error |
| glue.error.ALL |
Metrikkategorie: Fehler Gesamtzahl der Fehler bei Auftragsausführungen, für ein vollständiges Bild der Fehlerkategorien Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Anzahl) und ObservabilityGroup (Fehler) Gültige Statistiken: SUM Einheit: Anzahl |
error |
| glue.error.[Fehlerkategorie] |
Metrikkategorie: Fehler Dabei handelt es sich um eine Reihe von Metriken, die nur aktualisiert werden, wenn eine Auftragsausführung fehlschlägt. Die Fehlerkategorisierung hilft bei der Analyse und dem Debugging. Wenn eine Auftragsausführung fehlschlägt, wird der Fehler, der dazu geführt hat, kategorisiert und die entsprechende Metrik für die Fehlerkategorie wird auf 1 gesetzt. Dies hilft bei der Durchführung von Fehleranalysen im Laufe der Zeit sowie bei der Fehleranalyse für alle Jobs, um die häufigsten Fehlerkategorien zu identifizieren und mit deren Behebung zu beginnen. AWS Glue hat 28 Fehlerkategorien, darunter die Fehlerkategorien OUT_OF_MEMORY (Treiber und Executor), PERMISSION, SYNTAX und THROTTLING. Weitere Fehlerkategorien sind unter anderem COMPILATION, LAUNCH und TIMEOUT. Gültige Dimensionen: (der Name der JobName AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Anzahl) und ObservabilityGroup (Fehler) Gültige Statistiken: SUM Einheit: Anzahl |
error |
| glue.driver.workerUtilization |
Metrikkategorie: resource_utilization Der Prozentsatz der zugewiesenen Arbeitskräfte, die tatsächlich eingesetzt werden. Wenn nicht gut, kann Auto Scaling helfen. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt, Maximum, Minimum, Prozent Einheit: Prozentsatz |
resource_utilization |
| glue.driver.memory.heap.[verfügbar | belegt] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Heap-Speicher des Treibers während der Auftragsausführung. Dies hilft, Trends bei der Speichernutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit Speicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Byte |
resource_utilization |
| glue.driver.memory.heap.used.percentage |
Metrikkategorie: resource_utilization Der belegte Heap-Speicher des Treibers während der Auftragsausführung (in %). Dies hilft, Trends bei der Speichernutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit Speicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.driver.memory.non-heap.[verfügbar | belegt] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Non-Heap-Speicher des Treibers während der Auftragsausführung. Dies hilft, Trends bei der Speichernutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit Speicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Byte |
resource_utilization |
| glue.driver.memory.non-heap.used.percentage |
Metrikkategorie: resource_utilization Der belegte Non-Heap-Speicher des Treibers während der Auftragsausführung (in %). Dies hilft, Trends bei der Speichernutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit Speicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.driver.memory.total.[verfügbar | belegt] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Gesamtspeicher des Treibers während der Auftragsausführung. Dies hilft, Trends bei der Speichernutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit Speicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Byte |
resource_utilization |
| glue.driver.memory.total.used.percentage |
Metrikkategorie: resource_utilization Der belegte Gesamtspeicher des Treibers während der Auftragsausführung (in %). Dies hilft, Trends bei der Speichernutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit Speicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.ALL.memory.heap.[verfügbar | belegt] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Heap-Speicher der Executoren. ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Byte |
resource_utilization |
| glue.ALL.memory.heap.used.percentage |
Metrikkategorie: resource_utilization Der belegte Heap-Speicher der Executoren (in %). ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.ALL.memory.non-heap.[verfügbar | belegt] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Non-Heap-Speicher der Executoren. ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Byte |
resource_utilization |
| glue.ALL.memory.non-heap.used.percentage |
Metrikkategorie: resource_utilization Der belegte Non-Heap-Speicher der Executoren (in %). ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.ALL.memory.total.[verfügbar | belegt] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Gesamtspeicher der Executoren. ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Byte |
resource_utilization |
| glue.ALL.memory.total.used.percentage |
Metrikkategorie: resource_utilization Der belegte Gesamtspeicher der Executoren (in %). ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.driver.disk.[available_GB | used_GB] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Festplattenspeicher des Treibers während der Auftragsausführung. Dies hilft, Trends bei der Festplattennutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit zu wenig Festplattenspeicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Gigabyte |
resource_utilization |
| glue.driver.disk.used.percentage] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Festplattenspeicher des Treibers während der Auftragsausführung. Dies hilft, Trends bei der Festplattennutzung zu verstehen, insbesondere im Zeitverlauf, wodurch potenzielle Ausfälle vermieden werden. Außerdem können Ausfälle im Zusammenhang mit zu wenig Festplattenspeicher behoben werden. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.ALL.disk.[available_GB | used_GB] |
Metrikkategorie: resource_utilization Der verfügbare/belegte Festplattenspeicher der Executoren. ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Gigabyte |
resource_utilization |
| glue.ALL.disk.used.percentage |
Metrikkategorie: resource_utilization Der Festplattenspeicher (%) der Executorenavailable/used/used. ALL bedeutet alle Executoren. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Typ (Gauge) und ObservabilityGroup (resource_utilization) Gültige Statistiken: Durchschnitt Einheit: Prozentsatz |
resource_utilization |
| glue.driver.bytesRead |
Metrikkategorie: Durchsatz Die Anzahl der in dieser Auftragsausführung pro Eingabequelle sowie für ALL-Quellen gelesenen Byte. Dies hilft, das Datenvolumen und seine Veränderungen im Laufe der Zeit besser zu verstehen und Probleme wie Datenabweichungen zu lösen. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Type (Gauge), ObservabilityGroup (resource_utilization) und Source (Quelldatenposition) Gültige Statistiken: Durchschnitt Einheit: Byte |
Durchsatz |
| glue.driver.[recordsRead | filesRead] |
Metrikkategorie: Durchsatz Die Anzahl der in dieser Auftragsausführung pro Eingabequelle sowie für ALL-Quellen gelesenen Datensätze/Dateien. Dies hilft, das Datenvolumen und seine Veränderungen im Laufe der Zeit besser zu verstehen und Probleme wie Datenabweichungen zu lösen. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Type (Gauge), ObservabilityGroup (resource_utilization) und Source (Quelldatenposition) Gültige Statistiken: Durchschnitt Einheit: Anzahl |
Durchsatz |
| glue.driver.partitionsRead |
Metrikkategorie: Durchsatz Die Anzahl der in dieser Auftragsausführung pro Amazon-S3-Eingabequelle sowie für ALL-Quellen gelesenen Partitionen. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Type (Gauge), ObservabilityGroup (resource_utilization) und Source (Quelldatenposition) Gültige Statistiken: Durchschnitt Einheit: Anzahl |
Durchsatz |
| glue.driver.bytesWritten |
Metrikkategorie: Durchsatz Die Anzahl der in dieser Auftragsausführung pro Ausgabe-Sink sowie für ALL-Sinks geschriebenen Byte. Dies hilft, das Datenvolumen und seine Entwicklung im Laufe der Zeit besser zu verstehen und Probleme wie Verarbeitungsabweichungen zu lösen. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Type (Gauge), ObservabilityGroup (resource_utilization) und Sink (Speicherort der Senkendaten) Gültige Statistiken: Durchschnitt Einheit: Byte |
Durchsatz |
| glue.driver.[recordsWritten | filesWritten] |
Metrikkategorie: Durchsatz Die Anzahl der in dieser Auftragsausführung pro Ausgabe-Sink sowie für ALL-Sinks geschriebenen Datensätze/Dateien. Dies hilft, das Datenvolumen und seine Entwicklung im Laufe der Zeit besser zu verstehen und Probleme wie Verarbeitungsabweichungen zu lösen. Gültige Dimensionen: JobName (der Name der AWS Glue Job), JobRunId (die JobRun ID oder ALL), Type (Gauge), ObservabilityGroup (resource_utilization) und Sink (Speicherort der Senkendaten) Gültige Statistiken: Durchschnitt Einheit: Anzahl |
Durchsatz |
Fehlerkategorien
| Fehlerkategorien | Beschreibung |
|---|---|
| COMPILATION_ERROR | Bei der Kompilierung von Scala-Code treten Fehler auf. |
| CONNECTION_ERROR | Beim Herstellen einer Verbindung zu einem service/remote host/database Dienst usw. treten Fehler auf. |
| DISK_NO_SPACE_ERROR |
Wenn auf der Festplatte des Treibers/Executors kein Speicherplatz mehr vorhanden ist, treten Fehler auf. |
| OUT_OF_MEMORY_ERROR | Wenn auf dem Speicher des Treibers/Executors kein Speicherplatz mehr vorhanden ist, treten Fehler auf. |
| IMPORT_ERROR | Beim Import von Abhängigkeiten treten Fehler auf. |
| INVALID_ARGUMENT_ERROR | Fehler treten auf, wenn die Eingabeargumente ungültig/illegal sind. |
| PERMISSION_ERROR | Wenn die Genehmigung für Services, Daten usw. fehlt, treten Fehler auf. |
| RESOURCE_NOT_FOUND_ERROR |
Wenn Daten, Speicherorte usw. nicht existieren, treten Fehler auf. |
| QUERY_ERROR | Bei der Ausführung von Spark-SQL-Abfragen treten Fehler auf. |
| SYNTAX_ERROR | Wenn das Skript einen Syntaxfehler enthält, treten Fehler auf. |
| THROTTLING_ERROR | Wenn die Beschränkung der Parallelität von Services erreicht oder die Beschränkung der Service Quotas überschritten wird, treten Fehler auf. |
| DATA_LAKE_FRAMEWORK_ERROR | Fehler entstehen durch AWS Glue nativ unterstütztes Data-Lake-Framework wie Hudi, Iceberg usw. |
| UNSUPPORTED_OPERATION_ERROR | Wenn ein Vorgang ausgeführt wird, der nicht unterstützt wird, treten Fehler auf. |
| RESOURCES_ALREADY_EXISTS_ERROR | Wenn eine Ressource, die erstellt oder hinzugefügt werden soll, bereits vorhanden ist, treten Fehler auf. |
| GLUE_INTERNAL_SERVICE_ERROR | Fehler treten auf, wenn es eine AWS Glue internes Serviceproblem. |
| GLUE_OPERATION_TIMEOUT_ERROR | Fehler treten auf, wenn ein AWS Glue Der Vorgang ist Timeout. |
| GLUE_VALIDATION_ERROR | Fehler treten auf, wenn ein erforderlicher Wert nicht validiert werden konnte AWS Glue Arbeit. |
| GLUE_JOB_BOOKMARK_VERSION_MISMATCH_ERROR | Wenn derselbe Auftrag auf demselben Quell-Bucket ausgeführt und gleichzeitig auf dasselbe/unterschiedliche Ziel geschrieben wird (Gleichzeitigkeit >1), treten Fehler auf. |
| LAUNCH_ERROR | Fehler entstehen während der AWS Glue Phase der Jobeinführung. |
| DYNAMODB_ERROR | Generische Fehler entstehen durch Amazon DynamoDB den Service. |
| GLUE_ERROR | Generische Fehler entstehen durch AWS Glue Service. |
| LAKEFORMATION_ERROR | Generische Fehler entstehen durch AWS Lake Formation den Service. |
| REDSHIFT_ERROR | Generische Fehler entstehen durch Amazon Redshift den Service. |
| S3_ERROR | Der Amazon–S3-Service ruft generische Fehler hervor. |
| SYSTEM_EXIT_ERROR | Generischer Fehler beim Beenden des Systems. |
| TIMEOUT_ERROR | Wenn der Auftrag aufgrund eines Timeouts fehlschlägt, treten generische Fehler auf. |
| UNCLASSIFIED_SPARK_ERROR | Spark ruft generische Fehler hervor. |
| UNCLASSIFIED_ERROR | Standard-Fehlerkategorie. |
Einschränkungen
Anmerkung
glueContext muss initialisiert werden, um die Metriken zu veröffentlichen.
In der Quelldimension ist der Wert je nach Quelltyp entweder ein Amazon-S3-Pfad oder Tabellenname. Wenn es sich bei der Quelle um JDBC handelt und die Abfrageoption verwendet wird, wird die Abfragezeichenfolge außerdem in der Quelldimension festgelegt. Wenn der Wert länger als 500 Zeichen ist, wird er auf 500 Zeichen gekürzt. Für den Wert gelten folgende Einschränkungen:
-
Nicht-ASCII-Zeichen werden entfernt.
Wenn der Quellname kein ASCII-Zeichen enthält, wird er in <Nicht-ASCII-Eingabe> umgewandelt.
Einschränkungen und Überlegungen zu Durchsatzmetriken
-
DataFrame und DataFrame based DynamicFrame (z. B. JDBC, Lesen von Parquet auf Amazon S3) werden unterstützt, RDD-basiert DynamicFrame (z. B. Lesen von CSV, JSON auf Amazon S3 usw.) wird jedoch nicht unterstützt. Technisch gesehen werden alle Lese- und Schreibvorgänge, die auf der Spark-Benutzeroberfläche sichtbar sind, unterstützt.
-
Die
recordsRead-Metrik wird ausgegeben, wenn es sich bei der Datenquelle um eine Katalogtabelle handelt und das Format JSON, CSV, Text oder Iceberg ist. -
Die Metriken
glue.driver.throughput.recordsWritten,glue.driver.throughput.bytesWrittenundglue.driver.throughput.filesWrittensind in JDBC- und Iceberg-Tabellen nicht verfügbar. -
Metriken können verzögert sein. Wenn der Job in etwa einer Minute abgeschlossen ist, gibt es unter Metrics möglicherweise keine Durchsatzmetriken. Amazon CloudWatch
