Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Lambda-Ereignisquellenzuweisung
Anmerkung
Wenn Sie Daten an ein anderes Ziel als eine Lambda-Funktion senden oder die Daten vor dem Senden anreichern möchten, finden Sie weitere Informationen unter Amazon EventBridge Pipes.
Eine Ereignisquellenzuordnung ist eine Lambda-Ressource, die aus einer Ereignisquelle liest und eine Lambda-Funktion aufruft. Sie können Ereignisquellen-Zuweisungen zum Verarbeiten von Elementen aus einem Stream oder einer Warteschlange in Services verwenden, die keine Lambda-Funktionen direkt aufrufen. Auf dieser Seite werden die Services beschrieben, die Lambda für Zuordnungen von Ereignisquellen bereitstellt, und die Feinabstimmung des Batching-Verhaltens.
Services, aus denen Lambda Ereignisse liest
Eine Ereignisquellen-Zuweisung verwendet die Berechtigungen in der Ausführungsrolle der Funktion zum Lesen und Verwalten von Elementen in der Ereignisquelle. Berechtigungen, Ereignisstruktur, Einstellungen und Abrufverhalten variieren je nach Ereignisquelle. Weitere Informationen finden Sie in dem verküpften Thema für den Service, den Sie als Ereignisquelle verwenden.
Um eine Ereignisquelle mit der AWS Command Line Interface (AWS CLI) oder einem AWS
Warnung
Lambda-Ereignisquellenzuordnungen verarbeiten jedes Ereignis mindestens einmal, und eine doppelte Verarbeitung von Batches kann auftreten. Um potenzielle Probleme im Zusammenhang mit doppelten Ereignissen zu vermeiden, empfehlen wir dringend, Ihren Funktionscode idempotent zu machen. Weitere Informationen finden Sie unter Wie mache ich meine Lambda-Funktion idempotent
Erstellen einer Ereignisquellenzuordnung
Um eine Zuordnung zwischen einer Ereignisquelle und einer Lambda-Funktion zu erstellen, erstellen Sie einen Auslöser in der Konsole oder verwenden Sie den create-event-source-mapping
So fügen Sie Berechtigungen hinzu und erstellen einen Auslöser
-
Fügen Sie Ihrer Ausführungsrolle die erforderlichen Berechtigungen hinzu. Einige Services, wie Amazon SQS, verfügen über eine von AWS verwaltete Richtlinie, die die Berechtigungen enthält, die Lambda zum Lesen aus Ihrer Ereignisquelle benötigt.
Öffnen Sie die Seite Funktionen
der Lambda-Konsole. -
Wählen Sie den Namen einer Funktion aus.
-
Wählen Sie unter Function overview (Funktionsübersicht) die Option Add trigger (Trigger hinzufügen).
-
Wählen Sie einen Auslösertyp aus.
-
Konfigurieren Sie die erforderlichen Optionen und wählen Sie dann Add (Hinzufügen) aus.
So erstellen Sie eine Zuordnung von Ereignisquellen (AWS CLI)
Im folgenden Beispiel wird die verwendet AWS CLI , my-function um eine Funktion mit dem Namen einem DynamoDB-Stream zuzuordnen, den ihr Amazon-Ressourcenname (ARN) angibt, mit einer Batchgröße von 500.
aws lambda create-event-source-mapping --function-name my-function --batch-size 500 --maximum-batching-window-in-seconds 5 --starting-position LATEST \ --event-source-arn arn:aws:dynamodb:us-east-2:123456789012:table/my-table/stream/2023-06-10T19:26:16.525
Die Ausgabe sollte folgendermaßen aussehen:
{ "UUID": "14e0db71-5d35-4eb5-b481-8945cf9d10c2", "BatchSize": 500, "MaximumBatchingWindowInSeconds": 5, "ParallelizationFactor": 1, "EventSourceArn": "arn:aws:dynamodb:us-east-2:123456789012:table/my-table/stream/2019-06-10T19:26:16.525", "FunctionArn": "arn:aws:lambda:us-east-2:123456789012:function:my-function", "LastModified": 1560209851.963, "LastProcessingResult": "No records processed", "State": "Creating", "StateTransitionReason": "User action", "DestinationConfig": {}, "MaximumRecordAgeInSeconds": 604800, "BisectBatchOnFunctionError": false, "MaximumRetryAttempts": 10000 }
Aktualisieren einer Zuordnung von Ereignisquellen
So aktualisieren Sie eine Zuordnung von Ereignisquellen (Konsole)
Öffnen Sie die Seite Funktionen
der Lambda-Konsole. -
Wählen Sie eine Funktion aus.
-
Wählen Sie Konfiguration und dann Auslöser aus.
-
Wählen Sie den Auslöser und dann Bearbeiten aus.
So aktualisieren Sie eine Zuordnung von Ereignisquellen (AWS CLI)
Verwenden Sie den update-event-source-mapping
aws lambda update-event-source-mapping \ --uuid"a1b2c3d4-5678-90ab-cdef-11111EXAMPLE"\ --scaling-config'{"MaximumConcurrency":5}'
Löschen einer Ereignisquellenzuordnung
Wenn Sie eine Funktion löschen, löscht Lambda keine zugehörigen Ereignisquellenzuordnungen. Sie können Ereignisquellenzuordnungen in der Konsole oder mithilfe der DeleteEventSourceMapping -API-Aktion löschen.
So löschen Sie Ereignisquellenzuordnungen (Konsole)
-
Öffnen Sie die Seite Ereignisquellenzuordnungen
der Lambda-Konsole. -
Wählen Sie die Ereignisquellenzuordnungen aus, die Sie löschen möchten.
-
Geben Sie im Dialogfeld Ereignisquellenzuordnungen löschen Löschen ein und wählen Sie dann Löschen aus.
So löschen Sie eine Ereignisquellenzuordnung (AWS CLI)
Verwenden Sie den delete-event-source-mapping
aws lambda delete-event-source-mapping \ --uuida1b2c3d4-5678-90ab-cdef-11111EXAMPLE
Batching-Verhalten
Ereignisquellenzuordnungen lesen Elemente aus einer Zielereignisquelle. Standardmäßig batcht eine Ereignisquellenzuordnung Datensätze in einer einzigen Nutzlast, die Lambda an Ihre Funktion sendet. Um das Batching-Verhalten zu optimieren, können Sie ein Batching-Fenster (MaximumBatchingWindowInSeconds) und eine Batch-Größe (BatchSize) konfigurieren. Ein Batch-Fenster ist die maximale Zeitspanne zur Erfassung von Datensätzen in einer einzigen Nutzlast. Eine Batch-Größe ist die maximale Anzahl von Datensätzen in einem einzigen Batch. Lambda ruft Ihre Funktion auf, wenn eines der folgenden drei Kriterien erfüllt ist:
-
Das Batching-Fenster erreicht seinen Maximalwert. Das Standardverhalten des Batch-Fensters variiert je nach Ereignisquelle.
Für Kinesis-, DynamoDB- und Amazon SQS SQS-Ereignisquellen: Das Standard-Batch-Fenster beträgt 0 Sekunden. Das bedeutet, dass Lambda Batches nur dann an Ihre Funktion sendet, wenn entweder die Batchgröße oder die Nutzlastgrößenbeschränkung erreicht ist. Um ein Batch-Fenster festzulegen, konfigurieren Sie
MaximumBatchingWindowInSeconds. Sie können diesen Parameter auf einen beliebigen Wert zwischen 0 und 300 Sekunden in Schritten von 1 Sekunde festlegen. Wenn Sie ein Batch-Fenster konfigurieren, beginnt das nächste Fenster, sobald der vorherige Funktionsaufruf abgeschlossen ist.Für Amazon-MSK-, selbstverwaltete Apache-Kafka-, Amazon-MQ- und Amazon-DocumentDB-Ereignisquellen: Das standardmäßige Batching-Fenster beträgt 500 ms. Sie können
MaximumBatchingWindowInSecondsauf einen beliebigen Wert von 0 Sekunden bis 300 Sekunden in Sekundenschritten einstellen. Ein Batch-Fenster beginnt, sobald der erste Datensatz eintrifft.Anmerkung
Da Sie
MaximumBatchingWindowInSecondsnur in Sekundenschritten ändern können, können Sie nicht zu dem Standard-Batch-Fenster von 500 ms zurückkehren, nachdem Sie es geändert haben. Um das Standard-Batch-Fenster wiederherzustellen, müssen Sie eine neue Ereignisquellenzuordnung erstellen.
-
Die Batch-Größe wird erreicht. Die minimale Batch-Größe beträgt 1. Die Standard- und die maximale Batch-Größe hängen von der Ereignisquelle ab. Weitere Informationen zu diesen Werten finden Sie unter
BatchSize-Spezifikation für dieCreateEventSourceMapping-API-Operation. -
Die Nutzlastgröße erreicht 6 MB. Sie können dieses Limit nicht ändern.
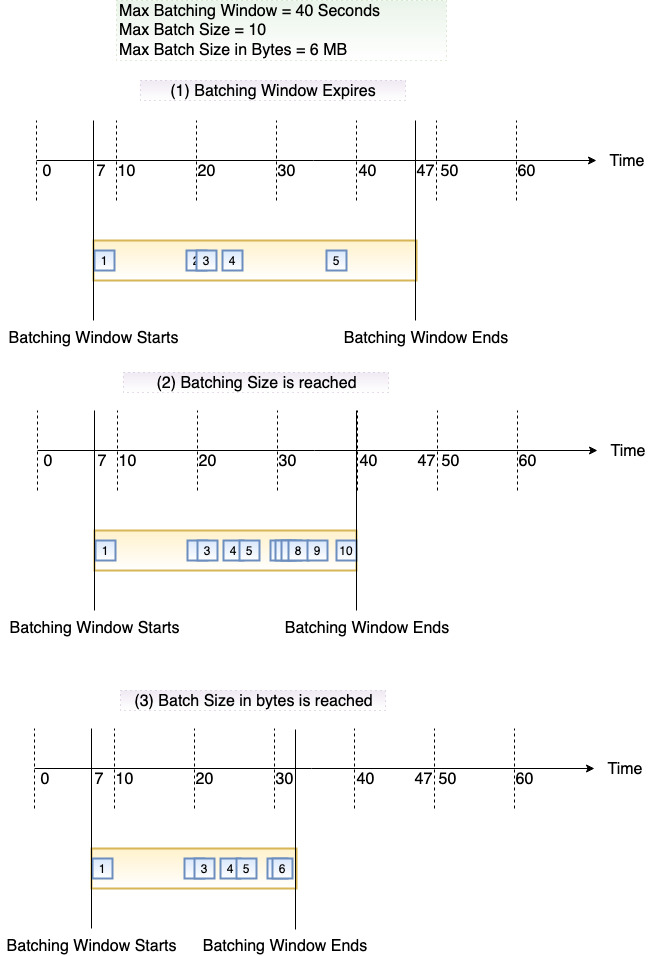
Das folgende Diagramm verdeutlicht diese Bedingungen. Angenommen, ein Batch-Fenster beginnt bei t = 7 Sekunden. Im ersten Szenario erreicht das Batch-Fenster sein Maximum von 40 Sekunden bei t = 47 Sekunden nach dem Erfassen von 5 Datensätzen. Im zweiten Szenario erreicht die Batch-Größe 10, bevor das Batch-Fenster abläuft, sodass das Batch-Fenster früh endet. Im dritten Szenario wird die maximale Nutzlastgröße erreicht, bevor das Batch-Fenster abläuft, sodass das Batch-Fenster frühzeitig endet.
Das folgende Beispiel zeigt eine Ereignisquellen-Zuweisung, die aus einem Kinesis-Stream liest. Wenn bei einem Batch von Ereignissen alle Verarbeitungsversuche fehlschlagen, sendet die Ereignisquellen-Zuweisung-Details über den Batch an eine SQS-Warteschlange.

Der Ereignisbatch ist das Ereignis, das Lambda an die Funktion sendet. Es handelt sich um einen Batch von Datensätzen oder Nachrichten, die aus den Elementen kompiliert werden, die von der Ereignisquellenzuordnung bis zum Ablauf des aktuellen Batch-Fensters gelesen werden.
Bei Kinesis- und DynamoDB-Streams erstellt eine Zuordnung von Ereignisquellen einen Iterator für jeden Shard im Stream und verarbeitet die Elemente in jedem Shard der Reihe nach. Sie können die Ereignisquellen-Zuweisung so konfigurieren, dass sie nur die neuen Elemente liest, die im Stream erscheinen, oder dass sie bei älteren Elementen beginnt. Verarbeitete Elemente werden nicht aus dem Stream entfernt und können von anderen Funktionen oder Konsumenten verarbeitet werden.
Lambda wartet mit dem Senden des nächsten zu verarbeitenden Stapels nicht, bis ggf. konfigurierte Lambda-Erweiterungen abgeschlossen sind. Anders ausgedrückt: Ihre Erweiterungen werden möglicherweise weiter ausgeführt, während Lambda den nächsten Stapel von Datensätzen verarbeitet. Dies kann zu Drosselungsproblemen führen, wenn Sie gegen eine Einstellung oder gegen einen Grenzwert im Zusammenhang mit der Parallelität Ihres Kontos verstoßen. Um zu erkennen, ob möglicherweise ein Problem vorliegt, müssen Sie Ihre Funktionen überwachen sowie überprüfen, ob für Ihre Zuordnung von Ereignisquellen unerwartet hohe Parallelitätsmetriken vorliegen. Aufgrund der kurzen Zeit zwischen den Aufrufen kann Lambda kurzzeitig eine höhere Gleichzeitigkeitsnutzung als die Anzahl der Shards melden. Dies kann sogar für Lambda-Funktionen ohne Erweiterungen gelten.
Wenn Ihre Funktion einen Fehler zurückgibt, verarbeitet die Ereignisquellenzuordnung standardmäßig das gesamte Batch erneut, bis die Funktion erfolgreich ist oder die Elemente im Batch ablaufen. Um eine ordnungsgemäße Verarbeitung zu gewährleisten, unterbricht die Ereignisquellenzuordnung die Verarbeitung für den betroffenen Shard, bis der Fehler behoben ist. Sie können die Zuordnung von Ereignisquellen so konfigurieren, dass alte Ereignisse verworfen oder mehrere Stapel parallel verarbeitet werden. Wenn Sie mehrere Batches parallel verarbeiten, ist die ordnungsgemäße Verarbeitung für jeden Partitionsschlüssel immer noch gewährleistet, aber die Ereignisquellenzuordnung verarbeitet gleichzeitig mehrere Partitionsschlüssel im selben Shard.
Für Stream-Quellen (DynamoDB und Kinesis) können Sie die maximale Anzahl von Wiederholungsversuchen von Lambda konfigurieren, wenn Ihre Funktion einen Fehler zurückgibt. Service-Fehler oder Drosselungen, bei denen der Stapel Ihre Funktion nicht erreicht, zählen nicht zu den Wiederholungsversuchen.
Sie können die Ereignisquellen-Zuweisung auch so konfigurieren, dass ein Aufrufdatensatz an einen anderen Service gesendet wird, wenn ein Ereignisbatch verworfen wird. Lambda unterstützt die folgenden Ziele für Ereignisquellen-Zuweisungen.
-
Amazon SQS – Eine SQS-Warteschlange.
-
Amazon SNS – Ein SNS-Thema.
Der Aufrufdatensatz enthält Details zum fehlgeschlagenen Ereignisbatch im JSON-Format.
Das folgende Beispiel zeigt einen Aufrufdatensatz für einen Kinesis-Stream.
Beispiel Aufrufdatensatzglauben
{ "requestContext": { "requestId": "c9b8fa9f-5a7f-xmpl-af9c-0c604cde93a5", "functionArn": "arn:aws:lambda:us-east-2:123456789012:function:myfunction", "condition": "RetryAttemptsExhausted", "approximateInvokeCount": 1 }, "responseContext": { "statusCode": 200, "executedVersion": "$LATEST", "functionError": "Unhandled" }, "version": "1.0", "timestamp": "2019-11-14T00:38:06.021Z", "KinesisBatchInfo": { "shardId": "shardId-000000000001", "startSequenceNumber": "49601189658422359378836298521827638475320189012309704722", "endSequenceNumber": "49601189658422359378836298522902373528957594348623495186", "approximateArrivalOfFirstRecord": "2019-11-14T00:38:04.835Z", "approximateArrivalOfLastRecord": "2019-11-14T00:38:05.580Z", "batchSize": 500, "streamArn": "arn:aws:kinesis:us-east-2:123456789012:stream/mystream" } }
Lambda unterstützt auch die Verarbeitung in der Reihenfolge für FIFO-Warteschlangen (First-In, First-Out), die auf die Anzahl der aktiven Nachrichtengruppen skaliert wird. Bei Standard-Warteschlangen werden Elemente nicht unbedingt der Reihe nach verarbeitet. Lambda skaliert hoch, um eine Standardwarteschlange so schnell wie möglich zu verarbeiten. Wenn ein Fehler auftritt, sendet Lambda Batches als einzelne Elemente an die Warteschlange zurück und verarbeitet sie möglicherweise in einer anderen Gruppierung als im ursprünglichen Batch. Gelegentlich kann es vorkommen, dass die Ereignisquellen-Zuweisung dasselbe Element aus der Warteschlange zweimal erhält, auch wenn kein Funktionsfehler aufgetreten ist. Lambda löscht Elemente aus der Warteschlange, nachdem sie erfolgreich verarbeitet wurden. Sie können die Quellenwarteschlange so konfigurieren, dass Elemente an eine Warteschlange für unzustellbare Nachrichten oder ein Ziel gesendet werden, wenn Lambda sie nicht verarbeiten kann.
Weitere Informationen zu Services, die Lambda-Funktionen direkt aufrufen, finden Sie unter Verwenden von AWS Lambda mit anderen -Services.
Konfigurieren von Zielen für Aufrufe zur Zuordnung von Ereignisquellen
Um Datensätze zu fehlgeschlagenen Aufrufen zur Zuordnung von Ereignisquellen beizubehalten, fügen Sie der Zuordnung von Ereignisquellen Ihrer Funktion ein Ziel hinzu. Die Konfiguration von Zielen für Aufrufe zur Zuordnung von Ereignisquellen wird nur für Kinesis-, DynamoDB- und Kafka-basierte Ereignisquellen unterstützt. Jeder Datensatz, der an das Ziel gesendet wird, ist ein JSON-Dokument mit Details zum Aufruf. Wie Einstellungen zur Fehlerbehandlung können Sie Ziele für eine Funktion, eine Funktionsversion oder einen Alias konfigurieren.
Anmerkung
Bei Aufrufen zur Zuordnung von Ereignisquellen können Sie nur Datensätze für fehlgeschlagene Aufrufe beibehalten. Bei anderen asynchronen Aufrufen können Sie Datensätze sowohl für erfolgreiche als auch für fehlgeschlagene Aufrufe speichern. Weitere Informationen finden Sie unter Konfigurieren von Zielen für den asynchronen Aufruf.
Sie können jedes Amazon-SNS-Thema oder jede Amazon-SQS-Warteschlange als Ziel konfigurieren. Für diese Zieltypen sendet Lambda die Datensatzmetadaten an das Ziel. Nur für Kafka-basierte Ereignisquellen können Sie auch einen Amazon-S3-Bucket als Ziel wählen. Wenn Sie einen S3-Bucket angeben, sendet Lambda den gesamten Aufrufdatensatz zusammen mit den Metadaten an das Ziel.
In der folgenden Tabelle finden Sie eine Zusammenfassung der Arten der unterstützten Ziele für Aufrufe zur Zuordnung von Ereignisquellen. Damit Lambda erfolgreich Datensätze an das von Ihnen ausgewählte Ziel senden kann, stellen Sie sicher, dass die Ausführungsrolle Ihrer Funktion auch die entsprechenden Berechtigungen enthält. In der Tabelle wird auch beschrieben, wie jeder Zieltyp den JSON-Aufrufdatensatz empfängt.
| Zieltyp | Unterstützt für die folgenden Ereignisquellen | Erforderliche Berechtigungen | Zielspezifisches JSON-Format |
|---|---|---|---|
|
Amazon-SQS-Warteschlange |
|
Lambda übergibt die Aufrufdatensatz-Metadaten als |
|
|
Amazon SNS-Thema |
|
Lambda übergibt die Aufrufdatensatz-Metadaten als |
|
|
Amazon S3-Bucket |
|
Lambda speichert den Aufrufdatensatz zusammen mit den zugehörigen Metadaten am Ziel. |
Das folgende Beispiel zeigt, was Lambda bei einem fehlgeschlagenen Aufruf der Kinesis-Ereignisquelle an eine SQS-Warteschlange oder ein SNS-Thema sendet. Da Lambda nur die Metadaten für diese Zieltypen sendet, verwenden Sie die Felder streamArn, shardId, startSequenceNumber und endSequenceNumber, um den vollständigen Originaldatensatz abzurufen.
{ "requestContext": { "requestId": "c9b8fa9f-5a7f-xmpl-af9c-0c604cde93a5", "functionArn": "arn:aws:lambda:us-east-2:123456789012:function:myfunction", "condition": "RetryAttemptsExhausted", "approximateInvokeCount": 1 }, "responseContext": { "statusCode": 200, "executedVersion": "$LATEST", "functionError": "Unhandled" }, "version": "1.0", "timestamp": "2019-11-14T00:38:06.021Z", "KinesisBatchInfo": { "shardId": "shardId-000000000001", "startSequenceNumber": "49601189658422359378836298521827638475320189012309704722", "endSequenceNumber": "49601189658422359378836298522902373528957594348623495186", "approximateArrivalOfFirstRecord": "2019-11-14T00:38:04.835Z", "approximateArrivalOfLastRecord": "2019-11-14T00:38:05.580Z", "batchSize": 500, "streamArn": "arn:aws:kinesis:us-east-2:123456789012:stream/mystream" } }
Ein Beispiel für DynamoDB-Ereignisquellen finden Sie unter Fehlerbehandlung. Ein Beispiel für Kafka-Ereignisquellen finden Sie unter Ausfallziele für selbstverwaltetes Apache Kafka oder Ausfallziele für Amazon MSK.
