Wir aktualisieren den Amazon Machine Learning Learning-Service nicht mehr und akzeptieren auch keine neuen Benutzer mehr dafür. Diese Dokumentation ist für bestehende Benutzer verfügbar, wir aktualisieren sie jedoch nicht mehr. Weitere Informationen finden Sie unter Was ist Amazon Machine Learning.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Aufteilen Ihrer Daten
Das wesentliche Ziel eines ML-Modells ist es, genaue Voraussagen über zukünftige Daten-Instances über die Schulungsmodelle hinaus zu erreichen. Bevor Sie ein ML-Modell verwenden, um Voraussagen zu erstellen, müssen Sie die Leistung der Voraussagen des Modells bewerten. Zur Einschätzung der Qualität eines ML-Modells für Voraussagen mit Daten, die es noch nicht gesehen hat, können wir einen Teil der Daten, für die wir bereits die Antwort kennen, als Vertreter für zukünftige Daten reservieren oder aufteilen und auswerten, wie gut das ML-Modell die richtigen Antworten für diese Daten antizipiert. Teilen Sie die Datenquelle in einen Teil als Schulungsdatenquelle und einen Teil als Auswertungsdatenquelle auf.
Amazon ML bietet drei Optionen für die Aufteilung Ihrer Daten:
-
Daten vorab aufteilen — Sie können die Daten in zwei Dateneingabeorte aufteilen, bevor Sie sie auf Amazon Simple Storage Service (Amazon S3) hochladen und damit zwei separate Datenquellen erstellen.
-
Sequentielles Aufteilen von Amazon ML — Sie können Amazon ML anweisen, Ihre Daten sequentiell aufzuteilen, wenn Sie die Trainings- und Bewertungsdatenquellen erstellen.
-
Amazon ML Random Split — Sie können Amazon ML anweisen, Ihre Daten mithilfe einer voreingestellten Zufallsmethode aufzuteilen, wenn Sie die Trainings- und Bewertungsdatenquellen erstellen.
Vorabtrennung Ihrer Daten
Wenn Sie explizite Kontrolle über die Daten in den Schulungs- und Auswertungsdatenquellen wünschen, teilen Sie die Daten in separate Datenverzeichnisse auf und erstellen Sie separate Datenquellen für die Eingabe- und Auswertungsverzeichnisse.
Sequenzielle Aufteilung Ihrer Daten
Eine einfache Möglichkeit, Ihre Eingabedaten für Schulung und Auswertung aufzuteilen, ist die Auswahl nicht überlappender Teilmengen Ihrer Daten, wobei die Reihenfolge der Datensätze beibehalten wird. Dieser Ansatz ist nützlich, wenn Sie Ihre ML-Modelle mit Daten von einem bestimmten Datum oder innerhalb eines bestimmten Zeitraums auswerten möchten. Angenommen, Sie haben die Kundenbindungsdaten der letzten fünf Monate, und Sie möchten diese historischen Daten nutzen, um die Kundenbindung für den nächsten Monat vorauszusagen. Mit der Nutzung der Daten aus dem Anfangsbereich für die Schulung und der Daten aus dem Endbereich für die Auswertung erhalten Sie wahrscheinlich eine genauere Einschätzung der Modellqualität als bei Verwendung von Datensätzen aus dem gesamten Datumsbereich.
In der folgenden Abbildung finden Sie Beispiele dafür, wann Sie eine sequenzielle Aufteilungsstrategie statt einer Zufallsmethode verwenden sollten.

Wenn Sie eine Datenquelle erstellen, können Sie wählen, ob Sie Ihre Datenquelle sequentiell aufteilen möchten. Amazon ML verwendet die ersten 70 Prozent Ihrer Daten für das Training und die restlichen 30 Prozent der Daten für die Auswertung. Dies ist der Standardansatz, wenn Sie die Amazon ML-Konsole verwenden, um Ihre Daten aufzuteilen.
Zufällige Aufteilung Ihrer Daten
Zufälliges Aufteilen der Eingabedaten in Schulungs- und Auswertungsdatenquellen stellt sicher, dass die Verteilung von Daten in der Schulungs- und Auswertungsdatenquelle ähnlich ist. Wählen Sie diese Option, wenn Sie die Reihenfolge der Eingabedaten nicht beibehalten müssen.
Amazon ML verwendet eine vordefinierte Methode zur Generierung von Pseudozufallszahlen, um Ihre Daten aufzuteilen. Der Seed-Startwert basiert teilweise auf einer Eingabezeichenfolge und teilweise auf dem Inhalt der Daten. Standardmäßig verwendet die Amazon ML-Konsole den S3-Speicherort der Eingabedaten als Zeichenfolge. API-Benutzer können eine benutzerdefinierte Zeichenfolge festlegen. Das bedeutet, dass Amazon ML bei demselben S3-Bucket und denselben Daten die Daten jedes Mal auf dieselbe Weise aufteilt. Um zu ändern, wie Amazon ML die Daten aufteilt, können Sie die CreateDatasourceFromRDS API CreateDatasourceFromS3CreateDatasourceFromRedshift, oder verwenden und einen Wert für die Startzeichenfolge angeben. Wenn Sie diese verwenden, APIs um separate Datenquellen für Training und Evaluierung zu erstellen, ist es wichtig, denselben Start-String-Wert für beide Datenquellen und das Komplement-Flag für eine Datenquelle zu verwenden, um sicherzustellen, dass es keine Überschneidungen zwischen den Trainings- und Bewertungsdaten gibt.
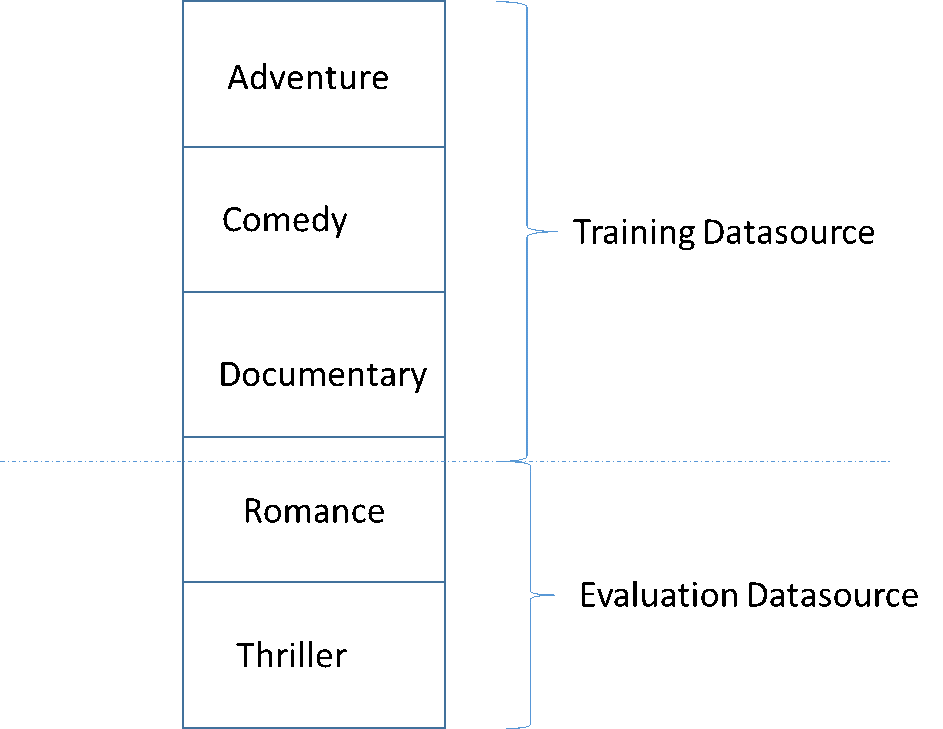
Ein häufiges Problem bei der Entwicklung eines hochwertigen ML-Modells ist die Auswertung der ML-Modells mit Daten, die nicht den Daten für die Schulung entsprechen. Angenommen, Sie verwenden ML, um ein Filmgenre vorauszusagen, und Ihre Schulungsdaten enthalten Filme aus den Segmenten Abenteuer, Komödie und Dokumentation. Ihre Auswertungsdaten enthalten jedoch nur Daten aus dem Genre Liebesfilm und Thriller. In diesem Fall konnte das ML-Modell keine Informationen über die Filmgenre Liebesfilm und Thriller lernen, und die Auswertung konnte nicht feststellen, wie gut das Modell die Muster für Abenteuer, Komödie und Dokumentation gelernt hat. Demzufolge sind die Genre-Informationen nutzlos, und die Qualität der ML-Modellvoraussagen für alle Genres ist beeinträchtigt. Das Modell und die Auswertung sind zu unterschiedlich (extrem unterschiedliche beschreibende Statistiken), als dass sie nützlich wären. Dies kann der Fall sein, wenn die Eingabedaten nach einer der Spalten im Datensatz sortiert werden und dann sequenziell aufgeteilt werden.
Wenn Ihre Schulungs- und Auswertungsdatenquellen unterschiedliche Datenverteilungen haben, sehen Sie eine Auswertungswarnung in der Modellauswertung. Weitere Informationen zu Auswertungswarnungen finden Sie unter Auswertungswarnungen.
Sie müssen die zufällige Aufteilung in Amazon ML nicht verwenden, wenn Sie Ihre Eingabedaten bereits randomisiert haben, z. B. durch zufälliges Mischen Ihrer Eingabedaten in Amazon S3 oder durch die Verwendung einer Amazon Redshift Redshift-SQL-Abfrage oder einer random() MySQL-SQL-Abfragefunktion bei der Erstellung der rand() Datenquellen. In diesen Fällen können Sie die sequenzielle Aufteilungsoption zum Erstellen von Schulungs- und Auswertungsdatenquellen mit ähnlichen Verteilungen verwenden.
