Amazon Managed Service for Apache Flink (Amazon MSF) war zuvor als Amazon Kinesis Data Analytics for Apache Flink bekannt.
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Checkpoints
Checkpoints sind der Mechanismus von Flink, der sicherstellt, dass der Zustand einer Anwendung fehlertolerant ist. Dieser Mechanismus ermöglicht es Flink, den Status der Operatoren wiederherzustellen, falls der Auftrag fehlschlägt, und verleiht der Anwendung dieselbe Semantik wie bei einer fehlerfreien Ausführung. Mit Managed Service für Apache Flink wird der Zustand einer Anwendung in RocksDB gespeichert, einem eingebetteten Schlüssel-Wert-Speicher, der seinen Betriebszustand auf der Festplatte speichert. Wenn ein Checkpoint erreicht wird, wird der Zustand auch auf Amazon S3 hochgeladen. Selbst wenn die Festplatte verloren geht, kann der Checkpoint verwendet werden, um den Zustand der Anwendung wiederherzustellen.
Weitere Informationen finden Sie unter Wie funktionieren Zustand-Snapshots?
Checkpointing-Phasen
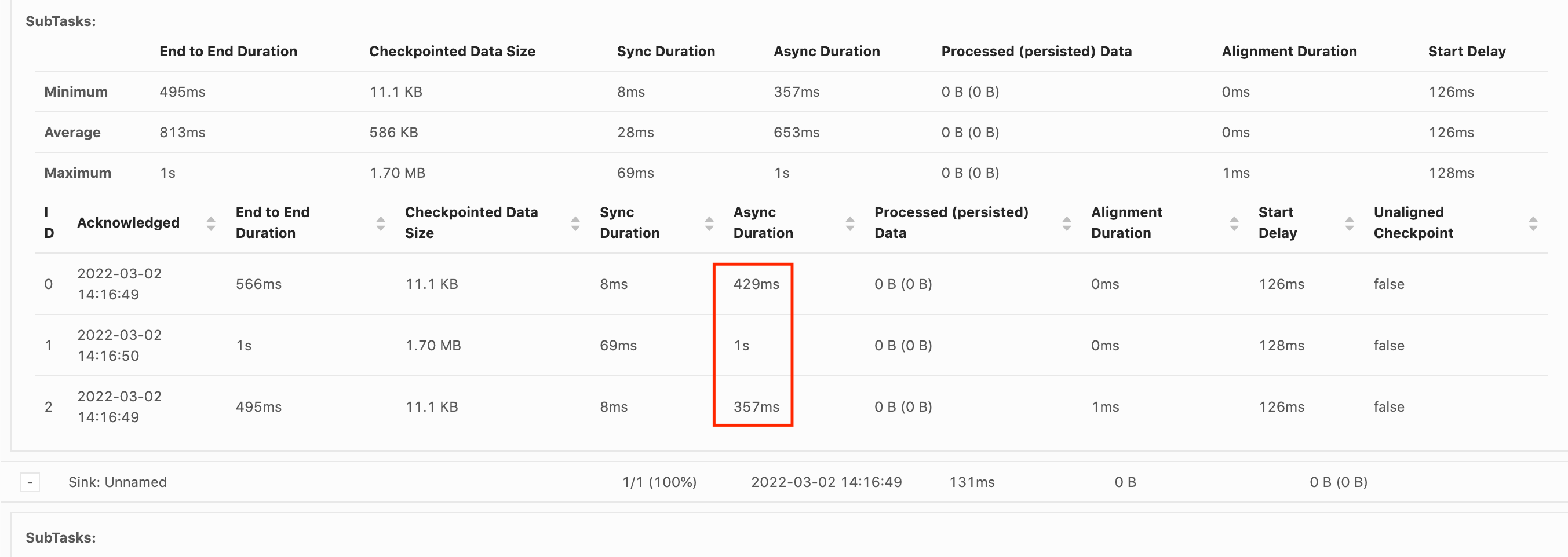
Für eine Checkpointing-Operator-Unteraufgabe in Flink gibt es 5 Hauptphasen:
Warten [Startverzögerung] – Flink verwendet Checkpoint-Barrieren, die in den Stream eingefügt werden. Die Zeit in dieser Phase ist also die Zeit, in der der Operator darauf wartet, dass die Checkpoint-Barriere sie erreicht.
Ausrichtung [Ausrichtungsdauer] – In dieser Phase hat die Unteraufgabe eine Barriere erreicht, wartet aber auf Barrieren aus anderen Eingabeströmen.
Sync-Checkpointing [Sync-Dauer] – In dieser Phase nimmt die Unteraufgabe tatsächlich einen Snapshot des Zustands des Operators auf und blockiert alle anderen Aktivitäten in der Unteraufgabe.
Async-Checkpointing [Async-Dauer] – Der Großteil dieser Phase besteht aus der Unteraufgabe, den Zustand auf Amazon S3 hochzuladen. Während dieser Phase ist die Unteraufgabe nicht mehr blockiert und kann Datensätze verarbeiten.
Bestätigung — In der Regel handelt es sich dabei um eine kurze Phase. Dabei handelt es sich einfach um die Unteraufgabe, die eine Bestätigung an den Server sendet JobManager und auch alle Commit-Nachrichten ausführt (z. B. bei Kafka-Senken).
Jede dieser Phasen (außer Bestätigung) ist einer Dauermetrik für Checkpoints zugeordnet, die über die Flink-WebUI verfügbar ist und die dazu beitragen kann, die Ursache für den langen Checkpoint zu isolieren.
Eine genaue Definition der einzelnen für Checkpoints verfügbaren Metriken finden Sie auf der Registerkarte Verlauf
Untersuchen
Bei der Untersuchung einer langen Checkpoint-Dauer ist es am wichtigsten, den Engpass für den Checkpoint zu ermitteln, d. h. welcher Operator und welche Unteraufgabe am längsten bis zum Checkpoint benötigt und welche Phase dieser Unteraufgabe länger dauert. Dies kann mithilfe der Flink-WebUI unter der Aufgabe Aufträge Checkpoint ermittelt werden. Die Weboberfläche von Flink bietet Daten und Informationen, die bei der Untersuchung von Checkpoint-Problemen helfen. Eine vollständige Aufschlüsselung finden Sie unter Überwachen des Checkpointing
Als Erstes sollten Sie sich die Gesamtdauer jedes Operators im Auftragsdiagramm ansehen, um festzustellen, welcher Operator lange braucht, um den Checkpoint zu erreichen, und wo weitere Untersuchungen erforderlich sind. Gemäß der Flink-Dokumentation lautet die Definition der Dauer wie folgt:
Die Dauer vom Trigger-Zeitstempel bis zur letzten Bestätigung (oder n/a, wenn noch keine Bestätigung eingegangen ist). Diese Gesamtdauer für einen vollständigen Checkpoint wird durch die letzte Unteraufgabe bestimmt, die den Checkpoint bestätigt. Diese Zeit ist normalerweise länger, als einzelne Teilaufgaben benötigen, um tatsächlich einen Checkpoint des Zustands zu erstellen.
Die anderen Zeitdauerangaben für den Checkpoint geben auch detailliertere Informationen darüber, wo die Zeit verbracht wird.
Wenn die Sync-Dauer hoch ist, deutet dies darauf hin, dass während der Snapshot-Erstellung etwas passiert. In dieser Phase wird snapshotState() für Klassen aufgerufen, die die SnapshotState-Schnittstelle implementieren. Dabei kann es sich um Benutzercode handeln, sodass Thread-Dumps nützlich sein können, um dies zu untersuchen.
Eine lange Async-Dauer würde darauf hindeuten, dass viel Zeit für das Hochladen des Zustands auf Amazon S3 aufgewendet wird. Dies kann der Fall sein, wenn der Zustand groß ist oder wenn viele Zustandsdateien hochgeladen werden. Wenn dies der Fall ist, lohnt es sich zu untersuchen, wie der Zustand von der Anwendung verwendet wird, und sicherzustellen, dass die systemeigenen Flink-Datenstrukturen verwendet werden, wo immer dies möglich ist (Gekennzeichneten Zustand verwenden
Eine hohe Startverzögerung würde bedeuten, dass die meiste Zeit damit verbracht wird, darauf zu warten, dass die Checkpoint-Barriere den Operator erreicht. Dies deutet darauf hin, dass die Anwendung eine Weile benötigt, um Datensätze zu verarbeiten, was bedeutet, dass die Barriere langsam durch das Auftragsdiagramm fließt. Dies ist normalerweise der Fall, wenn der Auftrag Gegendruck erhält oder wenn ein oder mehrere Operatoren ständig beschäftigt sind. Es folgt ein Beispiel für eine, JobGraph bei der der zweite Operator beschäftigt ist. KeyedProcess
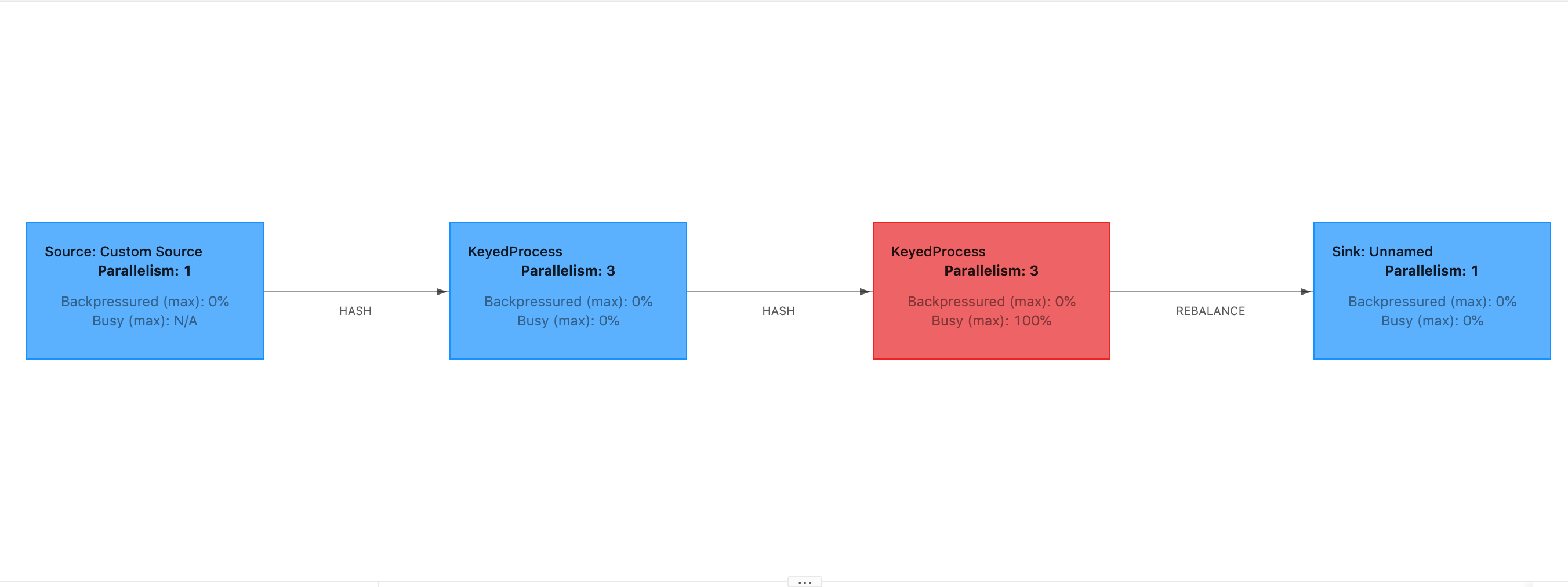
Sie können untersuchen, was so lange dauert, indem Sie entweder Flink Flame Graphs oder TaskManager Thread-Dumps verwenden. Sobald der Engpass identifiziert wurde, kann er mithilfe von Flame-Diagrammen oder Thread-Dumps weiter untersucht werden.
Thread-Dumps
Thread-Dumps sind ein weiteres Debugging-Tool auf einer etwas niedrigeren Ebene als Flame-Diagramme. Ein Thread-Dump gibt den Ausführungszustand aller Threads zu einem bestimmten Zeitpunkt aus. Flink nimmt einen JVM-Thread-Dump, der den Ausführungszustand aller Threads innerhalb des Flink-Prozesses darstellt. Der Zustand eines Threads wird durch einen Stack-Trace des Threads sowie durch einige zusätzliche Informationen dargestellt. Flame-Diagramme werden tatsächlich aus mehreren Stack-Traces erstellt, die schnell hintereinander aufgenommen wurden. Das Diagramm ist eine aus diesen Traces erstellte Visualisierung, die es einfach macht, die gemeinsamen Codepfade zu identifizieren.
"KeyedProcess (1/3)#0" prio=5 Id=1423 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:154) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>>19) at $line33.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Oben sehen Sie einen Ausschnitt eines Thread-Dumps aus der Flink-Benutzeroberfläche für einen einzelnen Thread. Die erste Zeile enthält einige allgemeine Informationen zu diesem Thread, darunter:
Der Thread-Name KeyedProcess (1/3) #0
Priorität des Threads prio=5
Eine eindeutige Thread-ID Id=1423
Thread-Status RUNNABLE
Der Name eines Threads gibt normalerweise Auskunft über den allgemeinen Zweck des Threads. Operator-Threads können anhand ihres Namens identifiziert werden, da Operator-Threads denselben Namen wie der Operator haben und außerdem angeben, zu welcher Unteraufgabe sie gehören, z. B. ist der Thread KeyedProcess (1/3) #0 vom KeyedProcessOperator und von der ersten (von 3) Unteraufgabe.
Threads können sich in einem von wenigen Zuständen befinden:
NEW – Der Thread wurde erstellt, aber noch nicht verarbeitet
RUNNABLE – Der Thread wird auf der CPU ausgeführt
BLOCKED – Der Thread wartet darauf, dass ein anderer Thread seine Sperre freigibt
WAITING – Der Thread wartet mit einer
wait()-,join()-, oderpark()-MethodeTIMED_WAITING – Der Thread wartet mit einer Sleep-, Wait-, Join- oder Park-Methode, jedoch mit einer maximalen Wartezeit.
Anmerkung
In Flink 1.13 ist die maximale Tiefe eines einzelnen Stack-Trace im Thread-Dump auf 8 begrenzt.
Anmerkung
Thread-Dumps sollten das letzte Mittel zum Debuggen von Leistungsproblemen in einer Flink-Anwendung sein, da sie schwierig zu lesen sein können und die Entnahme mehrerer Stichproben und deren manuelle Analyse erfordern. Wenn möglich, ist es vorzuziehen, Flame-Diagramme zu verwenden.
Thread-Dumps in Flink
In Flink kann ein Thread-Dump erstellt werden, indem Sie in der linken Navigationsleiste der Flink-Benutzeroberfläche die Option Aufgabenmanager auswählen, einen bestimmten Aufgabenmanager auswählen und dann zur Registerkarte Thread-Dump navigieren. Der Thread-Dump kann heruntergeladen, in Ihren bevorzugten Texteditor (oder Thread-Dump-Analysator) kopiert oder direkt in der Textansicht in der Flink-Web-UI analysiert werden (diese letzte Option kann jedoch etwas umständlich sein).
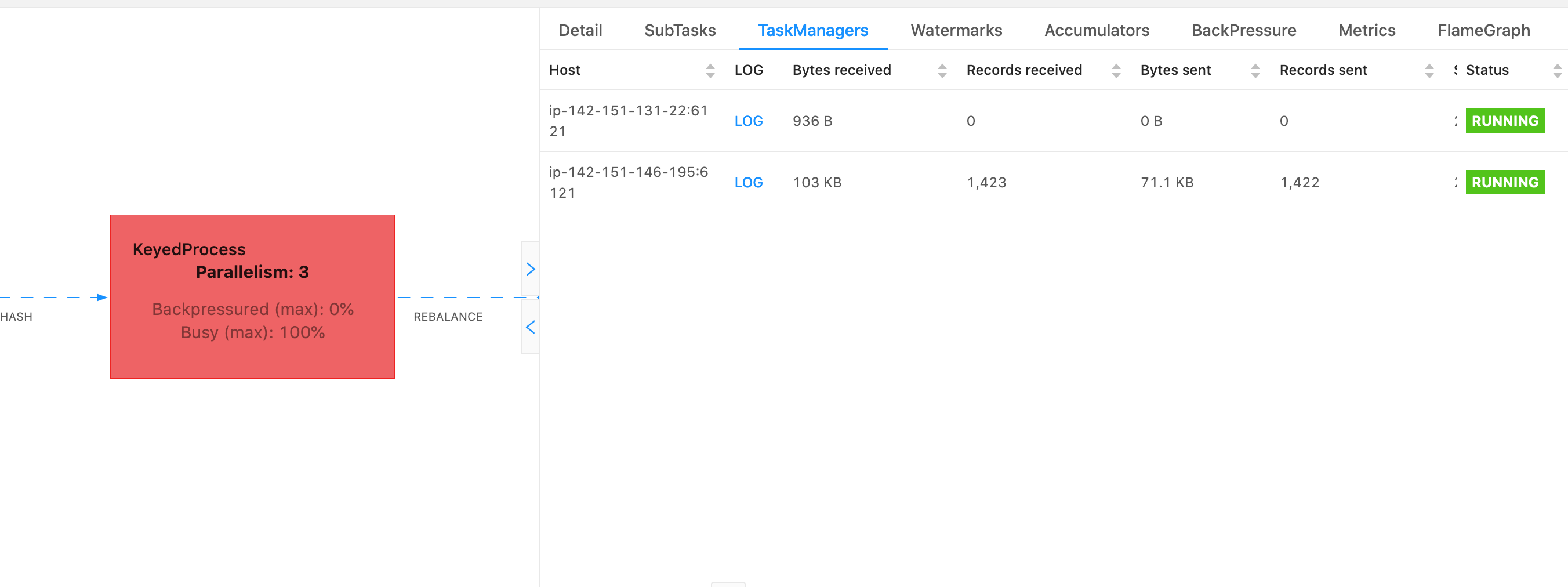
Um zu bestimmen, welcher Task Manager verwendet werden soll, kann ein Thread-Dump des TaskManagersTabs verwendet werden, wenn ein bestimmter Operator ausgewählt wird. Dies zeigt, dass der Operator für verschiedene Unteraufgaben eines Operators ausgeführt wird und auf verschiedenen Aufgabenmanagern ausgeführt werden kann.
Der Dump wird aus mehreren Stack-Traces bestehen. Bei der Untersuchung des Dumps sind jedoch diejenigen am wichtigsten, die sich auf einen Operator beziehen. Diese können leicht gefunden werden, da Operator-Threads denselben Namen wie der Operator haben und auch angeben, auf welche Unteraufgabe sie sich beziehen. Zum Beispiel stammt der folgende Stack-Trace vom KeyedProcessOperator und ist die erste Unteraufgabe.
"KeyedProcess (1/3)#0" prio=5 Id=595 RUNNABLE at app//scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:155) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:19) at $line360.$read$$iw$$iw$ExpensiveFunction.processElement(<console>:14) at app//org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:83) at app//org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:205) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.processElement(AbstractStreamTaskNetworkInput.java:134) at app//org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:105) at app//org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66) ...
Dies kann verwirrend werden, wenn es mehrere Operatoren mit demselben Namen gibt, aber wir können Operatoren benennen, um dies zu umgehen. Beispiel:
.... .process(new ExpensiveFunction).name("Expensive function")
Flame-Diagramme
Flame-Diagramme sind ein nützliches Debugging-Tool, das die Stack-Traces des Zielcodes visualisiert und so die Identifizierung der häufigsten Codepfade ermöglicht. Sie werden erstellt, indem Stack-Traces mehrmals abgetastet werden. Die X-Achse eines Flame-Diagramms zeigt die verschiedenen Stack-Profile, während die Y-Achse die Stack-Tiefe und die Aufrufe des Stack-Trace zeigt. Ein einzelnes Rechteck in einem Flame-Diagramm steht für einen Stack-Frame, und die Breite eines Frames gibt an, wie häufig es in den Stacks vorkommt. Weitere Informationen über Flame-Diagramme und deren Nutzung finden Sie unter Flame-Diagramme
In Flink kann das Flame-Diagramm für einen Operator über die Weboberfläche aufgerufen werden, indem Sie einen Operator und dann die FlameGraphRegisterkarte auswählen. Sobald genügend Proben gesammelt wurden, wird das Flame-Diagramm angezeigt. Im Folgenden finden Sie das FlameGraph für den ProcessFunction , dessen Checkpoint viel Zeit in Anspruch genommen hat.
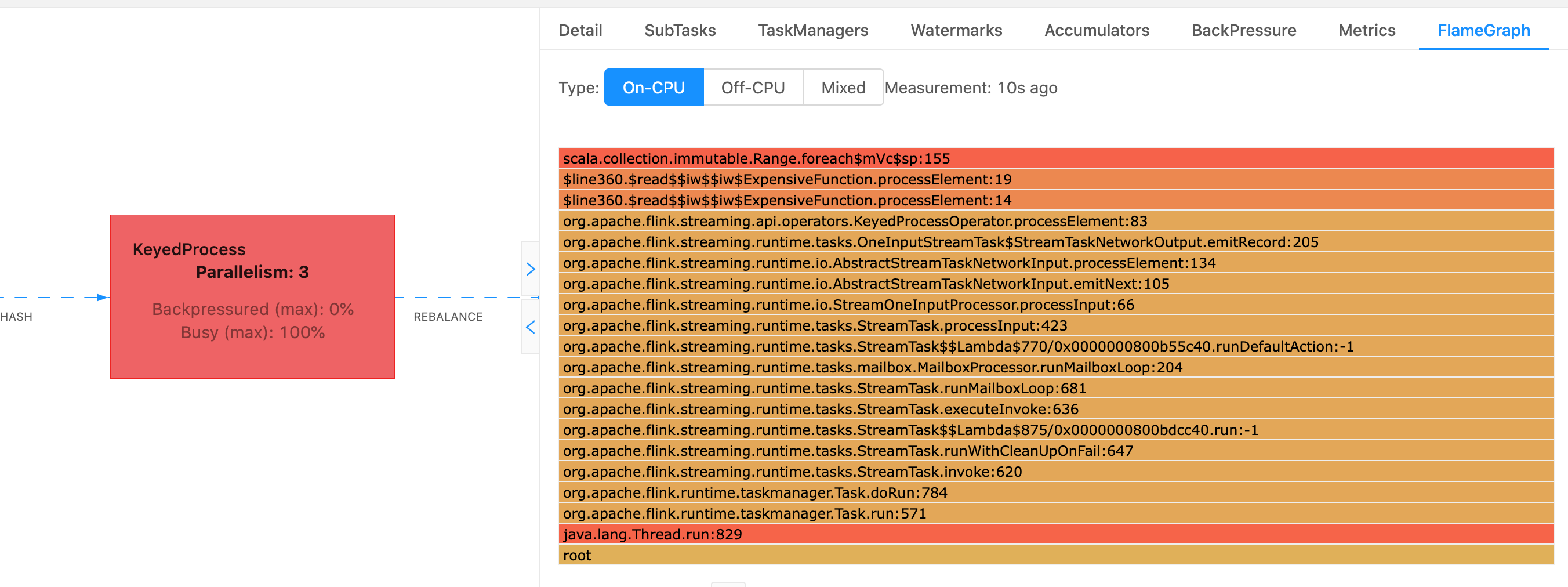
Dies ist ein sehr einfaches Flammendiagramm, das zeigt, dass die gesamte CPU-Zeit für einen Blick innerhalb processElement des ExpensiveFunction Bedieners aufgewendet wird. Sie erhalten auch die Zeilennummer, anhand derer Sie feststellen können, wo die Codeausführung stattfindet.
