Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Anwendungsfälle
Im Folgenden finden Sie Anwendungsfälle der Vektorsuche.
Retrieval Augmented Generation (RAG)
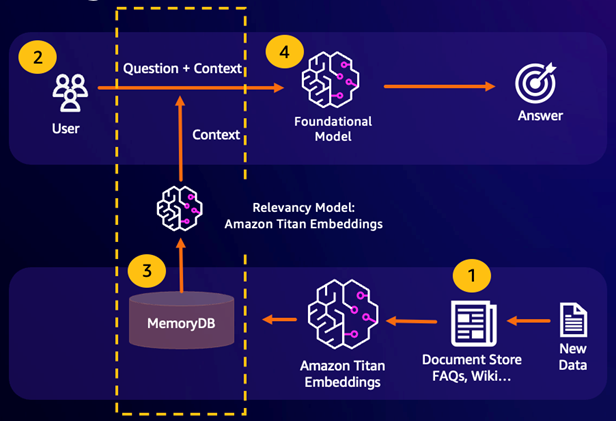
Retrieval Augmented Generation (RAG) nutzt die Vektorsuche, um relevante Passagen aus einem großen Datenkorpus abzurufen und so ein großes Sprachmodell (LLM) zu erweitern. Konkret bettet ein Encoder den Eingabekontext und die Suchanfrage in Vektoren ein und verwendet dann die ungefähre Suche nach dem nächsten Nachbarn, um semantisch ähnliche Passagen zu finden. Diese abgerufenen Passagen werden mit dem ursprünglichen Kontext verkettet, um dem LLM zusätzliche relevante Informationen zur Verfügung zu stellen, damit der Benutzer eine genauere Antwort erhält.
Dauerhafter semantischer Cache
Semantisches Caching ist ein Prozess zur Reduzierung der Rechenkosten durch das Speichern früherer Ergebnisse aus dem FM. Durch die Wiederverwendung früherer Ergebnisse aus früheren Inferenzen, anstatt sie neu zu berechnen, reduziert das semantische Caching den Rechenaufwand bei der Inferenz durch. FMs MemoryDB ermöglicht dauerhaftes semantisches Caching, wodurch der Datenverlust Ihrer früheren Schlussfolgerungen vermieden wird. Auf diese Weise können Ihre generativen KI-Anwendungen innerhalb einstelliger Millisekunden mit Antworten auf frühere semantisch ähnliche Fragen antworten und gleichzeitig die Kosten senken, indem unnötige LLM-Schlussfolgerungen vermieden werden.
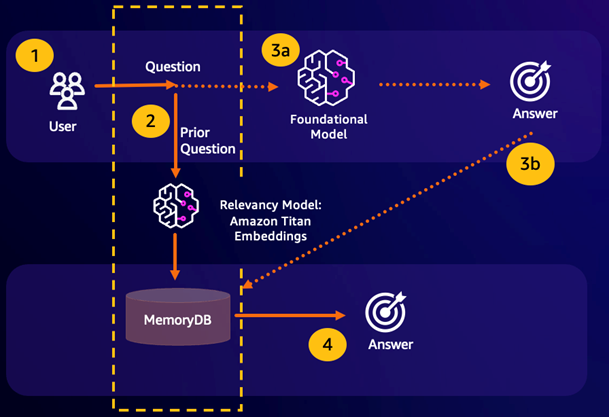
Semantischer Suchtreffer — Wenn die Anfrage eines Kunden aufgrund eines definierten Ähnlichkeitswerts einer vorherigen Frage semantisch ähnlich ist, gibt der FM-Pufferspeicher (MemoryDB) die Antwort auf die vorherige Frage in Schritt 4 zurück und ruft das FM nicht in Schritt 3 auf. Dadurch werden die Latenz und die damit verbundenen Kosten des Foundation Model (FM) vermieden und der Kunde erhält ein schnelleres Erlebnis.
Fehlende semantische Suche — Wenn die Anfrage eines Kunden aufgrund eines definierten Ähnlichkeitswerts einer vorherigen Anfrage semantisch nicht ähnlich ist, ruft ein Kunde den FM an, um dem Kunden in Schritt 3a eine Antwort zu senden. Die vom FM generierte Antwort wird dann als Vektor in MemoryDB für future Abfragen gespeichert (Schritt 3b), um die FM-Kosten für semantisch ähnliche Fragen zu minimieren. In diesem Ablauf würde Schritt 4 nicht aufgerufen werden, da es für die ursprüngliche Abfrage keine semantisch ähnliche Frage gab.
Betrugserkennung
Die Betrugserkennung, eine Form der Anomalieerkennung, stellt gültige Transaktionen als Vektoren dar und vergleicht gleichzeitig die Vektordarstellungen neuer Nettotransaktionen. Betrug wird aufgedeckt, wenn diese Netto-Neutransaktionen nur eine geringe Ähnlichkeit mit den Vektoren aufweisen, die die gültigen Transaktionsdaten darstellen. Auf diese Weise kann Betrug aufgedeckt werden, indem normales Verhalten modelliert wird, anstatt zu versuchen, jeden möglichen Betrugsfall vorherzusagen. MemoryDB ermöglicht es Unternehmen, dies in Zeiten mit hohem Durchsatz zu tun, mit minimalen Fehlalarmen und Latenz im einstelligen Millisekundenbereich.

Andere Anwendungsfälle
Empfehlungsmaschinen können Benutzer nach ähnlichen Produkten oder Inhalten suchen, indem sie Artikel als Vektoren darstellen. Die Vektoren werden durch die Analyse von Attributen und Mustern erstellt. Auf der Grundlage von Benutzermustern und -attributen können Benutzern neue unsichtbare Objekte empfohlen werden, indem die ähnlichsten Vektoren gefunden werden, die bereits positiv bewertet wurden und auf den Benutzer abgestimmt sind.
Dokumentensuchmaschinen stellen Textdokumente als dichte Zahlenvektoren dar und erfassen so semantische Bedeutungen. Bei der Suche wandelt die Suchmaschine eine Suchabfrage in einen Vektor um und findet Dokumente, deren Vektoren der Anfrage am ähnlichsten sind. Dabei wird die ungefähre Suche nach dem nächsten Nachbarn verwendet. Dieser Ansatz zur Vektorähnlichkeit ermöglicht den Abgleich von Dokumenten anhand ihrer Bedeutung und nicht nur anhand übereinstimmender Stichwörter.
