Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Funktionen und Grenzen der Vektorsuche
Verfügbarkeit der Vektorsuche
Die MemoryDB-Konfiguration mit aktivierter Vektorsuche wird auf den Knotentypen R6g, R7g und T4g unterstützt und ist in allen Regionen verfügbar, in denen MemoryDB verfügbar ist. AWS
Bestehende Cluster können nicht geändert werden, um die Suche zu ermöglichen. Cluster mit aktivierter Suche können jedoch aus Snapshots von Clustern mit deaktivierter Suche erstellt werden.
Parametrische Einschränkungen
Die folgende Tabelle zeigt Grenzwerte für verschiedene Vektor-Suchelemente:
| Item | Maximaler Wert |
|---|---|
| Anzahl der Dimensionen in einem Vektor | 32768 |
| Anzahl der Indizes, die erstellt werden können | 10 |
| Anzahl der Felder in einem Index | 50 |
| FT.SEARCH- und FT.AGGREGATE TIMEOUT-Klausel (Millisekunden) | 10000 |
| Anzahl der Pipeline-Stufen im Befehl FT.AGGREGATE | 32 |
| Anzahl der Felder in der FT.AGGREGATE LOAD-Klausel | 1024 |
| Anzahl der Felder in der FT.AGGREGATE GROUPBY-Klausel | 16 |
| Anzahl der Felder in der FT.AGGREGATE SORTBY-Klausel | 16 |
| Anzahl der Parameter in der FT.AGGREGATE PARAM-Klausel | 32 |
| HNSW M-Parameter | 512 |
| HNSW EF_KONSTRUKTIONSPARAMETER | 4096 |
| HNSW EF_RUNTIME-Parameter | 4096 |
Skalierungsgrenzen
Die Vektorsuche für MemoryDB ist derzeit auf einen einzelnen Shard beschränkt und die horizontale Skalierung wird nicht unterstützt. Die Vektorsuche unterstützt die vertikale Skalierung und die Skalierung von Replikaten.
Betriebliche Einschränkungen
Persistenz und Backfilling von Indizes
Die Vektorsuchfunktion speichert die Definition von Indizes und den Inhalt des Indexes. Das bedeutet, dass bei jeder Betriebsanfrage oder bei jedem Ereignis, das den Start oder Neustart eines Knotens veranlasst, die Indexdefinition und der Inhalt aus dem letzten Snapshot wiederhergestellt werden und alle ausstehenden Transaktionen aus dem Multi-AZ-Transaktionsprotokoll gelesen werden. Um dies zu initiieren, ist keine Benutzeraktion erforderlich. Die Wiederherstellung wird als Backfill-Vorgang ausgeführt, sobald die Daten wiederhergestellt sind. Dies entspricht funktionell der automatischen Ausführung eines FT.CREATE-Befehls durch das System für jeden definierten Index. Beachten Sie, dass der Knoten für Anwendungsoperationen verfügbar ist, sobald die Daten wiederhergestellt sind, aber wahrscheinlich noch bevor das Auffüllen des Index abgeschlossen ist. Das bedeutet, dass Backfill (s) wieder für Anwendungen sichtbar werden. Beispielsweise können Suchbefehle, die Backfill-Indizes verwenden, zurückgewiesen werden. Weitere Informationen zum Backfilling finden Sie unter. Überblick über die Vektorsuche
Der Abschluss des Index-Backfills wird nicht zwischen einem Primär- und einem Replikat synchronisiert. Dieser Mangel an Synchronisation kann für Anwendungen unerwartet sichtbar werden. Daher wird empfohlen, dass Anwendungen den Abschluss des Backfill-Vorgangs für Primärdateien und alle Replikate überprüfen, bevor sie Suchvorgänge einleiten.
Snapshot und Live-Migration import/export
Das Vorhandensein von Suchindizes in einer RDB-Datei schränkt die kompatible Übertragbarkeit dieser Daten ein. Das Format der Vektorindizes, das durch die MemoryDB-Vektorsuchfunktion definiert wird, wird nur von einem anderen MemoryDB-Vektor-Cluster verstanden. Außerdem können die RDB-Dateien aus den Vorschauclustern mit der GA-Version der MemoryDB-Cluster importiert werden, wodurch der Indexinhalt beim Laden der RDB-Datei neu erstellt wird.
RDB-Dateien, die keine Indizes enthalten, sind auf diese Weise jedoch nicht eingeschränkt. Somit können Daten innerhalb eines Vorschau-Clusters in Nicht-Vorschau-Cluster exportiert werden, indem die Indizes vor dem Export gelöscht werden.
Speicherverbrauch
Der Speicherverbrauch basiert auf der Anzahl der Vektoren, der Anzahl der Dimensionen, dem M-Wert und der Menge der Nicht-Vektordaten, z. B. Metadaten, die dem Vektor zugeordnet sind, oder auf anderen in der Instanz gespeicherten Daten.
Der Gesamtspeicherbedarf ist eine Kombination aus dem für die eigentlichen Vektordaten benötigten Speicherplatz und dem für die Vektorindizes benötigten Speicherplatz. Der für Vektordaten benötigte Speicherplatz wird berechnet, indem die tatsächliche Kapazität gemessen wird, die für das Speichern von Vektoren in HASH- oder JSON-Datenstrukturen erforderlich ist, und der Overhead bis zu den nächstgelegenen Speicherplatten, um optimale Speicherzuweisungen zu erzielen. Jeder der Vektorindizes verwendet Verweise auf die in diesen Datenstrukturen gespeicherten Vektordaten und verwendet effiziente Speicheroptimierungen, um alle doppelten Kopien der Vektordaten im Index zu entfernen.
Die Anzahl der Vektoren hängt davon ab, wie Sie Ihre Daten als Vektoren darstellen möchten. Sie können beispielsweise festlegen, dass ein einzelnes Dokument in mehreren Abschnitten dargestellt wird, wobei jeder Abschnitt einen Vektor darstellt. Sie können sich auch dafür entscheiden, das gesamte Dokument als einen einzigen Vektor darzustellen.
Die Anzahl der Dimensionen Ihrer Vektoren hängt vom ausgewählten Einbettungsmodell ab. Wenn Sie sich beispielsweise für das AWS Titan-Einbettungsmodell
Der Parameter M steht für die Anzahl der bidirektionalen Links, die bei der Indexerstellung für jedes neue Element erstellt werden. MemoryDB setzt diesen Wert standardmäßig auf 16; Sie können ihn jedoch überschreiben. Ein höherer M-Parameter eignet sich besser für hohe Abrufanforderungen mit hoher Dimensionalität and/or , während niedrige M-Parameter besser für niedrige Abrufanforderungen mit niedriger and/or Dimensionalität geeignet sind. Der M-Wert erhöht den Speicherverbrauch, wenn der Index größer wird, was den Speicherverbrauch erhöht.
In der Konsolenumgebung bietet MemoryDB eine einfache Möglichkeit, den richtigen Instance-Typ auf der Grundlage der Eigenschaften Ihres Vektor-Workloads auszuwählen, nachdem Sie in den Cluster-Einstellungen die Option Vektorsuche aktivieren aktiviert haben.
Beispiel für eine Arbeitslast
Ein Kunde möchte eine semantische Suchmaschine aufbauen, die auf seinen internen Finanzdokumenten aufbaut. Sie verfügen derzeit über 1 Million Finanzdokumente, die mithilfe des Titan-Einbettungsmodells mit 1536 Dimensionen in 10 Vektoren pro Dokument aufgeteilt sind und keine Daten enthalten, die keine Vektordaten enthalten. Der Kunde entscheidet sich dafür, den Standardwert 16 als M-Parameter zu verwenden.
Vektoren: 1 M * 10 Blöcke = 10 Millionen Vektoren
Abmessungen: 1536
Daten ohne Vektoren (GB): 0 GB
M-Parameter: 16
Mit diesen Daten kann der Kunde in der Konsole auf die Schaltfläche Vektorrechner verwenden klicken, um anhand seiner Parameter einen empfohlenen Instanztyp zu erhalten:
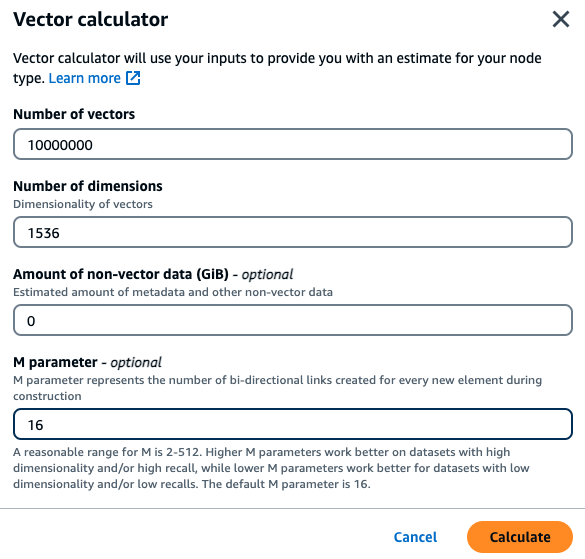

In diesem Beispiel sucht der Vektorrechner anhand der angegebenen Parameter nach dem kleinsten MemoryDB-R7G-Knotentyp
Basierend auf der obigen Berechnungsmethode und den Parametern im Beispiel-Workload würden für diese Vektordaten 104,9 GB zum Speichern der Daten und eines einzelnen Index benötigt. In diesem Fall würde der db.r7g.4xlarge Instance-Typ empfohlen, da er über 105,81 GB nutzbaren Speicher verfügt. Der nächstkleinere Knotentyp wäre zu klein, um die Vektor-Arbeitslast aufzunehmen.
Da jeder der Vektorindizes Verweise auf die gespeicherten Vektordaten verwendet und keine zusätzlichen Kopien der Vektordaten im Vektorindex erstellt, verbrauchen die Indizes auch relativ weniger Speicherplatz. Dies ist sehr nützlich bei der Erstellung mehrerer Indizes und auch in Situationen, in denen Teile der Vektordaten gelöscht wurden. Die Rekonstruktion des HNSW-Graphen würde dazu beitragen, optimale Knotenverbindungen für qualitativ hochwertige Vektorsuchergebnisse zu schaffen.
Nicht genügend Speicher beim Auffüllen
Ähnlich wie bei den OSS-Schreiboperationen von Valkey und Redis unterliegt ein Index-Backfill Einschränkungen. out-of-memory Wenn der Engine-Speicher voll ist, während ein Backfill läuft, werden alle Backfills angehalten. Wenn Speicher verfügbar wird, wird der Backfill-Vorgang wieder aufgenommen. Es ist auch möglich, zu löschen und zu indizieren, wenn das Auffüllen aufgrund von Speichermangel unterbrochen wird.
Transaktionen
Die BefehleFT.CREATE,, FT.DROPINDEX FT.ALIASADDFT.ALIASDEL, und FT.ALIASUPDATE können nicht in einem Transaktionskontext ausgeführt werden, d. h. nicht innerhalb eines MULTI/EXEC Blocks oder innerhalb eines LUA- oder FUNCTION-Skripts.
