Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Gremlin-Ladedatenformat
Um Apache TinkerPop Gremlin-Daten im CSV-Format zu laden, müssen Sie die Scheitelpunkte und Kanten in separaten Dateien angeben.
Der Loader kann in einem einzigen Ladeauftrag aus mehreren Vertex-Dateien und mehreren Edge-Dateien laden.
Für jeden Ladebefehl muss sich der Satz der Dateien, die geladen werden sollen, im selben Ordner im Amazon-S3-Bucket befinden. Sie geben den Ordnernamen für den Parameter source an. Die Dateinamen und -erweiterungen sind nicht wichtig.
Das Amazon-Neptune-CSV-Format entspricht der CSV-Spezifikation RFC 4180. Weitere Informationen finden Sie unter Common Format and MIME Type for CSV Files
Anmerkung
Alle Dateien müssen im UTF-8-Format kodiert sein.
Jede Datei verfügt über eine durch Komma getrennte Kopfzeile. Die Kopfzeile besteht aus System- und Eigenschaftenspalten-Headern.
Systemspalten-Header
Die erforderlichen und zulässigen Systemspalten-Header sind für Knoten- und Kantendateien unterschiedlich.
Jede Systemspalte kann nur einmal in einem Header enthalten sein.
Bei den Bezeichnungen muss die Groß- und Kleinschreibung beachtet werden.
Knoten-Header
-
~id– ErforderlichEine ID für den Knoten.
-
~labelEine Bezeichnung für den Knoten. Es sind mehrere Bezeichnungswerte zulässig, getrennt durch Semikolon (
;).Falls nicht vorhanden,
~labelwird eine TinkerPop Bezeichnung mit dem Wert bereitgestelltvertex, da jeder Scheitelpunkt mindestens eine Bezeichnung haben muss.
Kanten-Header
-
~id– ErforderlichEine ID für die Kante.
-
~from– ErforderlichDie Knoten-ID des von-Knotens.
-
~to– ErforderlichDie Knoten-ID des nach-Knotens.
-
~labelEine Bezeichnung für die Kante. Kanten können immer nur eine Bezeichnung enthalten.
Wenn nicht vorhanden,
~labelwird TinkerPop eine Bezeichnung mit dem Wert bereitgestelltedge, da jede Kante eine Bezeichnung haben muss.
Eigenschaftenspalten-Header
Sie können eine Spalte (:) für eine Eigenschaft angeben, indem Sie die folgende Syntax verwenden. Bei den Typnamen muss die Groß- und Kleinschreibung nicht berücksichtigt werden. Ein Doppelpunkt muss mit einem vorangestellten umgekehrten Schrägstrich maskiert werden, wenn er im Namen einer Eigenschaft erscheint: \:.
propertyname:type
Anmerkung
Leerzeichen, Kommas, Zeilenumbrüche und Zeilenumbrüche sind in den Spaltenüberschriften nicht zulässig, sodass Eigenschaftsnamen diese Zeichen nicht enthalten dürfen.
Sie können eine Spalte für einen Array-Typ festlegen, indem Sie dem Typ [] hinzufügen:
propertyname:type[]
Anmerkung
Edge-Eigenschaften können nur einen einzelnen Wert haben und verursachen einen Fehler, wenn ein Array-Typ oder ein zweiter Wert angegeben ist.
Das folgende Beispiel zeigt den Spalten-Header für eine Eigenschaft mit dem Namen age des Typs Int.
age:Int
Für jede Zeile in der Datei ist eine Ganzzahl in dieser Position erforderlich oder sie muss leer sein.
Zeichenfolgen-Arrays sind zulässig. Zeichenfolgen in einem Array dürfen jedoch kein Semikolon (;) enthalten, es sei denn, es wird mit einem umgekehrten Schrägstrich maskiert (wie hier: \;).
Angeben der Kardinalität einer Spalte
Beginnend mit Release 1.0.1.0.200366.0 (26.07.2019) kann die Spaltenüberschrift verwendet werden, um die Kardinalität für die durch die Spalte identifizierte Eigenschaft anzugeben. Auf diese Weise kann der Massen-Loader die Kardinalität ähnlich wie Gremlin-Abfragen berücksichtigen.
Sie geben die Kardinalität einer Spalte wie folgt an:
propertyname:type(cardinality)
Der cardinality Wert kann entweder oder sein. single set Als Standardwert wird set angenommen, Dies bedeutet, dass die Spalte mehrere Werte akzeptieren kann. Bei Edge-Dateien ist die Kardinalität immer einzeln und die Angabe einer anderen Kardinalität bewirkt, dass der Loader eine Ausnahme auslöst.
Wenn die Kardinalität single lautet, gibt der Loader einen Fehler aus, wenn beim Laden eines Wertes bereits ein vorheriger Wert vorhanden ist oder wenn mehrere Werte geladen werden. Dieses Verhalten kann überschrieben werden, sodass ein vorhandener Wert ersetzt wird, wenn ein neuer Wert unter Verwendung des Flags updateSingleCardinalityProperties geladen wird. Siehe Loader-Befehl.
Es ist möglich, die Kardinalitätseinstellung mit einem Array-Typ zu vewenden, obwohl dies im Allgemeinen nicht erforderlich ist. Dies sind die möglichen Kombinationen:
name:type– Die Kardinalität istsetund der Inhalt ist einwertig.name:type[]– Die Kardinalität istsetund der Inhalt ist mehrwertig.name:type(single)– Die Kardinalität istsingleund der Inhalt ist einwertig.name:type(set)– Die Kardinalität istset, was dem Standardwert entspricht, und der Inhalt ist einwertig.name:type(set)[]– Die Kardinalität istsetund der Inhalt ist mehrwertig.name:type(single)[]– Dies ist widersprüchlich und führt zu einem Fehler.
Im folgenden Abschnitt werden alle verfügbaren Gremlin-Datentypen aufgeführt.
Gremlin-Datentypen
Dies ist eine Liste der zulässigen Eigenschaftstypen mit einer Beschreibung des jeweiligen Typs.
Bool (oder Boolesch)
Gibt ein boolesches Feld an. Zulässige Werte: false, true
Anmerkung
Jeder andere Wert als true wird als „false“ behandelt.
Ganzzahltypen
Werte außerhalb der definierten Bereiche verursachen einen Fehler.
| Typ | Bereich |
|---|---|
| Byte | -128 bis +127 |
| Short | -32768 bis +32767 |
| Int | -2^31 bis 2^31-1 |
| Long | -2^63 bis 2^63-1 |
Dezimalzahltypen
Unterstützt sowohl die Dezimalschreibweise als auch die wissenschaftliche Notation. Außerdem können Symbole wie (+/-), Infinity oder NaN verwendet werden. INF wird nicht unterstützt.
| Typ | Bereich |
|---|---|
| Gleitkommazahl | 32-Bit IEEE 754-Gleitkommawert |
| Double | 64-Bit IEEE 754-Gleitkommawert |
Zu lange Gleitkommazahlen und Double-Werte werden geladen und auf den nächsten Wert für 24-Bit- (Gleitkommazahl) und 53-Bit-Genauigkeit (Double) gerundet. Ein in der Mitte liegender Wert wird für die letzte verbleibende Stelle auf Bit-Ebene auf 0 gerundet.
String
Anführungszeichen sind optional. Kommas, Zeilenumbruch- und Wagenrücklaufzeichen werden automatisch mit Escape-Zeichen markiert, wenn sie in einer Zeichenfolge enthalten sind, die von doppelten Anführungszeichen (") umschlossen ist. Beispiel: "Hello,
World"
Um Anführungszeichen in einer in Anführungszeichen gesetzte Zeichenfolge aufzunehmen, können Sie das Anführungszeichen mit Escape-Zeichen markieren, indem Sie zwei in einer Zeile verwenden: Beispiel: "Hello
""World"""
Zeichenfolgen-Arrays sind zulässig. Zeichenfolgen in einem Array dürfen jedoch kein Semikolon (;) enthalten, es sei denn, es wird mit einem umgekehrten Schrägstrich maskiert (wie hier: \;).
Wenn Sie Zeichenfolgen in einem Array in Anführungszeichen setzen möchten, müssen Sie das gesamte Array mit einem Satz Anführungszeichen versehen. Beispiel: "String one; String 2; String 3"
Datum
Java-Datum im ISO 8601-Format. Unterstützt die folgenden Formate:yyyy-MM-dd,yyyy-MM-ddTHH:mm,yyyy-MM-ddTHH:mm:ss,yyyy-MM-ddTHH:mm:ssZ. Die Werte werden in Epochenzeit umgewandelt und gespeichert.
DateTime
Java-Datum im ISO 8601-Format. Unterstützt die folgenden Formate:yyyy-MM-dd,, yyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mm:ss,yyyy-MM-ddTHH:mm:ssZ. Die Werte werden in Epochenzeit umgewandelt und gespeichert.
Gremlin-Zeilenformat
Trennzeichen
Felder in einer Zeile werden durch ein Komma getrennt. Die Datensätze werden durch einen Zeilenumbruch oder einen Zeilenumbruch gefolgt von einem Wagenrücklauf getrennt.
Leere Felder
Leere Felder sind für nicht erforderliche Spalten zulässig (z. B. benutzerdefinierte Eigenschaften). Ein leeres Feld erfordert dennoch ein Komma als Trennzeichen. Leere Felder in erforderlichen Spalten führen zu einem Analysefehler. Leere Zeichenkettenwerte werden als leerer Zeichenkettenwert für das Feld interpretiert, nicht als leeres Feld. Das Beispiel im nächsten Abschnitt enthält in jedem Beispielknoten ein leeres Feld.
Scheitelpunkt IDs
~id-Werte müssen für alle Knoten in allen Knotendateien eindeutig sein. Mehrere Knotenzeilen mit identischen ~id-Werten werden auf einen einzigen Knoten im Graph angewendet. Eine leere Zeichenfolge ("") ist eine gültige ID, und der Scheitelpunkt wird mit einer leeren Zeichenfolge als ID erstellt.
Kante IDs
Darüber hinaus müssen ~id-Werte für alle Kanten in allen Kantendateien eindeutig sein. Mehrere Kantenzeilen mit identischen ~id-Werten werden auf die einzige Kante im Graph angewendet. Eine leere Zeichenfolge ("") ist eine gültige ID, und die Kante wird mit einer leeren Zeichenfolge als ID erstellt.
Labels
Bei Labels wird zwischen Groß- und Kleinschreibung unterschieden und sie dürfen nicht leer sein. Ein Wert von "" führt zu einem Fehler.
Zeichenfolgenwerte
Anführungszeichen sind optional. Kommas, Zeilenumbruch- und Wagenrücklaufzeichen werden automatisch mit Escape-Zeichen markiert, wenn sie in einer Zeichenfolge enthalten sind, die von doppelten Anführungszeichen (") umschlossen ist. Leere Zeichenkettenwerte ("") werden als leerer Zeichenkettenwert für das Feld interpretiert, nicht als leeres Feld.
CSV-Formatspezifikation
Das Neptune-CSV-Format entspricht der CSV-Spezifikation RFC 4180, einschließlich der folgenden Anforderungen.
Es werden sowohl Unix- als auch Windows-Zeilenenden unterstützt (\n oder \r\n).
Jedes Feld kann mit (doppelten) Anführungszeichen versehen werden.
Felder, die einen Zeilenumbruch, doppelte Anführungszeichen oder Kommas enthalten, müssen in Anführungszeichen gesetzt werden. (Andernfalls wird der Ladevorgang sofort abgebrochen.)
Eine doppeltes Anführungszeichen (
") in einem Feld muss durch zwei (doppelte) Anführungszeichen dargestellt werden. Beispiel: Eine ZeichenfolgeHello "World"muss als"Hello ""World"""in den Daten dargestellt werden.Umgebende Leerzeichen zwischen Trennzeichen werden ignoriert. Wenn eine Zeile als vorhanden ist
value1, value2, werden sie als"value1"und gespeichert"value2".Alle anderen Escapezeichen werden unverändert gespeichert. Zum Beispiel wird
"data1\tdata2"als"data1\tdata2"gespeichert. Es sind keine weiteren Escapezeichen erforderlich, solange diese Zeichen in Anführungszeichen gesetzt sind.Leere Felder sind zulässig. Ein leeres Feld wird als leerer Wert interpretiert.
Mehrere Werte für ein Feld werden mit einem Semikolon (
;) zwischen den Werten angegeben.
Weitere Informationen finden Sie unter Common Format and MIME Type for CSV Files
Gremlin-Beispiel
Das folgende Diagramm zeigt ein Beispiel für zwei Scheitelpunkte und eine Kante aus dem TinkerPop Modern Graph.
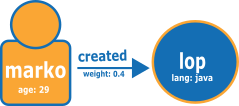
Die folgende Abbildung zeigt das Diagramm im Neptune-CSV-Ladeformat.
Knotendatei:
~id,name:String,age:Int,lang:String,interests:String[],~label v1,"marko",29,,"sailing;graphs",person v2,"lop",,"java",,software
Tabellarische Ansicht der Knotendatei:
| ~id | name:String | age:Int | lang:String | Interessen: Zeichenfolge [] | ~label |
| v1 | "marko" | 29 | ["Segeln“, „Graphen"] | Person | |
| v2 | "lop" | "java" | software |
Kantendatei:
~id,~from,~to,~label,weight:Double e1,v1,v2,created,0.4
Tabellarische Ansicht der Kantendatei:
| ~id | ~from | ~auf | ~label | weight:Double |
| e1 | v1 | v2 | created | 0.4 |
Nächste Schritte
Da Sie jetzt über ausführlichere Kenntnisse von Ladeformaten verfügen, fahren Sie mit Beispiel: Laden von Daten in eine Neptune-DB-Instance fort.
