Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Unterstützte SSML-Tags
Amazon Polly unterstützt die folgenden SSML-Tags:
| Aktion | SSML-Tag | Verfügbarkeit mit neuronalen Stimmen | Verfügbarkeit mit Sprachnachrichten in langer Form |
|---|---|---|---|
|
<break> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
| <emphasis> |
Nicht verfügbar |
Nicht verfügbar |
|
| <lang> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
| <mark> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<p> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<phoneme> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<prosody> |
Teilweise Verfügbarkeit |
Teilweise Verfügbarkeit |
|
|
<prosody amazon:max-duration> |
Nicht verfügbar |
Nicht verfügbar |
|
|
<s> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<say-as> |
Teilweise Verfügbarkeit |
Teilweise Verfügbarkeit |
|
|
<speak> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<sub> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<w> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<amazon:auto-breaths> |
Nicht verfügbar |
Nicht verfügbar |
|
| <amazon:domain name="news"> |
Nur neuronale Stimmen auswählen |
Nicht verfügbar |
|
|
<amazon:effect name="drc"> |
Vollständige Verfügbarkeit |
Vollständige Verfügbarkeit |
|
|
<amazon:effect phonation="soft"> |
Nicht verfügbar |
Nicht verfügbar |
|
|
<amazon:Auswirkung vocal-tract-length> |
Nicht verfügbar |
Nicht verfügbar |
|
|
<amazon:effect name="whispered"> |
Nicht verfügbar |
Nicht verfügbar |
Anmerkung
Wenn Sie nicht unterstützte SSML-Tags im Standard-, neuronalen oder Langformformat verwenden, erhalten Sie eine Fehlermeldung.
Identifizieren von SSML-erweitertem Text
<speak>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Das <speak> Tag ist das Stammelement des gesamten Amazon Polly-SSML-Texts. Der gesamte Text mit SSML-Tags muss in ein Paar <speak>-Tags eingeschlossen werden.
<speak>Mary had a little lamb.</speak>Hinzufügen einer Pause
<break>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Verwenden Sie das Tag <break>, um Ihrem Text eine Pause hinzuzufügen. Sie können eine Pause auf Grundlage der Stärke (entspricht der Pause nach einem Komma, Satz oder Absatz) oder den Wert auf eine bestimmte Dauer in Sekunden oder Millisekunden festlegen. Wenn Sie kein Attribut angeben, um die Pausenlänge zu bestimmen, verwendet Amazon Polly den Standardwert , der ist<break strength="medium"/>, wodurch die Länge einer Pause nach einem Komma hinzugefügt wird.
Werte des Attributs strength:
-
none: Keine Pause. Verwenden Sienone, um standardmäßig auftretende Pausen – z. B. nach einem Punkt – zu entfernen. -
x-weak: Hat die gleiche Wirkung wienone, keine Pause. -
weak: Legt eine Pause derselben Dauer wie die Pause nach einem Komma fest. -
medium: Hat die gleiche Wirkung wieweak. -
strong: Legt eine Pause derselben Dauer wie die Pause nach einem Satz fest. -
x-strong: Legt eine Pause derselben Dauer wie die Pause nach einem Absatz fest.
Werte des Attributs time:
-
[number]s10s. -
[number]ms10000ms.
Beispielsweise:
<speak>
Mary had a little lamb <break time="3s"/>Whose fleece was white as snow.
</speak>Wenn Sie kein Attribut mit dem break-Tag verwenden, variiert das Ergebnis je nach Text:
-
Wenn sich neben dem
break-Tag keine anderen Satzzeichen befinden, wird eine<break strength="medium"/>(Pause in Komma-Länge) erstellt. -
Wenn sich das Tag neben einem Komma befindet, wird es zu einer
<break strength="strong"/>(Pause in Satz-Länge). -
Wenn sich das Tag neben einem Punkt befindet, wird es zu einer
<break strength="x-strong"/>(Pause in Absatz-Länge).
Hervorheben von Wörtern
<emphasis>
Dieses Tag wird nur vom Standard-TTS-Format unterstützt.
Verwenden Sie das Tag <emphasis>, um Wörter zu betonen. Die Betonung von Wörtern wirkt sich auf Sprechgeschwindigkeit und -lautstärke aus. Wenn Amazon Polly stärker hervorgehoben ist, spricht der Textzähler und langsamer. Bei weniger Betonung wird leiser und schneller gesprochen. Die Stärke der Betonung geben Sie mit dem Attribut level an.
Werte des Attributs level:
-
Strong: Erhöht die Lautstärke und verlangsamt die Sprechgeschwindigkeit, sodass die Sprachausgabe lauter und langsamer erfolgt. -
Moderate: Erhöht die Lautstärke und verlangsamt die Sprechgeschwindigkeit in geringerem Umfang alsstrong.Moderateist die Standardeinstellung. -
Reduced: Verringert die Lautstärke und beschleunigt die Sprechgeschwindigkeit. Die Sprachausgabe ist weicher und schneller.
Anmerkung
Die normale Sprechgeschwindigkeit und -lautstärke liegen zwischen moderate und reduced.
Beispielsweise:
<speak> I already told you I <emphasis level="strong">really like</emphasis> that person. </speak>
Angeben einer anderen Sprache für bestimmte Wörter
<lang>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Mit dem Tag <lang> können Sie eine andere Sprache für ein Wort, eine Wendung oder einen Satz angeben. Fremdsprachige Wörter und Wendungen werden in der Regel besser gesprochen, wenn sie in ein Paar <lang>-Tags eingeschlossen werden. Verwenden Sie zum Angeben der Sprache das Attribut xml:lang. Eine vollständige Liste der verfügbaren Sprachen finden Sie unter Von Amazon Polly unterstützte Sprachen.
Sofern Sie nicht das Tag <lang> anwenden, werden alle Wörter im Eingabetext in der Sprache der Stimme gesprochen, die mit voice-id angegeben wurde. Wenn Sie das Tag <lang> anwenden, werden die Wörter in jener Sprache gesprochen.
Wenn beispielsweise Joanna (die US-Englisch spricht) voice-id ist, spricht Amazon Polly in der Joanna-Stimme ohne Französischen Akzenten Folgendes:
<speak>
Je ne parle pas français.
</speak>Wenn Sie die Joanna-Stimme mit dem -<lang>Tag verwenden, spricht Amazon Polly den Satz in der Joanna-Stimme auf Französisch mit amerikanischem Schwerpunkt:
<speak>
<lang xml:lang="fr-FR">Je ne parle pas français.</lang>.
</speak>Da Joanna keine französische Muttersprachlerin ist, basiert die Aussprache auf ihrer Muttersprache, also US-Englisch. Eine Person mit perfekter französischer Aussprache würde beispielsweise das Wort français mit einem uvularen Vibrant (/R/) sprechen. Joannas Stimme (US-Englisch) spricht dieses Phonem dagegen wie /r/.
Wenn Sie die voice-id von Gior Bol verwenden, die Italienisch spricht, mit dem folgenden Text, spricht Amazon Polly den Satz in Giors Stimme mit einer Italienischen Aussprache:
<speak>
Mi piace Bruce Springsteen.
</speak>Wenn Sie dieselbe Stimme mit dem folgenden <lang> Tag verwenden, gibt Amazon Polly Bruce Springsteen in Italienisch hervorgehobenem Englisch bekannt:
<speak>
Mi piace <lang xml:lang="en-US">Bruce Springsteen.</lang>
</speak>Dieses Tag kann beim Synthetisieren von Sprache auch als Ersatz für die optionale DefaultLangCode Option verwendet werden. In diesem Fall ist es jedoch erforderlich, dass Sie Ihren Text mit SSML formatieren.
Platzieren eines benutzerdefinierten Tags in Ihrem Text
<mark>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Um ein benutzerdefiniertes Tag in den Text einzufügen, verwenden Sie das Tag <mark>. Amazon Polly ergreift keine Aktion für das Tag, gibt jedoch den Speicherort des Tags in den SSML-Metadaten zurück. Bei diesem Tag kann es sich um eine beliebige hervorzuhebende Information handeln, sofern das folgende Format eingehalten wird:
<mark name="tag_name"/>Beispiel: Der Tag-Name lautet "animal" und der Eingabetext:
<speak>
Mary had a little <mark name="animal"/>lamb.
</speak>Amazon Polly gibt möglicherweise die folgenden SSML-Metadaten zurück:
{"time":767,"type":"ssml","start":25,"end":46,"value":"animal"}Hinzufügen einer Pause zwischen Absätzen
<p>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Mit dem Tag <p> können Sie eine Pause zwischen Absätzen im Text einfügen. Mit diesem Tag wird eine längere Pause als die eingefügt, die Muttersprachler üblicherweise nach Kommas oder am Satzende einfügen. Schließen Sie den Absatz in das Tag <p> ein:
<speak>
<p>This is the first paragraph. There should be a pause after this text is spoken.</p>
<p>This is the second paragraph.</p>
</speak>Dies entspricht der Angabe einer Pause mit <break strength="x-strong"/>.
Verwenden der phonetischen Aussprache
<phoneme>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Um Amazon Polly die phonetische Aussprache für bestimmten Text zu verwenden, verwenden Sie das Tag <phoneme>.
Für das Tag <phoneme> sind zwei Attribute erforderlich. Sie zeigen das von Amazon Polly verwendete phonetische Alphabet und die phonetischen Symbole der korrigierten Aussprache an:
-
alphabet-
ipa: Gibt an, dass das IPA (International Phonetic Alphabet) verwendet wird. -
x-sampa: Gibt an, dass X-SAMPA (Extended Speech Assessment Methods Phonetic Alphabet) verwendet wird.
-
-
ph-
Gibt die phonetischen Symbole für die Aussprache an. Weitere Informationen finden Sie unter Phonem- und Mundbildtabellen für unterstützte Sprachen.
-
Mit dem <phoneme> Tag verwendet Amazon Polly die durch das ph Attribut angegebene Aussprache anstelle der standardmäßig mit der Sprache verknüpften Standardaussprache, die von der ausgewählten Stimme verwendet wird.
Das Wort „pecan“ kann beispielsweise auf zwei Arten ausgesprochen werden. Im folgenden Beispiel wird „pecan“ in jeder Zeile eine andere Aussprache zugewiesen. Amazon Polly gibt Pecan wie in den ph Attributen angegeben aus, anstatt die Standardaussprache zu verwenden.
International Phonetic Alphabet (IPA)
<speak> You say, <phoneme alphabet="ipa" ph="pɪˈkɑːn">pecan</phoneme>. I say, <phoneme alphabet="ipa" ph="ˈpi.kæn">pecan</phoneme>. </speak>
Extended Speech Assessment Methods Phonetic Alphabet (X-SAMPA)
<speak> You say, <phoneme alphabet='x-sampa' ph='pI"kA:n'>pecan</phoneme>. I say, <phoneme alphabet='x-sampa' ph='"pi.k{n'>pecan</phoneme>. </speak>
Bol Chinesisch verwendet Pinyin für die phonetische Aussprache.
Pinyin
<speak> 你说 <phoneme alphabet="x-amazon-pinyin" ph="bo2">薄</phoneme>。 我说 <phoneme alphabet="x-amazon-pinyin" ph="bao2">薄</phoneme>。 </speak>
Japanisch verwendet Yomigana und Aussprache-Kana.
Yomigana
<speak> 名前は<phoneme alphabet="x-amazon-yomigana" ph="ひろかず">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="ヒロカズ">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="Hirokazu">浩一</phoneme>です。 </speak>
Aussprache Kana
<speak> 名前は<phoneme alphabet="x-amazon-pron-kana" ph="ヒロ'カズ">浩一</phoneme>です。 </speak>
Steuern von Volumen, Sprechrate und Tonhöhe
<prosody>
Prosody-Tag-Attribute werden von den TTS-Standardstimmen vollständig unterstützt. Neurale und Langformstimmen unterstützen die rate Attribute volume und , jedoch nicht das pitch Attribut .
Mit dem prosody-Tag können Sie Lautstärke, Geschwindigkeit und Tonlage Ihrer gewählten Stimme steuern.
Lautstärke, Sprechgeschwindigkeit und Tonlage sind von der jeweils gewählten Stimme abhängig. Neben den Unterschieden der Stimmen für verschiedene Sprachen gibt es auch Unterschiede zwischen Stimmen, die dieselbe Sprache sprechen. Hieraus erklärt sich, dass es trotz zwischen den Sprachen ähnlicher Attribute klare Unterschiede von Sprache zu Sprache gibt. Absolute Werte existieren nicht.
Das Tag prosody hat drei Attribute, für die jeweils unterschiedliche Werte verfügbar sind. Jedes Attribut verwendet die gleiche Syntax:
<prosody attribute="value"></prosody>-
volume-
default: Setzt die Lautstärke auf den Standardwert für die aktuelle Stimme zurück. -
silent,x-soft,soft,medium,loud,x-loud: Legt die Lautstärke auf einen vordefinierten Wert für die aktuelle Stimme fest. -
+ndB,-ndB: Ändert die Lautstärke relativ zum aktuellen Pegel. Ein Wert von+0dBbedeutet keine Änderung,+6dBbedeutet in etwa eine Verdoppelung der aktuellen Lautstärke und-6dBbedeutet ungefähr eine Halbierung der aktuellen Lautstärke.
Sie können die Lautstärke für eine Passage beispielsweise folgendermaßen einstellen:
<speak> Sometimes it can be useful to <prosody volume="loud">increase the volume for a specific speech.</prosody> </speak>Sie können die Lautstärke auch folgendermaßen festlegen:
<speak> And sometimes a lower volume <prosody volume="-6dB">is a more effective way of interacting with your audience.</prosody> </speak> -
-
rate-
x-slow,slow,medium,fast,x-fast. Legt den Tonhöhenwert auf einen vordefinierten Wert für die ausgewählte Stimme fest. -
n%: Eine Änderung der Sprechgeschwindigkeit um einen Prozentsatz (nicht negativ). Beispiel: Ein Wert von 100 % bedeutet, dass die Sprechgeschwindigkeit unverändert bleibt. Ein Wert von 200 % bedeutet, dass die Sprechgeschwindigkeit verdoppelt, und ein Wert von 50 %, dass die Sprechgeschwindigkeit halbiert wird. Der Wert kann zwischen 20 und 200 % liegen.
Sie können die Sprechgeschwindigkeit für eine Passage beispielsweise folgendermaßen einstellen:
<speak> For dramatic purposes, you might wish to <prosody rate="slow">slow up the speaking rate of your text.</prosody> </speak>Sie können die Lautstärke auch folgendermaßen festlegen:
<speak> Although in some cases, it might help your audience to <prosody rate="85%">slow the speaking rate slightly to aid in comprehension.</prosody> </speak> -
-
pitch-
default: Setzt die Tonlage auf den Standardwert für die aktuelle Stimme zurück. -
x-low,low,medium,high,x-high: Legt die Tonlage auf einen vordefinierten Wert für die aktuelle Stimme fest. -
+n%oder-n%: passt die Tonhöhe um einen relativen Prozentsatz an. Beispiel: Ein Wert von+0%bedeutet keine Änderung der Baseline-Tonhöhe,+5%führt zu einer etwas höheren Baseline-Tonhöhe und-5%führt zu einer etwas niedrigeren Baseline-Tonhöhe.
Sie können die Tonlage für eine Passage beispielsweise folgendermaßen einstellen:
<speak> Do you like sythesized speech <prosody pitch="high">with a pitch that is higher than normal?</prosody> </speak>Sie können die Lautstärke auch folgendermaßen festlegen:
<speak> Or do you prefer your speech <prosody pitch="-10%">with a somewhat lower pitch?</prosody> </speak> -
Das Tag <prosody> muss mindestens ein Attribut, kann aber auch mehrere enthalten.
<speak> Each morning when I wake up, <prosody volume="loud" rate="x-slow">I speak quite slowly and deliberately until I have my coffee.</prosody> </speak>
Es kann zudem folgendermaßen mit verschachtelten Tags kombiniert werden:
<speak> <prosody rate="85%">Sometimes combining attributes <prosody pitch="-10%">can change the impression your audience has of a voice</prosody> as well.</prosody> </speak>
Festlegen einer maximalen Dauer für synthetisierte Sprache
<prosody amazon:max-duration>
Dieses Tag wird derzeit nur vom Standard-TTS-Format unterstützt.
Um zu steuern, wie lange eine Sprachausgabe dauern soll, wenn sie generiert wird, verwenden Sie das <prosody>-Tag mit dem amazon:max-duration-Attribut.
Die Dauer der Sprachsynthese variiert je nach gewählter Stimme geringfügig. Dies erschwert die Abstimmung von generierter Sprache mit Visualisierungen oder anderen Aktivitäten, die ein präzises Timing erfordern. Dieses Problem tritt verstärkt bei Übersetzungsanwendungen auf, da die Zeit, die benötigt wird, um bestimmte Phrasen zu sagen, je nach Sprache stark variieren kann.
Das <prosody amazon:max-duration>-Tag passt die synthetisierte Sprache an die gewünschte Dauer an.
Dieses Tag verwendet folgende Syntax:
<prosody amazon:max-duration="time duration">Mit dem <prosody amazon:max-duration>-Tag können Sie die Dauer in Sekunden oder Millisekunden festlegen:
-
ns -
nms
Beispiel: Der folgende gesprochene Text hat eine maximale Dauer von 2 Sekunden:
<speak>
<prosody amazon:max-duration="2s">
Human speech is a powerful way to communicate.
</prosody>
</speak>Wenn Text innerhalb des Tags platziert wird, überschreitet er die angegebene Dauer nicht. Wenn die gewählte Sprache normalerweise länger als diese Dauer dauern würde, beschleunigt Amazon Polly die Sprache, sodass sie der angegebenen Dauer entspricht.
Wenn die angegebene Dauer länger ist als das Lesen des Textes mit normaler Geschwindigkeit, liest Amazon Polly die Sprache normal. Es verlangsamt weder die Sprachausgabe noch werden Stilleperioden hinzugefügt. Die resultierende Audioausgabe ist also kürzer als angefordert.
Anmerkung
Amazon Polly erhöht die Geschwindigkeit nicht um das Fünffache der normalen Rate. Wenn Text schneller gesprochen wird, ergibt er in der Regel keinen Sinn. Wenn eine Sprachausgabe auch bei maximaler Beschleunigung nicht in die angegebene Dauer passt, wird das Audiomaterial beschleunigt, ist dann jedoch länger als die angegebene Dauer.
Sie können einen einzelnen Satz oder mehrere Sätze innerhalb eines <prosody amazon:max-duration>-Tags und mehrere <prosody amazon:max-duration>-Tags in Ihrem Text verwenden.
Beispielsweise:
<speak> <prosody amazon:max-duration="2400ms"> Human speech is a powerful way to communicate. </prosody> <break strength="strong"/> <prosody amazon:max-duration="5100ms"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> <break strength="strong"/> <prosody amazon:max-duration="8900ms"> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak>
Die Verwendung des -<prosody amazon:max-duration>Tags kann die Latenz erhöhen, wenn Amazon Polly synthetisierte Sprache zurückgibt. Der Grad der Latenz hängt von der Passage und ihrer Länge ab. Wir empfehlen die Verwendung von Text aus relativ kurzen Textpassagen.
Einschränkungen
Es gibt Einschränkungen sowohl bei der Verwendung des <prosody
amazon:max-duration>-Tags als auch bei der Funktion des Tags mit anderen SSML-Tags:
-
Der Text innerhalb eines
<prosody amazon:max-duration>-Tags kann nicht mehr als 1 500 Zeichen betragen. -
Sie können keine
<prosody amazon:max-duration>-Tags verschachteln. Wenn Sie ein<prosody amazon:max-duration>Tag in ein anderes einfügen, ignoriert Amazon Polly das innere Tag.Im folgenden Beispiel wird das
<prosody amazon:max-duration="5s">-Tag ignoriert:<speak> <prosody amazon:max-duration="16s"> Human speech is a powerful way to communicate. <prosody amazon:max-duration="5s"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak> -
Es ist nicht möglich, die
<prosody>-Tags mit demrate-Attribut innerhalb eines<prosody amazon:max-duration>-Tags zu verwenden. Denn beide beeinflussen die Geschwindigkeit, mit der der Text gesprochen wird.Im folgenden Beispiel ignoriert Amazon Polly das -
<prosody rate="2">Tag:<speak> <prosody amazon:max-duration="7500ms"> Human speech is a powerful way to communicate. <prosody rate="2"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </prosody> </speak>
Pausiert und max-duration
Bei der Verwendung Ihres max-duration-Tags können Sie weiterhin Pausen in Ihren Text einfügen. Amazon Polly berücksichtigt jedoch die Länge der Pause bei der Berechnung der maximalen Sprachdauer. Darüber hinaus behält Amazon Polly die kurzen Pausen bei, die auftreten, wenn Kommas und Punkte innerhalb einer Passage platziert werden, und nimmt die maximale Dauer auf.
Beispiel: Im folgenden Block kommen Pausen von 600 Millisekunden und die durch Kommata und Punkte verursachten Pausen innerhalb der 8-Sekunden-Sprachausgabe vor:
<speak> <prosody amazon:max-duration="8s"> Human speech is a powerful way to communicate. <break time="600ms"/> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </speak>
Hinzufügen einer Pause zwischen Sätzen
<s>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Mit dem Tag <s> können Sie eine Pause zwischen Zeilen oder Sätzen im Text einfügen. Die Verwendung dieses Tags hat die gleiche Wirkung wie:
-
Beenden eines Satzes mit einem Punkt (.)
-
Angeben einer Pause mit
<break strength="strong"/>
Im Unterschied zum Tag <break> schließt das Tag <s> den Satz ein. Das ist beim Generieren von Sprachausgabe nützlich, deren Eingabetext zeilen- statt satzweise angeordnet ist, also beispielsweise bei Gedichten.
Im folgenden Beispiel sorgt das Tag <s> für eine kurze Pause nach dem ersten und zweiten Satz. Der letzte Satz hat kein <s>-Tag. Es folgt aber trotzdem eine kurze Pause, weil er mit einem Punkt endet.
<speak> <s>Mary had a little lamb</s> <s>Whose fleece was white as snow</s> And everywhere that Mary went, the lamb was sure to go. </speak>
Steuern, wie spezielle Worttypen gesprochen werden
<say-as>
Mit Ausnahme der characters Option wird das <say-as> Tag von Langform-, neuronalen und Standard-TSS-Formaten unterstützt. Beachten Sie, dass der betroffene Satz mit der zugehörigen Standardstimme synthetisiert wird, wenn Amazon Polly eine neuronale Stimme verwendet und auf das <say-as> Tag mit der characters Option zur Laufzeit trifft. Der betroffene Satz wird jedoch weiterhin so abgerechnet, als ob er eine neuronale Stimme verwendet.
Verwenden Sie das <say-as> Tag mit dem interpret-as Attribut , um Amazon Polly mitzuteilen, wie bestimmte Zeichen, Wörter und Zahlen gesagt werden sollen. Auf diese Weise können Sie zusätzlichen Kontext bereitstellen, um Mehrdeutigkeiten darüber zu vermeiden, wie Amazon Polly den Text rendern soll.
Das <say-as> Tag verwendet ein Attribut, interpret-as, das eine Reihe möglicher verfügbarer Werte verwendet. Jeder dieser Werte verwendet die gleiche Syntax:
<say-as interpret-as="value">[text to be interpreted]</say-as>Die folgenden Werte können mit interpret-as verwendet werden:
-
charactersoderspell-out: Schreibt jeden Buchstaben des Textes wie in a-b-c.Anmerkung
Diese Option wird derzeit für neuronale Stimmen nicht unterstützt. Wenn Sie eine neuronale Stimme verwenden und dieser SSML-Code zur Laufzeit von Amazon Polly gefunden wird, wird der betroffene Satz mit der zugehörigen Standardstimme synthetisiert. Bitte beachten Sie jedoch, dass dieser Satz weiterhin so abgerechnet wird, als ob er eine neuronale Stimme verwendet.
-
cardinalodernumber: Interpretiert den numerischen Text als Kardinalzahl (z. B. 1.234). -
ordinal: Interpretiert den numerischen Text als Ordnungszahl (z. B. 1.234). -
digits: Spricht jede Ziffer einzeln (wie in 1-2-3-4). -
fraction: Interpretiert numerischen Text als Bruch. Dies funktioniert sowohl für gemeine Brüche wie 3/20 als auch für gemischte Brüche wie 2 ½. Weitere Informationen hierzu finden Sie unten. -
unit: Interpretiert einen numerischen Text als Messwert. Der Wert sollte eine Zahl oder ein Bruch gefolgt von einer Einheit ohne Leerstelle wie in1/2inchoder nur eine Einheit wie in1metersein. -
date: Interpretiert den Text als Datum. Das Datumsformat muss durch das Formatattribut festgelegt werden. Weitere Informationen hierzu finden Sie unten. -
time: interpretiert den numerischen Text als Dauer in Minuten und Sekunden (z. B.1'21"). -
address: Interpretiert den Text als Teil einer Angabe von Straße und Hausnummer. -
expletive: Der im Tag eingeschlossene Inhalt wird durch einen Piepton überdeckt. -
telephone: Interpretiert den numerischen Text als sieben- oder zehnstellige Telefonnummer, z. B.2025551212. Sie können diesen Wert auch für Nebenstellen wie in2025551212x345verwenden. Weitere Informationen hierzu finden Sie unten.Anmerkung
Derzeit ist die Option
telephonenicht für alle Sprachen verfügbar. Sie ist jedoch für Stimmen verfügbar, die englische Sprachvarianten (en-AU, en-GB, en-IN, en-US und en-GB-WLS), spanische Sprachvarianten (es-ES, es-MX und es-US), französische Sprachvarianten (fr-FR und fr-CA) und portugiesische Varianten (pt-BR und pt-PT) sowie Deutsch (de-DE), Italienisch (it-IT), Japanisch (ja-JP) und Russisch (ru-RU) sprechen. Es sollte auch beachtet werden, dass in einigen Fällen Sprachen wie Arabisch (arb) die eingestellte Nummer automatisch als Telefonnummer verarbeiten und daher das SSML-Tagtelephonenicht tatsächlich implementieren.
Bruchzahlen
Amazon Polly interpretiert Werte innerhalb des say-as Tags, die das interpret-as="fraction" Attribut haben, als gemeinsame Bruchteile. Im Folgenden wird die Syntax für Bruchzahlen beschrieben.
-
Bruchzahlen
Syntax:
Kardinalzahl/Kardinalzahlwie 2/9.Beispiel:
<say-as interpret-as="fraction">2/9</say-as>wird ausgesprochen als "two ninth". -
Nicht negative gemischte Nummer
Syntax:
Kardinalzahl+Kardinalzahl/Kardinalzahl, z. B. 3+1/2.Beispiel:
<say-as interpret-as="fraction">3+1/2</say-as>wird ausgesprochen als "three and a half".Anmerkung
Zwischen
+dem „3“ und dem „1/2“ muss sich ein befinden. Amazon Polly unterstützt keine gemischte Zahl ohne die+, z. B. „3 1/2“.
Datumsangaben
Wenn interpret-as auf date gesetzt ist, müssen Sie auch das Datumsformat angeben.
Für dieses Tag gilt folgende Syntax:
<say-as interpret-as="date" format="format">[date]</say-as>
Beispielsweise:
<speak> I was born on <say-as interpret-as="date" format="mdy">12-31-1900</say-as>. </speak>
Die folgenden Formate können für das Attribut date angegeben werden.
-
mdy: M onth-day-year. -
dmy: D ay-month-year. -
ymd: Y ear-month-day. -
md: Monat-Tag. -
dm: Tag-Monat. -
ym: Jahr-Monat. -
my: Monat-Jahr. -
d: Tag. -
m: Monat. -
y: Jahr. -
yyyymmdd: Y ear-month-day. Wenn Sie dieses Format verwenden, können Sie Amazon Polly mithilfe von Fragezeichen Teile des Datums überspringen.Amazon Polly rendert beispielsweise Folgendes als „22. September“:
<say-as interpret-as="date">????0922</say-as>Formatist nicht erforderlich.
Telefonnummer
Amazon Polly versucht, den von Ihnen bereitgestellten Text auf der Grundlage der Formatierung des Textes auch ohne das -<say-as>Tag korrekt zu interpretieren. Wenn Ihr Text beispielsweise „202-555-1212“ enthält, interpretiert Amazon Polly ihn als 10-stellige Telefonnummer und gibt jede Ziffer einzeln an, mit einer kurzen Pause für jeden Bindestrich. In diesem Fall müssen Sie <say-as interpret-as="telephone"> nicht verwenden. Wenn Sie jedoch den Text „2025551212“ angeben und möchten, dass Amazon Polly ihn als Telefonnummer angibt, würden Sie angeben<say-as interpret-as="telephone">.
Die Logik zur Interpretation der einzelnen Elemente ist sprachspezifisch. Die Aussprache von Telefonnummern unterscheidet sich beispielsweise zwischen US-amerikanischem und britischem Englisch (in Großbritannien werden aufeinanderfolgende gleiche Ziffern zusammengefasst, z. B. "double five" oder "triple four"). Sie können das folgende Beispiel mit einer US-amerikanischen und einer britischen Stimme testen, um den Unterschied zu hören:
<speak> Richard's number is <say-as interpret-as="telephone">2122241555</say-as> </speak>
Verkürzen von Akronymen und Abkürzungen
<sub>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Verwenden Sie das <sub>-Tag mit dem alias-Attribut, um gewählten Text – z. B. ein Akronym oder eine Abkürzung – durch ein anderes Wort (oder eine andere Aussprache) zu ersetzen.
Es gilt folgende Syntax:
<sub alias="new word">abbreviation</sub>Im folgenden Beispiel wird der Name "Mercury" anstelle des chemischen Symbols für das Element gesprochen, um den Audioinhalt verständlicher zu machen.
<speak> My favorite chemical element is <sub alias="Mercury">Hg</sub>, because it looks so shiny. </speak>
Verbesserung der Aussprache durch Angabe von Sprachteilen
<w>
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Sie können das Tag <w> verwenden, um die Aussprache von Wörtern anzupassen, indem Sie die Wortart oder eine alternative Bedeutung angeben. Dies erfolgt mithilfe des Attributs role.
Dieses Tag verwendet folgende Syntax:
<w role="attribute">text</w>Folgende Werte können für das Attribut role angegeben werden:
So geben Sie die Wortart an:
-
amazon:VB: Das Wort wird als Verb (in der Gegenwartsform) interpretiert. -
amazon:VBD: interpretiert das Wort als vergangenes Tense-Verb. -
amazon:DT: interpretiert das Wort als Bestimmter. -
amazon:IN: interpretiert das Wort als Präposition. -
amazon:JJ: interpretiert das Wort als Adjectiv. -
amazon:NN: interpretiert das Wort als Substantiv.
Beispiel: Je nach Wortart variiert die Aussprache des Wortes „read“ im US-Englischen in Abhängigkeit vom Tag:
<speak> The word <say-as interpret-as="characters">read</say-as> may be interpreted as either the present simple form <w role="amazon:VB">read</w>, or the past participle form <w role="amazon:VBD">read</w>. </speak>
So geben Sie eine bestimmte Bedeutung an:
-
amazon:DEFAULT: verwendet das Standardbild des Wortes. -
amazon:SENSE_1: Der nicht standardmäßige Wortsinn wird verwendet (sofern vorhanden). Beispiel: Das Substantiv „bass“ wird je nach Bedeutung anders ausgesprochen. Die Standardbedeutung ist die tiefste Tonlage in der Musik. Die alternative Bedeutung ist eine Spezies von Süßwasserfischen, die auch als „bass“ bezeichnet, aber anders ausgesprochen wird. Durch<w role="amazon:SENSE_1">bass</w>wird in der Sprachausgabe die nichtstandardmäßige Aussprache (für den Süßwasserfisch) verwendet.
Dieser Unterschied in Aussprache und Bedeutung kann er hören, wenn Sie Folgendes synthetisieren:
<speak> Depending on your meaning, the word <say-as interpret-as="characters">bass</say-as> may be interpreted as either a musical element: bass, or as its alternative meaning, a freshwater fish <w role="amazon:SENSE_1">bass</w>. </speak>
Anmerkung
Einige Sprachen weisen möglicherweise eine andere Auswahl unterstützter Sprachelemente auf.
Hinzufügen des Sounds von Telefonie
<amazon:breath> und <amazon:auto-breaths>
Dieses Tag wird nur vom Standard-TTS-Format unterstützt.
Natürlich klingende Sprache besteht aus richtig gesprochenen Wörtern und Atemgeräuschen. Wenn Sie der synthetisierten Sprachausgabe Atemgeräusche hinzufügen, klingt sie natürlicher. Die Tags <amazon:breath> und <amazon:auto-breaths> stellen Atemgeräusche bereit. Ihnen stehen folgende Optionen zur Verfügung:
-
Manueller Modus: Sie legen Position, Dauer und Lautstärke des Atemgeräusches im Text fest
-
Automatisierter Modus: Amazon Polly fügt automatisch störende Laute in die Sprachausgabe ein
-
Gemischter Modus: Sowohl Sie als auch Amazon Polly fügen Trichterrauschen hinzu
Manueller Modus
Im manuellen Modus platzieren Sie das Tag <amazon:breath/> im Eingabetext an der Stelle, an der das Atemgeräusch hörbar werden soll. Sie können Dauer und Lautstärke des Atemgeräusches mit den Attributen duration und volume festlegen:
-
duration: Legt die Dauer des Atemgeräusches fest. Folgende Werte sind zulässig:default,x-short,short,medium,long,x-long. Der Standardwert istmedium. -
volume: Legt die Lautstärke des Atemgeräusches fest. Folgende Werte sind zulässig:default,x-soft,soft,medium,loud,x-loud. Der Standardwert istmedium.
Anmerkung
Die genaue Länge und das Volumen der einzelnen Attributwerte hängen von der spezifischen verwendeten Amazon Polly-Stimme ab.
Sie können ein Atemgeräusch mit Standardwerten festlegen, indem Sie <amazon:breath/> ohne Attribute verwenden.
Um beispielsweise Dauer und Lautstärke eines Atemgeräusches mit Attributen festzulegen, verwenden Sie folgende Attributwerte:
<speak> Sometimes you want to insert only <amazon:breath duration="medium" volume="x-loud"/>a single breath. </speak>
Für ein Atemgeräusch mit Standardwerten verwenden Sie einfach das Tag:
<speak> Sometimes you need <amazon:breath/>to insert one or more average breaths <amazon:breath/> so that the text sounds correct. </speak>
Sie können folgendermaßen Atemgeräusche in eine Textpassage einfügen:
<speak> <amazon:breath duration="long" volume="x-loud"/> <prosody rate="120%"> <prosody volume="loud"> Wow! <amazon:breath duration="long" volume="loud"/> </prosody> That was quite fast. <amazon:breath duration="medium" volume="x-loud"/> I almost beat my personal best time on this track. </prosody> </speak>
Automatischer Modus
Im automatisierten Modus verwenden Sie das -<amazon:auto-breaths>Tag, um Amazon Polly anzuweisen, in geeigneten Intervallen automatisch Rauschen zu erzeugen. Sie können die Häufigkeit der Intervalle sowie Lautstärke und Dauer einstellen. Platzieren Sie das Tag </amazon:auto-breaths> am Anfang und das entsprechende schließende Tag am Ende des Textes, für den Sie automatisierte Atemgeräusche generieren möchten.
Anmerkung
Im Unterschied zum Tag <amazon:breath/> für den manuellen Modus ist für <amazon:auto-breaths> ein schließendes Tag (</amazon:auto-breaths>) erforderlich.
Sie können die folgenden optionalen Attribute mit dem Tag <amazon:auto-breaths> verwenden:
-
volume: Legt die Lautstärke der Atemgeräusche fest. Folgende Werte sind zulässig:default,x-soft,soft,medium,loud,x-loud. Der Standardwert istmedium. -
frequency: Steuert, wie oft Atemgeräusche im Text generiert werden. Folgende Werte sind zulässig:default,x-low,low,medium,high,x-high. Der Standardwert istmedium. -
duration: Legt die Dauer des Atemgeräusches fest. Folgende Werte sind zulässig:default,x-short,short,medium,long,x-long. Der Standardwert istmedium.
Standardmäßig hängt die Häufigkeit der Atemgeräusche vom Eingabetext ab. Atemgeräusche treten häufig nach Kommas und Punkten auf.
Die folgenden Beispiele demonstrieren die Verwendung des Tags <amazon:auto-breaths>. Um zu entscheiden, welche Optionen für Ihre Inhalte verwendet werden sollen, kopieren Sie die entsprechenden Beispiele in die Amazon Polly-Konsole und hören Sie sich die Unterschiede an.
-
Automatischer Modus ohne optionale Parameter
<speak> <amazon:auto-breaths>Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech- enabled products. Amazon Polly is a text-to-speech service that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Automatischer Modus mit Lautstärkeregelung: Für nicht angegebene Parameter (
durationundfrequency) werden die Standardwerte (medium) verwendet.<speak> <amazon:auto-breaths volume="x-soft">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Automatischer Modus mit Häufigkeitsregelung: Für nicht angegebene Parameter (
durationundvolume) werden die Standardwerte (medium) verwendet.<speak> <amazon:auto-breaths frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
Automatischer Modus mit mehreren Parametern: Für den nicht angegebenen
DurationParameter verwendet Amazon Polly den Standardwert (medium).<speak> <amazon:auto-breaths volume="x-loud" frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech-enabled applications that work in many different countries.</amazon:auto-breaths> </speak>
Sprechstil von Newscaster
<amazon:domain name="news">
Der Nachrichtensender-Stil ist nur für die Matthew- oder Joanna-Stimmen verfügbar, die nur in amerikanischem Englisch (en-US), Lupe in US-Spanisch (es-US) und Amy in englischem Englisch (en-GB) verfügbar sind. Er wird nur für das Format Neural unterstützt.
Um den Newscaster-Stil zu verwenden, verwenden Sie SSML-Tags und die folgende Syntax:
<amazon:domain name="news">text</amazon:domain>
Sie können beispielsweise den Nachrichtensender-Stil mit der Amy-Stimme wie folgt verwenden:
<speak> <amazon:domain name="news"> From the Tuesday, April 16th, 1912 edition of The Guardian newspaper: The maiden voyage of the White Star liner Titanic, the largest ship ever launched, has ended in disaster. The Titanic started her trip from Southampton for New York on Wednesday. Late on Sunday night she struck an iceberg off the Grand Banks of Newfoundland. By wireless telegraphy she sent out signals of distress, and several liners were near enough to catch and respond to the call. </amazon:domain> </speak>
Hinzufügen der dynamischen Bereichskomprimierung
<amazon:effect name="drc">
Dieses Tag wird von Langform-, neuronalen und Standard-TTS-Formaten unterstützt.
Je nach dem in einer Audiodatei verwendeten Text, der Sprache und der Stimme reichen die Töne von leise bis laut. Umgebungsgeräusche, wie z. B. der Klang eines sich bewegenden Fahrzeugs, können oft die leisen Töne überdecken, wodurch die Audiospur schwer zu hören ist. Um die Lautstärke bestimmter Sounds in Ihrer Audiodatei zu erhöhen, verwenden Sie den Tag für die Dynamikbereichkomprimierung (drc).
Das drc-Tag stellt einen mittleren „Lautstärke“-Schwellenwert für Ihr Audiomaterial ein und erhöht die Lautstärke (die Verstärkung) der Sounds um diesen Schwellenwert. Es wendet die größte Verstärkungszunahme an, die dem Schwellenwert am nächsten ist, und die Verstärkungszunahme wird weiter weg vom Schwellenwert verringert.
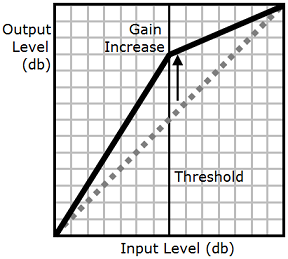
Dadurch werden die Klänge des mittleren Bereichs in einer geräuschvollen Umgebung besser hörbar, wodurch die gesamte Audiodatei klarer wird.
Der drc-Tag ist ein boolescher Parameter (entweder vorhanden oder nicht). Es verwendet die Syntax: <amazon:effect name="drc"> und wird mit </amazon:effect> geschlossen.
Sie können das -drcTag mit jeder von Amazon Polly unterstützten Sprache verwenden. Sie können es auf einen ganzen Abschnitt der Aufnahme oder nur für einige Wörter anwenden. Beispielsweise:
<speak> Some audio is difficult to hear in a moving vehicle, but <amazon:effect name="drc"> this audio is less difficult to hear in a moving vehicle.</amazon:effect> </speak>
Anmerkung
Wenn Sie „drc“ in der amazon:effect
-Syntax verwenden, wird die Groß-/Kleinschreibung beachtet.
Verwenden von drc mit dem prosody
volume-Tag
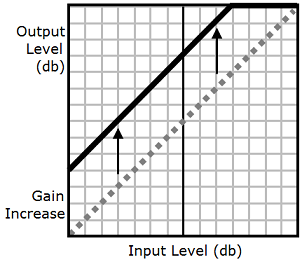
Wie die folgende Grafik zeigt, erhöht der Tag prosody
volume die Lautstärke einer gesamten Audiodatei gleichmäßig vom ursprünglichen Level (gepunktete Linie) auf einen angepassten Level (durchgezogene Linie). Um die Lautstärke bestimmter Teile der Datei weiter erhöhen, verwenden Sie den drc-Tag mit dem prosody
volume-Tag. Die Kombination von Tags hat keine Auswirkungen auf die Einstellungen des Tags prosody volume.
Wenn Sie die prosody volume Tags drc und zusammen verwenden, wendet Amazon Polly zuerst das drc Tag an und erhöht so die Laute im mittleren Bereich (diejenigen nahe dem Schwellenwert). Dann wendet es den Tag prosody volume an und erhöht die Lautstärke der gesamten Audiospur weiter gleichmäßig.
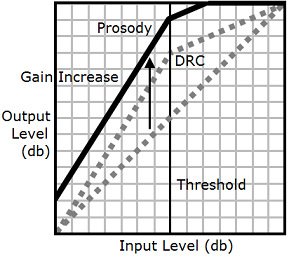
Um die Tags zusammen zu verwenden, verschachteln Sie sie ineinander. Beispielsweise:
<speak> <prosody volume="loud">This text needs to be understandable and loud. <amazon:effect name="drc"> This text also needs to be more understandable in a moving car.</amazon:effect></prosody> </speak>
In diesem Text erhöht der Tag prosody volume die Lautstärke der gesamten Passage auf „laut“- Der Tag drc erhöht die Lautstärke der Mittelwerte im zweiten Satz.
Anmerkung
Wenn Sie die Tags drc und prosody
volume zusammen verwenden, verwenden Sie XML-Standardpraktiken zum Verschachteln von Tags.
Soft sprechen
<amazon:effect phonation="soft">
Dieses Tag wird derzeit nur vom Standard-TTS-Format unterstützt.
Um anzugeben, dass der Eingabetext in einer softer-than-normal Stimme gesprochen werden soll, verwenden Sie das Tag <amazon:effektive Telefonie="soft>.
Es gilt folgende Syntax:
<amazon:effect phonation="soft">text</amazon:effect>Sie können dieses Tag beispielsweise folgendermaßen mit der Stimme Matthew verwenden:
<speak> This is Matthew speaking in my normal voice. <amazon:effect phonation="soft">This is Matthew speaking in my softer voice.</amazon:effect> </speak>
Steuern von timbre
<amazon:Auswirkung vocal-tract-length>
Dieses Tag wird derzeit nur vom Standard-TTS-Format unterstützt.
Timbre ist die Klangqualität einer Stimme, mit der Sie den Unterschied zwischen Stimmen erkennen können, selbst wenn sie die gleiche Tonhöhe und Lautstärke haben. Eine der wichtigsten physiologischen Eigenschaften, die zur Sprachtimbre beiträgt, ist die Länge des Vokaltraktes. Der Vokaltrakt ist eine Lufthöhle, die sich von der Oberseite der Stimmfalten bis zum Rand der Lippen erstreckt.
Verwenden Sie das -vocal-tract-lengthTag, um den Takt der Ausgabesprache in Amazon Polly zu steuern. Dieser Tag hat die Wirkung, die Länge des Vokaltrakts des Sprechers zu verändern, was wie eine Änderung der Sprechergröße klingt. Wenn Sie die vocal-tract-lengtherhöhen, klingt der Sprecher physikalisch größer. Wenn Sie es verringern, klingt der Sprecher kleiner. Sie können dieses Tag mit jeder der Stimmen im Text-to-Speech-Portfolio von Amazon Polly verwenden.
Verwenden Sie die folgenden Werte, um das Timbre zu ändern:
-
+n%oder-n%: Passt die Vokaltraktlänge um einen relativen Prozentsatz der derzeit verwendeten Stimme an. Beispiel: +4 % oder -2 %. Gültige Werte liegen zwischen 100 % und -50 %. Werte außerhalb dieses Bereichs werden abgeschnitten. Zum Beispiel klingt +111 % wie +100 % und -60 % klingt wie -50 %. -
n%: Ändert die Länge des Vokaltrakts auf einen absoluten Prozentsatz der Länge der aktuellen Stimme. Zum Beispiel 110 % oder 75 %. Ein absoluter Wert von 110 % entspricht einem relativen Wert von +10 %. Ein absoluter Wert von 100 % entspricht dem Standardwert für die aktuelle Stimme.
Das folgende Beispiel zeigt, wie die Länge des Vokaltrakts geändert wird, um das Timbre zu ändern:
<speak> This is my original voice, without any modifications. <amazon:effect vocal-tract-length="+15%"> Now, imagine that I am much bigger. </amazon:effect> <amazon:effect vocal-tract-length="-15%"> Or, perhaps you prefer my voice when I'm very small. </amazon:effect> You can also control the timbre of my voice by making minor adjustments. <amazon:effect vocal-tract-length="+10%"> For example, by making me sound just a little bigger. </amazon:effect><amazon:effect vocal-tract-length="-10%"> Or, making me sound only somewhat smaller. </amazon:effect> </speak>
Kombinieren von mehreren Tags
Sie können das vocal-tract-length Tag mit jedem anderen SSML-Tag kombinieren, das von Amazon Polly unterstützt wird. Da Timbre (Vokaltraktlänge) und Tonhöhe eng miteinander verbunden sind, können Sie die besten Ergebnisse erzielen, wenn Sie sowohl den vocal-tract-length als auch den <prosody
pitch>-Tag verwenden. Um die realistischste Stimme zu erzeugen, empfehlen wir Ihnen, unterschiedliche Prozentsätze der Änderungen für die beiden Tags zu verwenden. Experimentieren Sie mit verschiedenen Kombinationen, um die gewünschten Ergebnisse zu erzielen.
Das folgende Beispiel zeigt, wie Tags kombiniert werden.
<speak> The pitch and timbre of a person's voice are connected in human speech. <amazon:effect vocal-tract-length="-15%"> If you are going to reduce the vocal tract length, </amazon:effect><amazon:effect vocal-tract-length="-15%"> <prosody pitch="+20%"> you might consider increasing the pitch, too. </prosody></amazon:effect> <amazon:effect vocal-tract-length="+15%"> If you choose to lengthen the vocal tract, </amazon:effect> <amazon:effect vocal-tract-length="+15%"> <prosody pitch="-10%"> you might also want to lower the pitch. </prosody></amazon:effect> </speak>
Flüstern
<amazon:effect name="whispered">
Dieses Tag wird derzeit nur vom Standard-TTS-Format unterstützt.
Dieses Tag gibt an, dass der Eingabetext nicht normal gesprochen, sondern geflüstert werden soll. Dies kann mit jeder der Stimmen im Text-to-Speech-Portfolio von Amazon Polly verwendet werden.
Für dieses Tag gilt folgende Syntax:
<amazon:effect name="whispered">text</amazon:effect>Beispielsweise:
<speak> <amazon:effect name="whispered">If you make any noise, </amazon:effect> she said, <amazon:effect name="whispered">they will hear us.</amazon:effect> </speak>
In diesem Fall wird die vom Zeichen gesprochene synthetisierte Sprache Whispered, aber der Satz „sie hat gesagt“ wird in der normalen synthetisierten Sprache der ausgewählten Amazon Polly-Stimme gesprochen.
Sie können den „Flüstereffekt“ noch verstärken, indem Sie den Satzrhythmus je nach Belieben um bis zu 10 % verlangsamen.
Beispielsweise:
<speak> When any voice is made to whisper, <amazon:effect name="whispered"> <prosody rate="-10%">the sound is slower and quieter than normal speech </prosody></amazon:effect> </speak>
Beim Erstellen der Sprachmarkierungen für eine Flüsterstimme muss der Audiostream diese ebenfalls enthalten, um sicherzustellen, dass die Sprachmarkierungen zum Audiostream passen.
