Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Pflege von Tabellen mithilfe von Komprimierung
Iceberg enthält Funktionen, mit denen Sie Tabellenverwaltungsoperationen durchführen können, nachdem Sie Daten in die Tabelle
Verdichtung von Eisbergen
In Iceberg können Sie die Komprimierung verwenden, um vier Aufgaben auszuführen:
-
Kombinieren kleiner Dateien zu größeren Dateien, die in der Regel über 100 MB groß sind. Diese Technik wird als Mülltonnenverpackung bezeichnet.
-
Zusammenführen von gelöschten Dateien mit Datendateien. Löschdateien werden durch Aktualisierungen oder Löschungen generiert, die diesen Ansatz verwenden. merge-on-read
-
(Neu-) Sortierung der Daten gemäß Abfragemustern. Daten können ohne jegliche Sortierreihenfolge oder mit einer Sortierreihenfolge geschrieben werden, die für Schreibvorgänge und Aktualisierungen geeignet ist.
-
Clustering der Daten mithilfe von raumfüllenden Kurven zur Optimierung für unterschiedliche Abfragemuster, insbesondere für die Sortierung in Z-Reihenfolge.
Auf AWS, können Sie Tabellenkomprimierungs- und Wartungsvorgänge für Iceberg über Amazon Athena oder mithilfe von Spark in Amazon EMR oder ausführen. AWS Glue
Wenn Sie die Komprimierung mithilfe der Prozedur rewrite_data_files
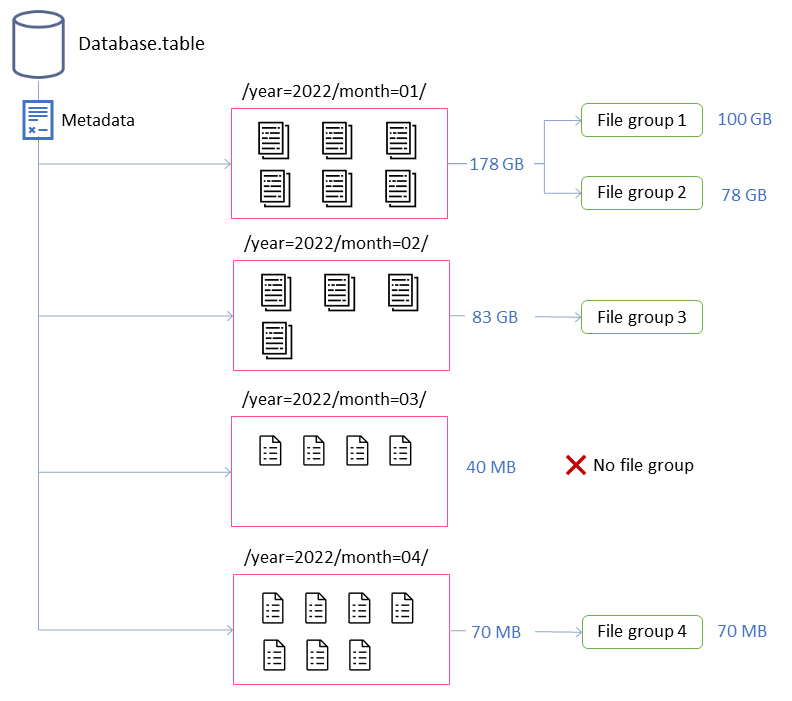
In diesem Beispiel besteht die Iceberg-Tabelle aus vier Partitionen. Jede Partition hat eine andere Größe und eine unterschiedliche Anzahl von Dateien. Wenn Sie eine Spark-Anwendung starten, um die Komprimierung auszuführen, erstellt die Anwendung insgesamt vier Dateigruppen zur Verarbeitung. Eine Dateigruppe ist eine Iceberg-Abstraktion, die eine Sammlung von Dateien darstellt, die von einem einzelnen Spark-Job verarbeitet werden. Das heißt, die Spark-Anwendung, die die Komprimierung ausführt, erstellt vier Spark-Jobs zur Verarbeitung der Daten.
Optimieren des Verdichtungsverhaltens
Die folgenden wichtigen Eigenschaften steuern, wie Datendateien für die Komprimierung ausgewählt werden:
-
MAX_FILE_GROUP_SIZE_BYTES
legt das Datenlimit für eine einzelne Dateigruppe (Spark-Job) standardmäßig auf 100 GB fest. Diese Eigenschaft ist besonders wichtig für Tabellen ohne Partitionen oder Tabellen mit Partitionen, die sich über Hunderte von Gigabyte erstrecken. Wenn Sie dieses Limit festlegen, können Sie die Abläufe unterteilen, um die Arbeit zu planen und Fortschritte zu erzielen, und gleichzeitig eine Erschöpfung der Ressourcen im Cluster verhindern. Hinweis: Jede Dateigruppe ist separat sortiert. Wenn Sie also eine Sortierung auf Partitionsebene durchführen möchten, müssen Sie dieses Limit an die Partitionsgröße anpassen.
-
MIN_FILE_SIZE_BYTES oder MIN_FILE_SIZE_DEFAULT_RATIO
sind standardmäßig auf 75 Prozent der auf Tabellenebene festgelegten Zieldateigröße eingestellt. Wenn eine Tabelle beispielsweise eine Zielgröße von 512 MB hat, ist jede Datei, die kleiner als 384 MB ist, in der Gruppe der zu komprimierenden Dateien enthalten. -
MAX_FILE_SIZE_BYTES oder MAX_FILE_SIZE_DEFAULT_RATIO
sind standardmäßig auf 180 Prozent der Zieldateigröße eingestellt . Wie bei den beiden Eigenschaften, die Mindestdateigrößen festlegen, werden diese Eigenschaften verwendet, um Kandidatendateien für den Komprimierungsauftrag zu identifizieren. -
MIN_INPUT_FILES
gibt die Mindestanzahl der zu komprimierenden Dateien an, wenn die Größe einer Tabellenpartition kleiner als die Zieldateigröße ist. Der Wert dieser Eigenschaft wird verwendet, um zu bestimmen, ob es sich lohnt, die Dateien anhand der Anzahl der Dateien zu komprimieren (der Standardwert ist 5). -
DELETE_FILE_THRESHOLD
gibt die Mindestanzahl von Löschvorgängen für eine Datei an, bevor sie in die Komprimierung aufgenommen wird. Sofern Sie nichts anderes angeben, werden bei der Komprimierung keine Löschdateien mit Datendateien kombiniert. Um diese Funktion zu aktivieren, müssen Sie mithilfe dieser Eigenschaft einen Schwellenwert festlegen. Dieser Schwellenwert ist spezifisch für einzelne Datendateien. Wenn Sie ihn also auf 3 setzen, wird eine Datendatei nur dann neu geschrieben, wenn drei oder mehr Löschdateien darauf verweisen.
Diese Eigenschaften geben Aufschluss über die Bildung der Dateigruppen im vorherigen Diagramm.
Die beschriftete Partition month=01 umfasst beispielsweise zwei Dateigruppen, da sie die maximale Größenbeschränkung von 100 GB überschreitet. Im Gegensatz dazu enthält die month=02 Partition eine einzelne Dateigruppe, da sie weniger als 100 GB groß ist. Die month=03 Partition erfüllt nicht die standardmäßige Mindestanforderung für Eingabedateien von fünf Dateien. Infolgedessen wird sie nicht komprimiert. Schließlich enthält die month=04 Partition zwar nicht genügend Daten, um eine einzelne Datei mit der gewünschten Größe zu bilden, die Dateien werden jedoch komprimiert, da die Partition mehr als fünf kleine Dateien enthält.
Sie können diese Parameter für Spark festlegen, der auf Amazon EMR oder AWS Glue ausgeführt wird. Für Amazon Athena können Sie ähnliche Eigenschaften verwalten, indem Sie die Tabelleneigenschaften verwenden, die mit dem Präfix beginnenoptimize_).
Verdichtung mit Spark auf Amazon EMR ausführen oder AWS Glue
In diesem Abschnitt wird beschrieben, wie Sie einen Spark-Cluster richtig dimensionieren, um das Komprimierungsprogramm von Iceberg auszuführen. Im folgenden Beispiel wird Amazon EMR Serverless verwendet, aber Sie können dieselbe Methode in Amazon EMR on Amazon EC2 oder Amazon EKS oder in verwenden. AWS Glue
Sie können die Korrelation zwischen Dateigruppen und Spark-Jobs nutzen, um die Cluster-Ressourcen zu planen. Um die Dateigruppen sequentiell zu verarbeiten und dabei die maximale Größe von 100 GB pro Dateigruppe zu berücksichtigen, können Sie die folgenden Spark-Eigenschaften festlegen:
-
spark.dynamicAllocation.enabled=FALSE -
spark.executor.memory=20 GB -
spark.executor.instances=5
Wenn Sie die Komprimierung beschleunigen möchten, können Sie horizontal skalieren, indem Sie die Anzahl der Dateigruppen erhöhen, die parallel komprimiert werden. Sie können Amazon EMR auch mithilfe manueller oder dynamischer Skalierung skalieren.
-
Manuelles Skalieren (z. B. um den Faktor 4)
-
MAX_CONCURRENT_FILE_GROUP_REWRITES=4(unser Faktor) -
spark.executor.instances=5(im Beispiel verwendeter Wert) x4(unser Faktor) =20 -
spark.dynamicAllocation.enabled=FALSE
-
-
Dynamische Skalierung
-
spark.dynamicAllocation.enabled=TRUE(Standard, keine Aktion erforderlich) -
MAX_CONCURRENT_FILE_GROUP_REWRITES =
N(richten Sie diesen Wert anspark.dynamicAllocation.maxExecutors, der standardmäßig 100 ist; basierend auf den Executor-Konfigurationen im Beispiel können Sie ihn auf 20 setzen)N
Dies sind Richtlinien zur Unterstützung der Clustergröße. Sie sollten jedoch auch die Leistung Ihrer Spark-Jobs überwachen, um die besten Einstellungen für Ihre Workloads zu finden.
-
Verdichtung mit Amazon Athena ausführen
Athena bietet eine Implementierung des Verdichtungsprogramms von Iceberg als verwaltete Funktion über die OPTIMIZE-Anweisung an. Sie können diese Anweisung verwenden, um die Komprimierung auszuführen, ohne die Infrastruktur auswerten zu müssen.
Diese Anweisung gruppiert kleine Dateien mithilfe des Bin-Packing-Algorithmus zu größeren Dateien und führt gelöschte Dateien mit vorhandenen Datendateien zusammen. Um die Daten mithilfe von hierarchischer Sortierung oder Sortierung in Z-Reihenfolge zu clustern, verwenden Sie Spark auf Amazon EMR oder. AWS Glue
Sie können das Standardverhalten der OPTIMIZE Anweisung bei der Tabellenerstellung ändern, indem Sie Tabelleneigenschaften in der CREATE TABLE Anweisung übergeben, oder nach der Tabellenerstellung, indem Sie die Anweisung verwenden. ALTER TABLE Standardwerte finden Sie in der Athena-Dokumentation.
Empfehlungen für die Ausführung der Komprimierung
Anwendungsfall |
Empfehlung |
|---|---|
Die Komprimierung von Bin Packing wird nach einem Zeitplan ausgeführt |
|
Die Bin-Packing-Komprimierung wird auf der Grundlage von Ereignissen ausgeführt |
|
Komprimierung zum Sortieren von Daten ausführen |
|
Führen Sie die Komprimierung aus, um die Daten mithilfe der Sortierung in Z-Reihenfolge zu clustern |
|
Die Komprimierung wird auf Partitionen ausgeführt, die aufgrund spät eingehender Daten möglicherweise von anderen Anwendungen aktualisiert werden |
|
Ausführen der Komprimierung auf kalten Partitionen (Datenpartitionen, die keine aktiven Schreibvorgänge mehr empfangen) |
|
