Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Aurora-Zustände und Step Functions Functions-Zustandsmaschinen
In diesem Abschnitt werden die spezifischen Prozess- und Zustandsmaschinen für Failover und Failback von Amazon Aurora Aurora-Clustern behandelt. Die Cluster sind als globale Datenbank konfiguriert.
Anmerkung
Zu Demonstrationszwecken wird in diesem Beispiel die Aurora MySQL-Compatible Edition verwendet. Sie können ähnliche Schritte für Aurora PostgreSQL-Compatible Edition verwenden.
Stetiger Zustand
Im Steady-State wurde eine Amazon Aurora MySQL-kompatible globale Datenbank (dr-globaldb-cluster-mysql) mit zwei DB-Clustern erstellt. Der erste DB-Cluster (db-cluster-01) wurde in der Primärdatenbank (us-east-1) erstellt, um den AWS-Region
Lese-/Schreib-Workload zu bedienen. Der zweite DB-Cluster (db-cluster-02) wurde in der sekundären Region (us-west-2) erstellt, um den schreibgeschützten Workload zu verarbeiten.
Zusätzlich zur Bereitstellung der DR-Lösung können Sie die Belastung Ihres primären DB-Clusters reduzieren, indem Sie Leseanfragen von Ihren Anwendungen an den sekundären DB-Cluster weiterleiten. Jeder dieser Cluster enthält eine Datenbank-Instance namens dbcluster-01-use1-instance-1 unddbcluster-02-usw2-instance-2.
Status des Ereignisses
Durch die Verwendung einer globalen Amazon Aurora Aurora-Datenbank können Sie Katastrophen relativ schnell planen und wiederherstellen. Die Wiederherstellung nach einem Notfall wird in der Regel anhand von Werten für Recovery Time Objective (RTO) und Recovery Point Objective (RPO) gemessen. Weitere Informationen finden Sie unter Verwenden von Switchover oder Failover in einer globalen Amazon Aurora Aurora-Datenbank.
Bei einer globalen Aurora-Datenbank gibt es zwei verschiedene Ansätze für Failover:
-
Switchover (verwaltetes geplantes Failover)
-
Failover (manuelles, ungeplantes Failover oder Trennen und Heraufstufen)
Umstellung
Switchover ist für kontrollierte Umgebungen vorgesehen, z. B. für betriebliche Wartungsarbeiten und andere geplante Betriebsabläufe. Mithilfe eines verwalteten geplanten Failovers können Sie den primären DB-Cluster Ihrer globalen Aurora-Datenbank in eine der sekundären Regionen verlagern. Da Switchover wartet, bis die sekundären DB-Cluster mit der Primärdatenbank synchronisiert sind, ist RPO 0 (kein Datenverlust). Weitere Informationen finden Sie unter Durchführen von Switchovers für globale Amazon Aurora Aurora-Datenbanken.
Die dr-orchestrator-stepfunction-FAILOVER Zustandsmaschine wird während des Ereignisstatus aufgerufen, um Ihren primären Cluster in die von Ihnen gewählte sekundäre Region umzuschalten ()us-west-2.
Gehen Sie wie folgt vor, um den Switchover durchzuführen:
-
Melden Sie sich bei der AWS Management Console an.
-
Ändern Sie die Region in die DR-Region (
us-west-2). -
Navigieren Sie zu Services und wählen Sie Step Functions aus.
-
Navigieren Sie zur
dr-orchestrator-stepfunction-FAILOVERZustandsmaschine. -
Wählen Sie Ausführung starten und geben Sie den folgenden JSON-Code in den
Input - optionalAbschnitt ein:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
Die
dr-orchestrator-stepfunction-FAILOVERZustandsmaschine liest den Ressourcentyp alsPlannedFailoverAuroraMySQL und ruft diedr-orchestrator-stepfunction-planned-Aurora-failoverZustandsmaschine auf, um ein Failover für die globale Aurora-Datenbank durchzuführen.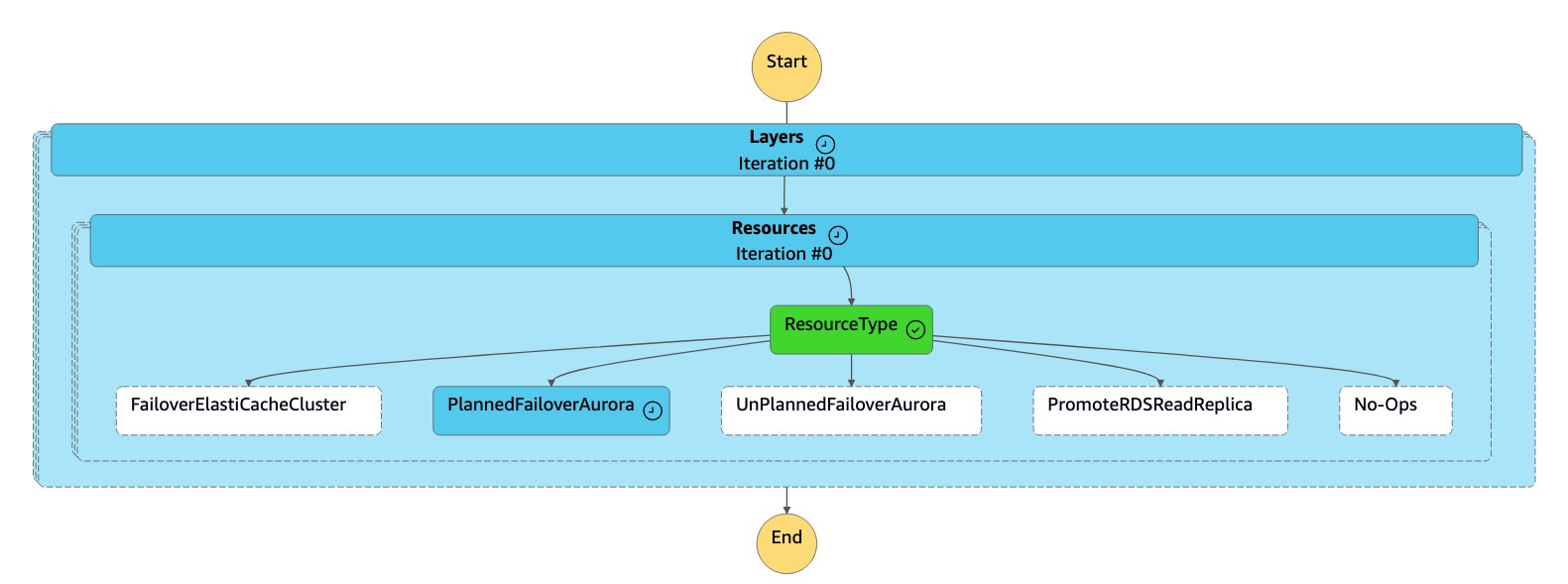
-
Die
dr-orchestrator-stepfunction-planned-Aurora-failoverState Machine führt die folgenden Schritte aus, um die Aurora MySQL-kompatible globale Datenbankrolle umzuschalten.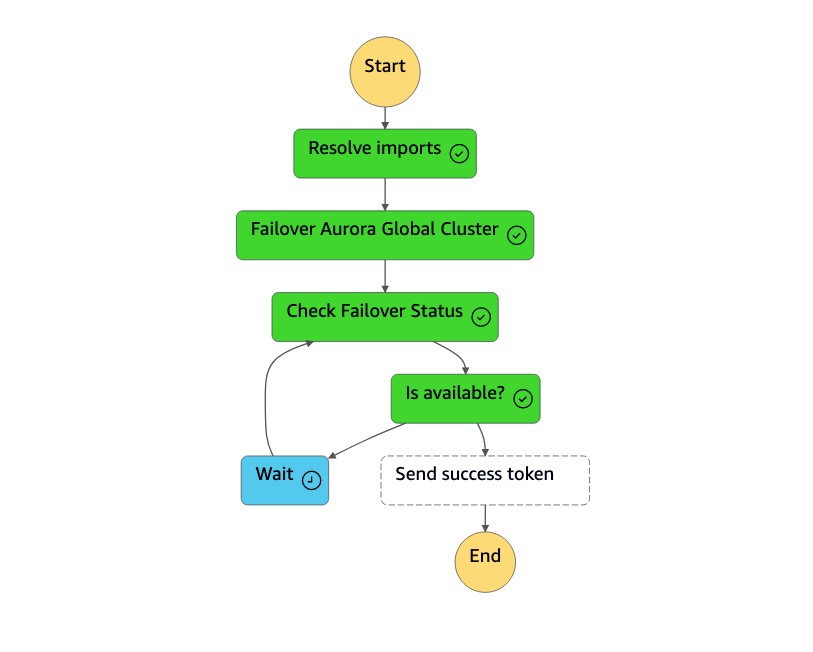
Schritt Beschreibung Erwartete Werte Importe lösen Eine Lambda-Funktion ersetzt !Import <variable name>Werte durch den tatsächlichen Namen."!Import dr-globaldb-cluster-mysql-global-identifier"wird ersetzt durch"dr-globaldb-cluster-mysql".Globaler Aurora-Failover-Cluster Eine Lambda-Funktion ruft die Boto3-APIs failover_global_cluster auf, um ein Failover für die globale Aurora-Datenbank durchzuführen. { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }Überprüfen Sie den Failover-Status Eine Lambda-Funktion ruft describe_db_clusters Boto3-APIs auf, um den Status des Failovers zu überprüfen. modifizieren, verfügbar Erfolgstoken senden Eine Lambda-Funktion ruft send_task_success Boto3-APIs auf und sendet ein Erfolgstoken zurück an die Zustandsmaschine. DR Orchestrator FailoverRiCdLtdH7x dMccoxlzFhglsdkzp /83P1E0 K9mBVKZSP7D9YRT1W -
Navigieren Sie zur Amazon RDS-Konsole. Unter Status ändern sich die Werte für die globale Aurora-Datenbank von Verfügbar auf Umschalten oder Ändern.
-
Nachdem die
dr-orchestrator-stepfunction-planned-Aurora-failoverZustandsmaschine abgeschlossen ist, sendet sie ein Erfolgstoken zurück an diedr-orchestrator-stepfunction-FAILOVERZustandsmaschine.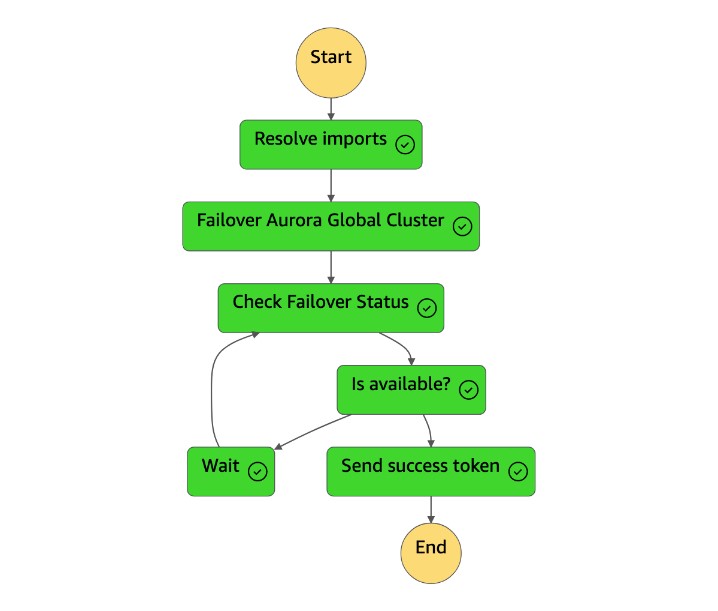
-
Die
dr-orchestrator-stepfunction-FAILOVERZustandsmaschine ist abgeschlossen.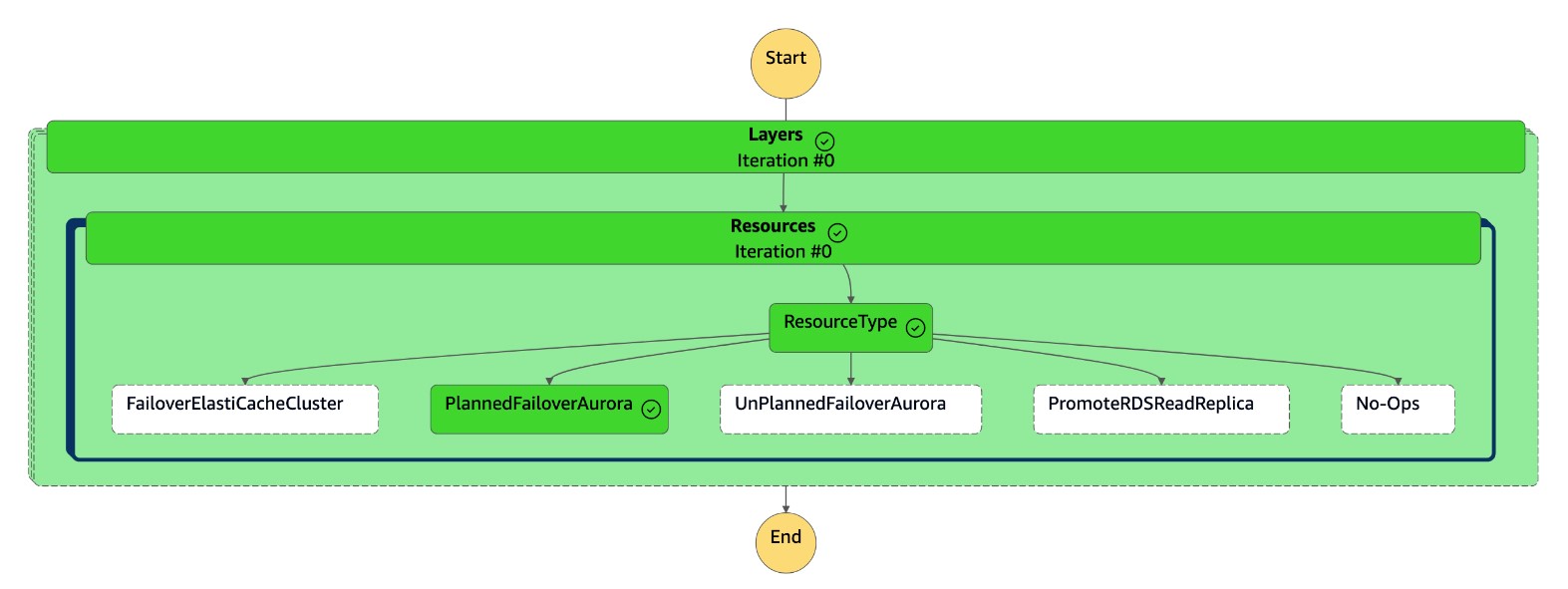
Auf der Konsole hat der sekundäre Cluster (dbcluster-02) jetzt die Rolle des primären Clusters, und der Cluster ist bereit, Lese-/Schreib-Workloads zu verarbeiten. Die Rolle des ursprünglichen primären Clusters (dbcluster-01) ist jetzt als Sekundärer Cluster aufgeführt.
Manuelles ungeplantes Failover
In seltenen Fällen kann es bei Ihrer globalen Aurora-Datenbank zu einem unerwarteten Ausfall der AWS-Region Primärdatenbank kommen. In einem solchen Fall sind der primäre Aurora-DB-Cluster und sein Writer-Knoten nicht verfügbar, und die Replikation zwischen dem primären Cluster und den sekundären Clustern wird eingestellt. Um sowohl Ausfallzeiten (RTO) als auch Datenverlust (RPO) zu minimieren, sollten Sie schnell ein regionsübergreifendes Failover durchführen und Ihre globale Aurora-Datenbank rekonstruieren. Weitere Informationen finden Sie unter Wiederherstellung einer globalen Amazon Aurora Aurora-Datenbank nach einem ungeplanten Ausfall.
Um einen ungeplanten Failover durchzuführen, müssen Sie Ihren sekundären Cluster von der globalen Aurora-Datenbank trennen. Bevor Sie den ungeplanten Failover durchführen, beenden Sie Anwendungsschreibvorgänge auf Ihrem primären Aurora-DB-Cluster. Nachdem der Failover erfolgreich abgeschlossen wurde, konfigurieren Sie die Anwendung neu, sodass sie in den neuen primären DB-Cluster schreibt. Dieser Ansatz trägt dazu bei, Datenverlust zu verhindern. Es hilft auch, Dateninkonsistenzen zu vermeiden, wenn der primäre Writer-Knoten während des Failover-Prozesses wieder online geht.
Rufen Sie den State Machine auf, um den ungeplanten Failover durchzuführen. dr-orchestrator-stepfunction-FAILOVER In diesem Beispiel befindet sich der sekundäre Cluster (db-cluster-02) in der DR-Region (us-west-2) im Steady-State.
Gehen Sie wie folgt vor, um den Failover durchzuführen:
-
Melden Sie sich in der -Konsole an.
-
Ändern Sie die Region in die DR-Region (
us-west-2). -
Navigieren Sie zu Services und wählen Sie Step Functions aus.
-
Navigieren Sie zur
dr-orchestrator-stepfunction-FAILOVERZustandsmaschine. -
Wählen Sie Ausführung starten und geben Sie den folgenden JSON-Code in den
Input - optionalAbschnitt ein. Verwenden SieUnPlannedFailoverAuroradabeiresourceType:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
Die
dr-orchestrator-stepfunction-FAILOVERZustandsmaschine liest den Ressourcentyp alsUnPlannedFailoverAuroraMySQLund ruft die AufgabeDetach Cluster from Global Databasevon derdr-orchestrator-stepfunction-unplanned-Aurora-failoverZustandsmaschine aus auf.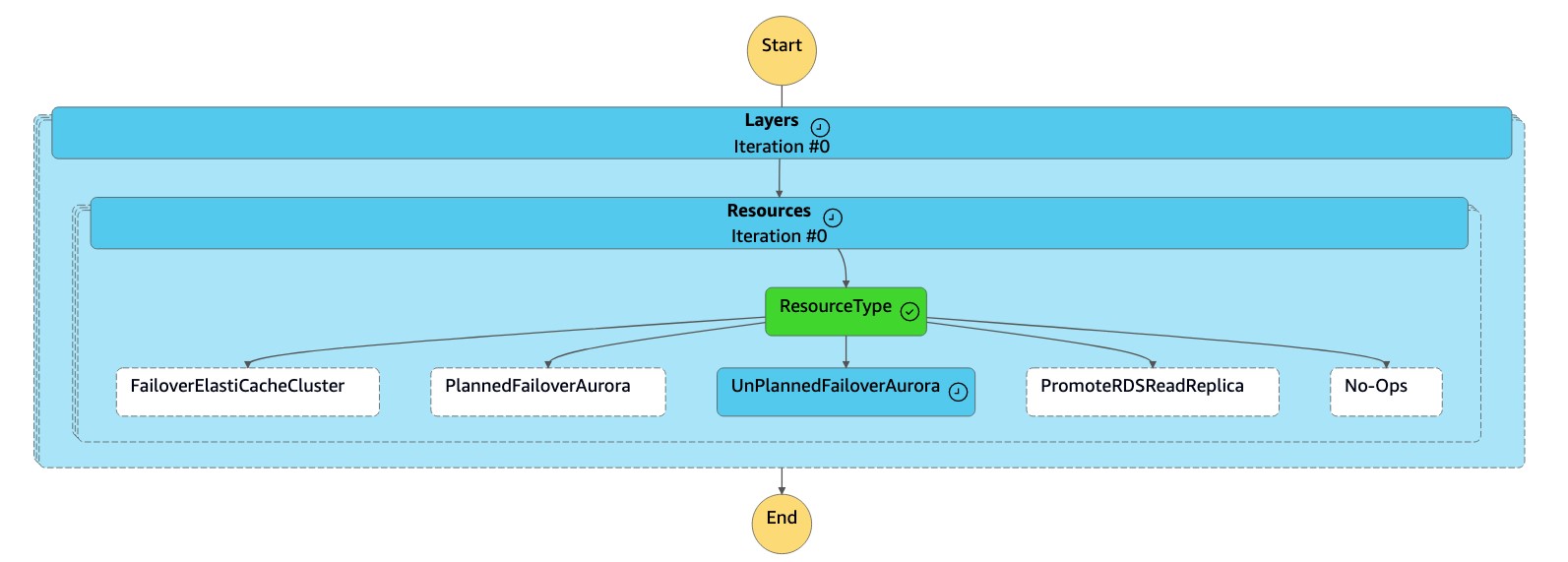
-
Die
Detach Cluster from Global DatabaseAufgabe trennt (entfernt) den sekundären Cluster von der globalen Datenbank.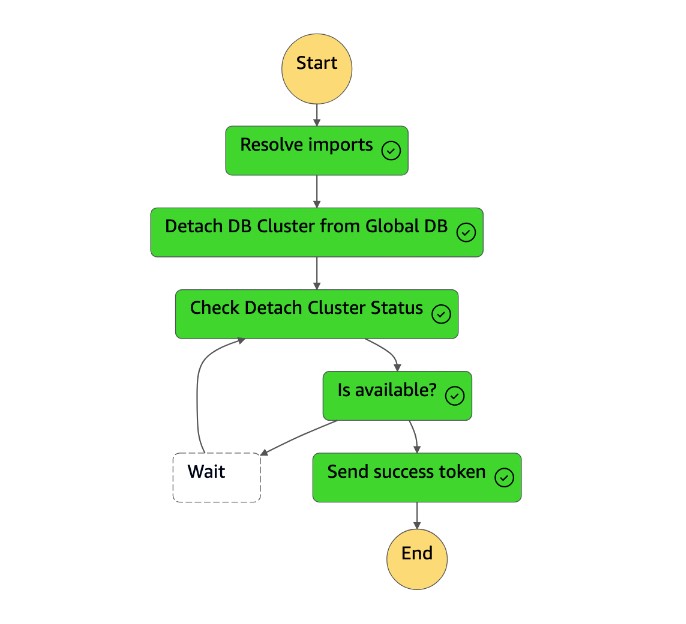
-
Der sekundäre Cluster (
dbcluster-02) wird zu einem eigenständigen Cluster heraufgestuft und kann Lese-/Schreib-Workloads bedienen. -
Die
dr-orchestrator-stepfunction-FAILOVERZustandsmaschine ist abgeschlossen.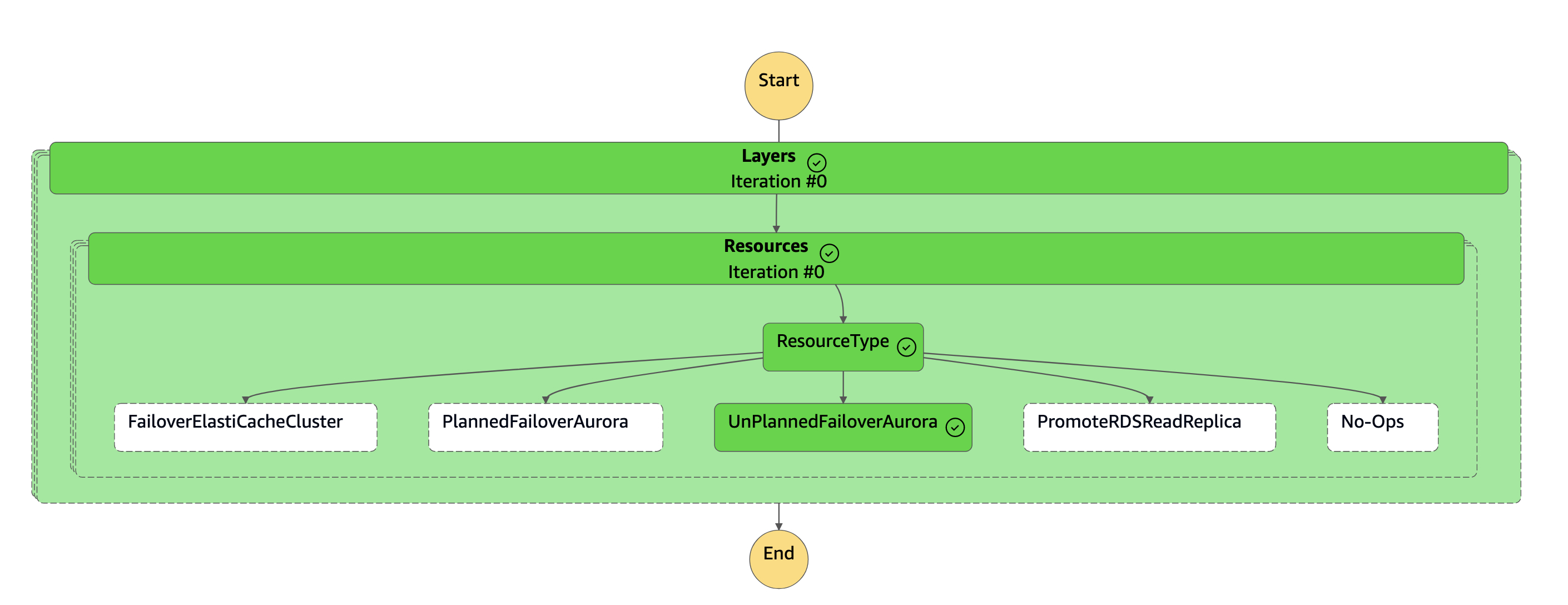
-
Der sekundäre Cluster (
dbcluster-02) ist von der globalen Aurora-Datenbank getrennt und wird zu einem eigenständigen Cluster, der die Lese-/Schreib-Arbeitslast bedient. -
Konfigurieren Sie Ihre Anwendung neu, sodass alle Schreibvorgänge mithilfe des neuen Cluster-Endpunkts an diesen neuen eigenständigen Aurora-DB-Cluster gesendet werden.
Failback
Ein Failback bringt Ihre Datenbank an den ursprünglichen (oder neuen) primären Standort zurück, nachdem ein Notfall (oder ein geplantes Ereignis) behoben wurde. Wenn der ungeplante Ausfall behoben ist, möchten Sie möglicherweise Ihre frühere Hauptregion wieder zur globalen Aurora-Datenbank hinzufügen. Sie müssen zuerst den vorhandenen DB-Cluster aus der früheren primären Region löschen, einen neuen DB-Cluster aus der neuen primären Region erstellen und dann den verwalteten geplanten Failover-Prozess verwenden, um die Rolle des neuen Clusters zu wechseln.
Dies kann als geplante Aktivität betrachtet werden, die Sie außerhalb der Hauptverkehrszeiten oder an einem Wochenende durchführen können.
Sie müssen den Amazon Aurora Aurora-DB-Cluster manuell ändern und deaktivieren, DeletionProtection bevor Sie den DR Orchestrator FAILBACK Zustandsmaschine aus der früheren primären Region (us-east-1) ausführen, da er mit erstellt wurdeDeletionProtection.
DR Orchestrator Framework verwendet die dr-orchestrator-stepfunction-FAILBACK Zustandsmaschine, um die Schritte zum Löschen des vorhandenen Clusters und zum Erstellen eines neuen Clusters in der ehemaligen Primärregion zu automatisieren.
Gehen Sie zum Deaktivieren DeletionProtection wie folgt vor:
-
Melden Sie sich in der -Konsole an.
-
Ändern Sie die Region in die frühere primäre Region (
us-east-1). -
Navigieren Sie zur Amazon RDS-Konsole, wählen Sie den Cluster-Namen (
dbcluster-01) aus und klicken Sie auf Modify. -
Deaktivieren Sie unter Löschschutz das Kontrollkästchen Löschschutz aktivieren und wählen Sie Weiter.
-
Wählen Sie Sofort anwenden und anschließend Cluster modifizieren aus.
Die DR Orchestrator FAILBACK Zustandsmaschine wird während des Failback-Vorgangs von der ehemaligen primären Region () us-east-1 aus aufgerufen.
Gehen Sie wie folgt vor, um das Failback durchzuführen:
-
Melden Sie sich in der -Konsole an.
-
Ändern Sie die Region in die frühere primäre Region (
us-east-1). -
Navigieren Sie zu Services und wählen Sie dann Step Functions aus.
-
Navigieren Sie zur
DR Orchestrator FAILBACKZustandsmaschine. -
Wählen Sie Ausführung starten und geben Sie den folgenden JSON-Code in den
Input - optionalAbschnitt ein:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
Die
DR Orchestrator FAILBACKZustandsmaschine liest den Ressourcentyp alsCreateAuroraSecondaryDBClusterund ruft diedr-orchestrator-stepfunction-create-Aurora-Secondary-clusterZustandsmaschine auf.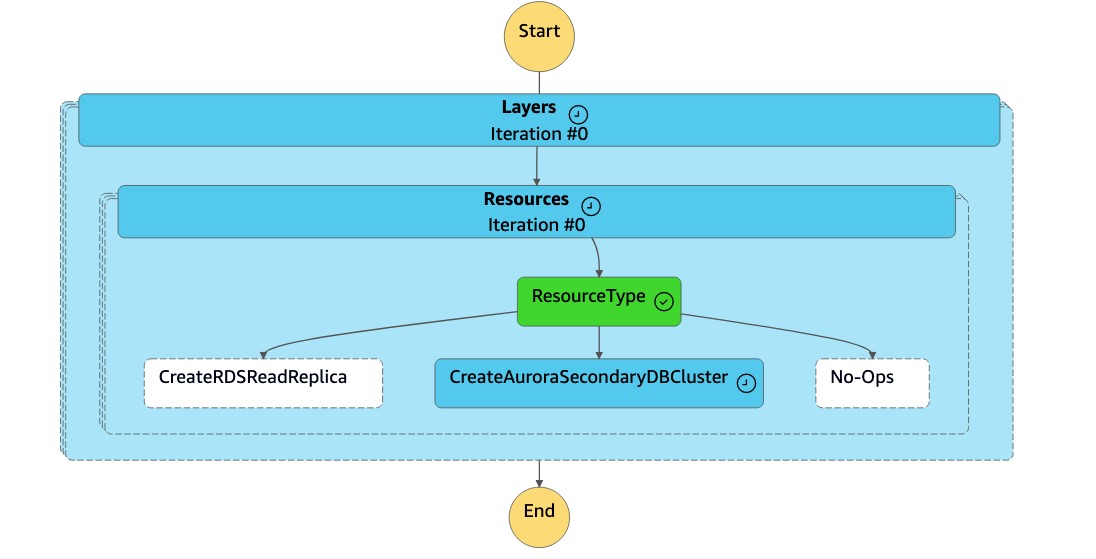
-
Die
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterZustandsmaschine löscht den vorhandenen Cluster (dbcluster-01) aus der früheren primären Region (us-east-1).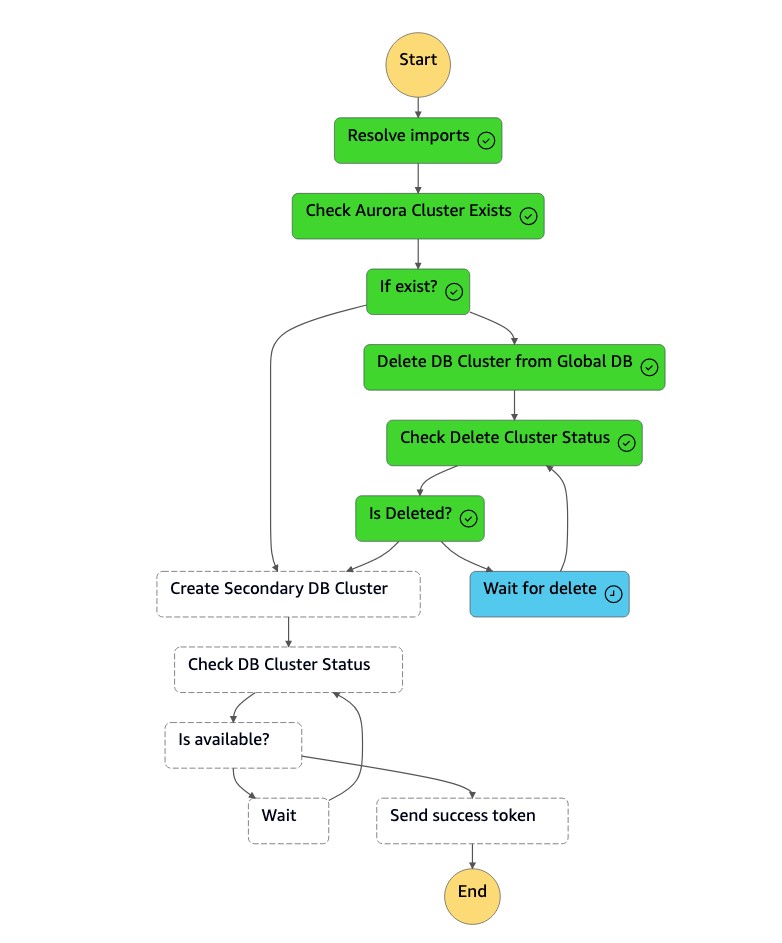
-
Nachdem der Cluster (
dbcluster-01) gelöscht wurde, erstellt die Zustandsmaschine zusammen mit der DB-Instance einen neuen Cluster (dbcluster-01) und tritt der globalen Aurora-Datenbank als sekundärer Cluster bei, um schreibgeschützte Workloads zu bedienen.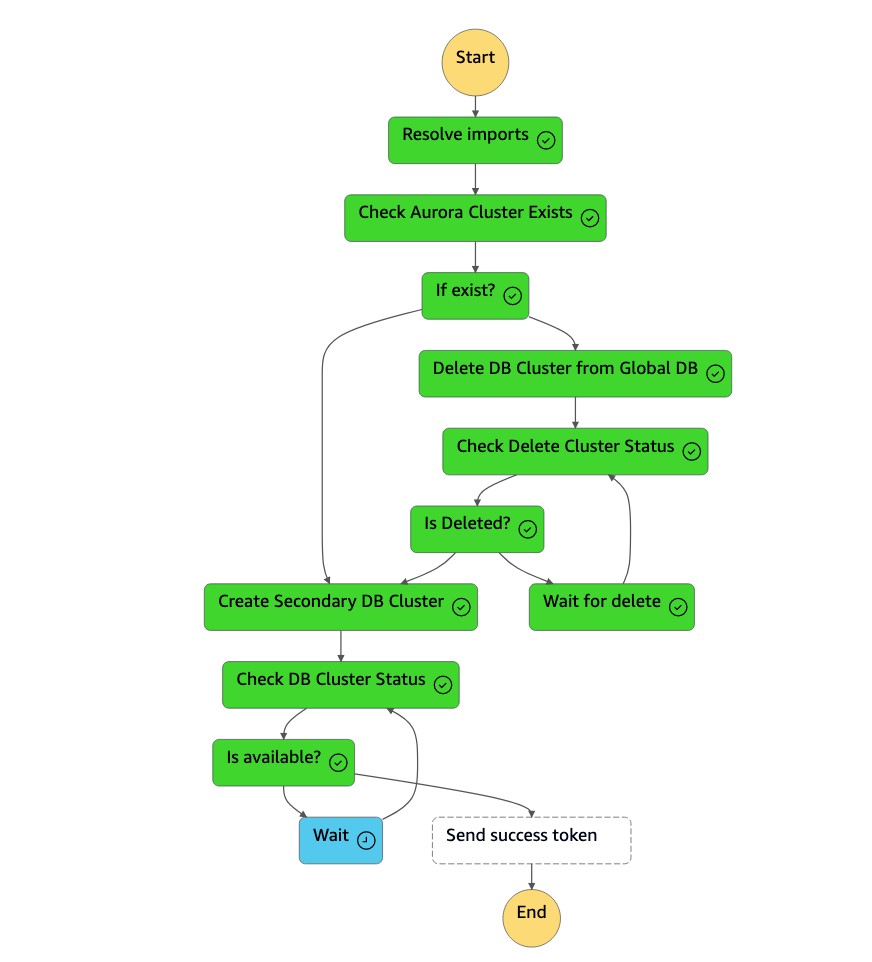
-
Sobald der sekundäre Cluster verfügbar ist, ist die
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterZustandsmaschine fertig gestellt und sie sendet ein Erfolgstoken zurück an dieDR Orchestrator FailbackZustandsmaschine.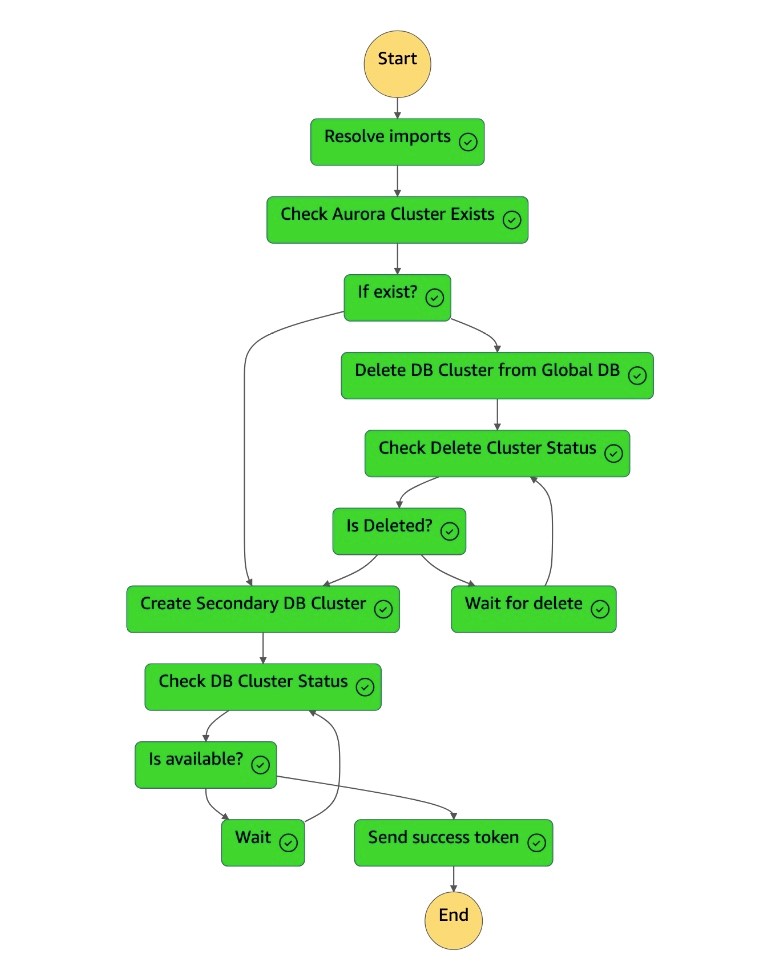
-
Die
dr-orchestrator-stepfunction-FAILBACKZustandsmaschine ist abgeschlossen.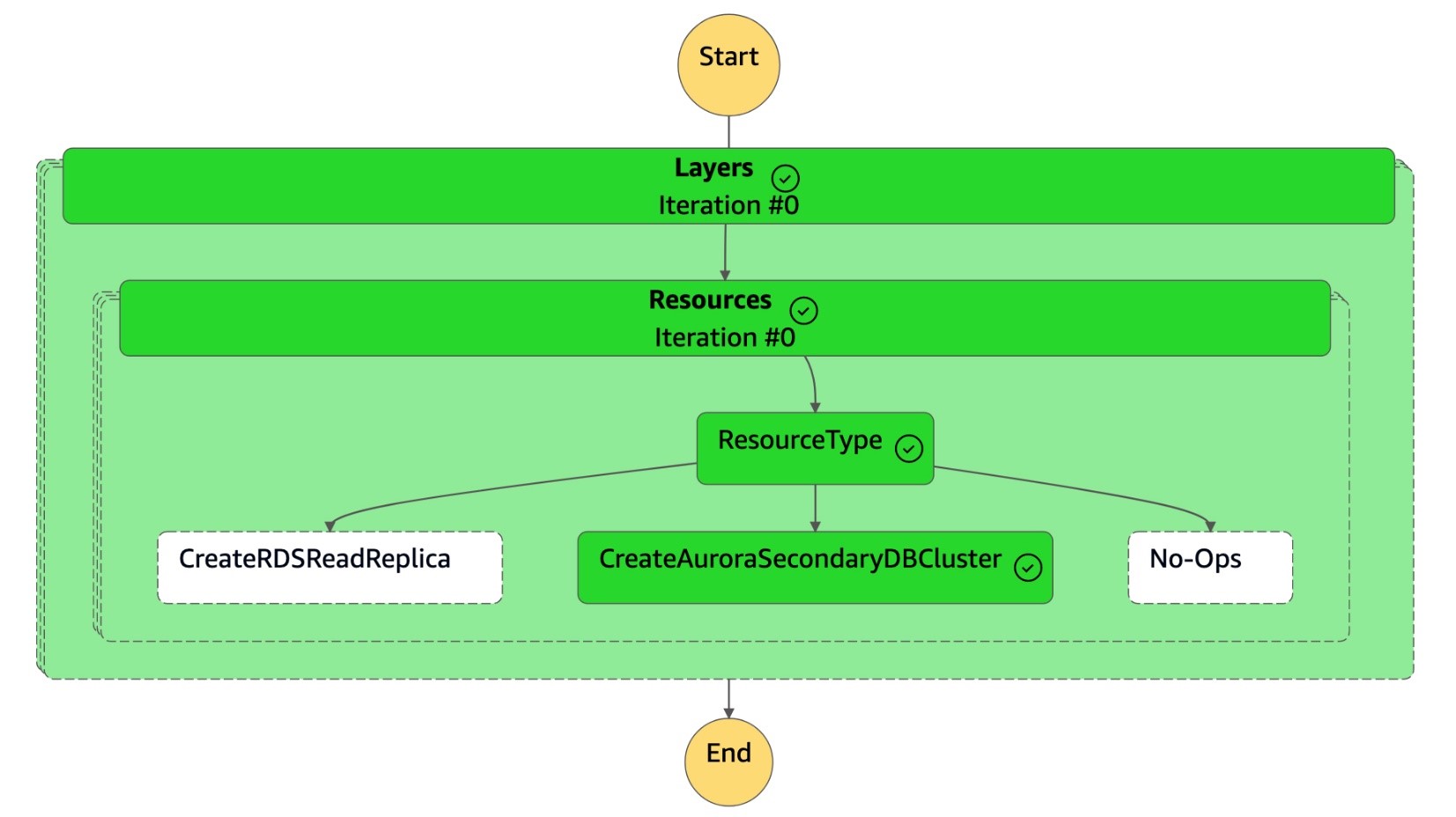
-
Sie können die globale Aurora-Datenbank auf der Amazon RDS-Konsole überprüfen.
