Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Zentralisierter Katalog
Das folgende Diagramm zeigt, wie der zentralisierte Katalog Datenproduzenten und Datenkonsumenten im Data Lake verbindet.
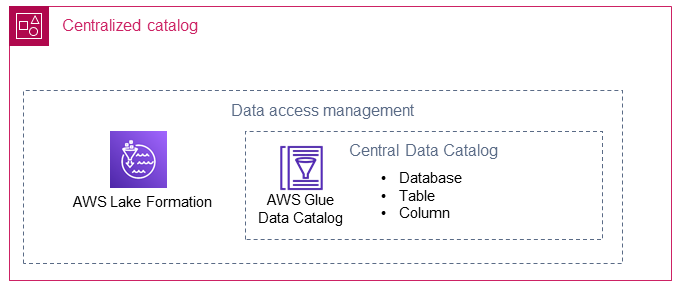
Der zentrale Katalog speichert und verwaltet den gemeinsamen Datenkatalog für die Konten der Datenproduzenten. Der zentrale Katalog enthält auch die technischen Metadaten der gemeinsam genutzten Daten (z. B. Tabellenname und Schema) und ist der Ort, an dem Datenkonsumenten auf Daten zugreifen.
Datenverbraucher können auf Daten von mehreren Datenproduzenten im zentralisierten Katalog zugreifen und diese Daten dann zur weiteren Verarbeitung mit ihren eigenen Daten mischen. Durch die Verwendung eines zentralisierten Katalogs müssen Datenkonsumenten keine direkte Verbindung zu verschiedenen Datenproduzenten herstellen, und der Betriebsaufwand wird reduziert.
Da der zentralisierte Katalog Einblick in die gemeinsame Nutzung und Nutzung von Daten durch Datenproduzenten und -verbraucher bietet, kann er ein idealer Ort sein, um Ihre zentralen Datenverwaltungsfunktionen (z. B. Zugriffsprüfung) anzuwenden.
In den folgenden Abschnitten wird beschrieben, wie der zentralisierte Katalog AWS Lake Formation und verwendet AWS Glue.
AWS Lake Formation
AWS Lake Formationhilft bei der Erstellung von Datenbanken in einem AWS Glue Datenkatalog, die auf die Standorte mehrerer Datenproduzenten in Ihrem Data Lake verweisen. Eine AWS Identity and Access Management (IAM-) Rolle wird für Lake Formation im zentralisierten Katalog erstellt. Durch die Verwendung von Lake Formation kann der zentralisierte Katalog Datenressourcen (z. B. Datenbanken, Tabellen oder Spalten) selektiv mit Datenverbrauchern teilen. Die von Lake Formation verwalteten Ressourcen werden mithilfe einer der folgenden beiden Methoden mit Datenverbrauchern gemeinsam genutzt:
-
Methode mit benannter Ressource — Bei dieser Methode werden verwaltete Ressourcen von mehreren Konten gemeinsam genutzt. Datenbanken, Tabellen oder Spaltennamen müssen angegeben werden, und eine Ressource kann für eine Organisation, Organisationseinheit (OU) oder gemeinsam genutzt werden AWS-Konto. Um den Gemeinschafts- und Verwaltungsaufwand zu reduzieren, empfehlen wir, Ressourcen nach Möglichkeit auf höheren Ebenen gemeinsam zu nutzen (z. B. in einer Organisation oder Organisationseinheit statt in einer AWS-Konto). Sie müssen jedoch sicherstellen, dass dieser Ansatz die Anforderungen Ihrer Organisation an die Datensicherheitskontrolle erfüllt.
-
Hinweis: Diese Methode eignet sich gut für Datennutzer mit einem Anwendungstyp, bei dem AWS Dienste Daten vom Datenproduzenten verwenden. Die Datenzugriffsanforderungen für diese Art von Datenkonsumenten sind anwendungsabhängig, präskriptiv und relativ statisch.
-
-
Tag-Based Access Control (LF-TBAC) -Methode (Lake Formation, Tag-Based Access Control) — LF-TBAC ist besonders nützlich für Datenkonsumenten mit einem Datenbereitungstyp. Ressourcen, die mit Lake Formation gekennzeichnet sind, können derzeit jedoch nur auf AWS-Konto Ebene und nicht auf Organisations- oder OU-Ebene gemeinsam genutzt werden.
AWS Glue
Sie müssen Datenbanken AWS Glue für jeden Datenproduzenten in Ihrem zentralisierten Katalog erstellen. Da der zentralisierte Katalog AWS Glue Datenbanken aller Datenproduzenten hostet, müssen Sie sicherstellen, dass der Datenbankname für alle Datenproduzenten eindeutig ist und dass er den Datenproduzenten und dessen Datentyp widerspiegelt. Sie können beispielsweise die folgende Datenbankbenennungsstruktur verwenden: <Data_Producer>–<Environment>–<Data_Group>
-
<Data_Producer>— Der Name des Datenproduzenten. -
<Environment>— Die Data-Lake-Umgebung, z. B.devfür eine Entwicklungsumgebung,sitfür eine Systemintegrationstestumgebung oderprodfür eine Produktionsumgebung. -
<Data_Group>— Der Name der Datengruppe, die verwendet wird, um Daten von einem Datenproduzenten in logische Gruppen zu unterteilen. Sie können den Namen, die ID oder die Abkürzung des Quellsystems als Namen verwenden. Eine Datenbankbeschreibung hilft auch dabei, den Inhalt und den Zweck der Datenbank zu beschreiben.
Sie können einen AWS Glue Crawler für die Daten des Datenproduzenten verwenden, um dessen Schema in der Datenbank des zentralen Katalogs zu verwalten. Wenn Daten regelmäßig mit derselben Frequenz von einem Datenproduzenten erstellt werden, können Sie einen einzelnen AWS Glue Crawler verwenden. In allen anderen Fällen sollten Sie mehrere AWS Glue Crawler verwenden, um unterschiedliche Crawling-Frequenzen zu berücksichtigen. Je nach geschäftlichem Anwendungsfall kann der Crawler entweder für eine vordefinierte Frequenz geplant oder durch Ereignisse initiiert werden.
Sie können das Tabellenschema auch verwalten, AWS Glue indem Sie die AWS Glue API aufrufen, um das Schema zu erstellen oder zu aktualisieren. Dies kann zwar für Flexibilität sorgen, es ist jedoch zusätzlicher Aufwand für die Codeentwicklung und -wartung erforderlich. Stellen Sie sicher, dass Sie den Anwendungsfall und den geschäftlichen Nutzen bewerten und dann die Option wählen, die Ihren Anforderungen entspricht und den geringsten Aufwand verursacht.
