Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Allgemeine Skalierungsherausforderungen
Ein Data Lake durchläuft mehrere Phasen, in denen seine Datenmenge nach der ersten Bereitstellung anwächst. Wenn Sie bei der Gestaltung Ihres Data Lakes keine skalierbare Architektur verwendet haben, könnte Ihr Unternehmen vor Herausforderungen stehen und durch das Wachstum des Data Lakes benachteiligt werden.
In den folgenden Abschnitten wird erklärt, wie das Wachstum eines typischen Data Lakes zu Skalierungsproblemen führen kann.
Erste Bereitstellung eines Data Lake
Das folgende Diagramm zeigt die Architektur eines Data Lakes nach seiner ersten Bereitstellung durch den Geschäftsbereich A.
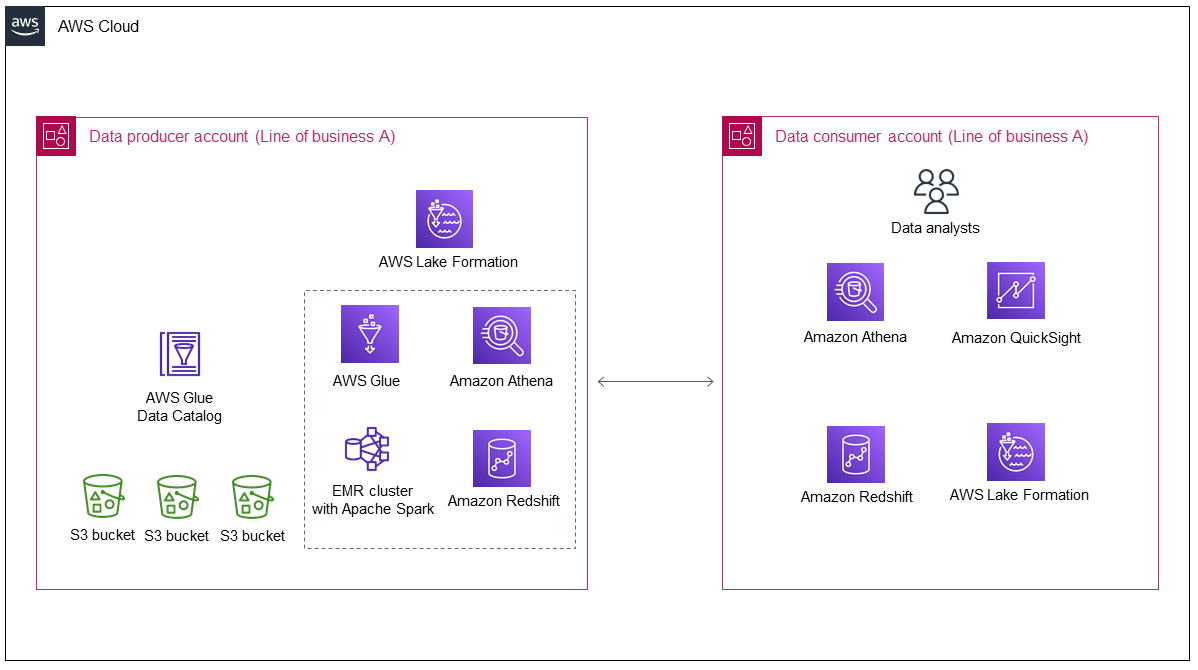
Das Diagramm zeigt die folgenden Komponenten:
-
Das Konto des Datenproduzenten sammelt und verarbeitet Daten, speichert die verarbeiteten Daten und bereitet sie für den Verbrauch auf.
-
Daten im Data Producer-Konto werden in Amazon Simple Storage Service (Amazon S3) -Buckets gespeichert, die mehrere Datenschichten haben können.
-
Sie können AWS Dienste für die Datenverarbeitung verwenden (z. B. AWS Glueund Amazon EMR).
-
Der Datenproduzent erzeugt und speichert nicht nur Daten im Data Lake, sondern muss dann auch entscheiden, welche Daten er mit einem Datenverbraucher teilen möchte und wie er sie teilt. AWS Lake Formation verwaltet den Data Lake im Datenproduzentenkonto und verwaltet zusätzlich den kontenübergreifenden Datenaustausch vom Datenproduzenten bis zum Datenverbraucher.
-
Das Datenverbraucherkonto nutzt gemeinsam genutzte Daten aus dem Datenproduzentenkonto für spezifische geschäftliche Anwendungsfälle.
Die Zahl der Datennutzer nimmt zu
Das folgende Diagramm zeigt, dass mehr Daten in den Data Lake gelangen, wenn die Datenmenge von Geschäftsbereich A zunimmt. Der Data Lake zieht dann mehr Datenkonsumenten an, um die Daten zu nutzen und Mehrwert aus ihnen zu ziehen.
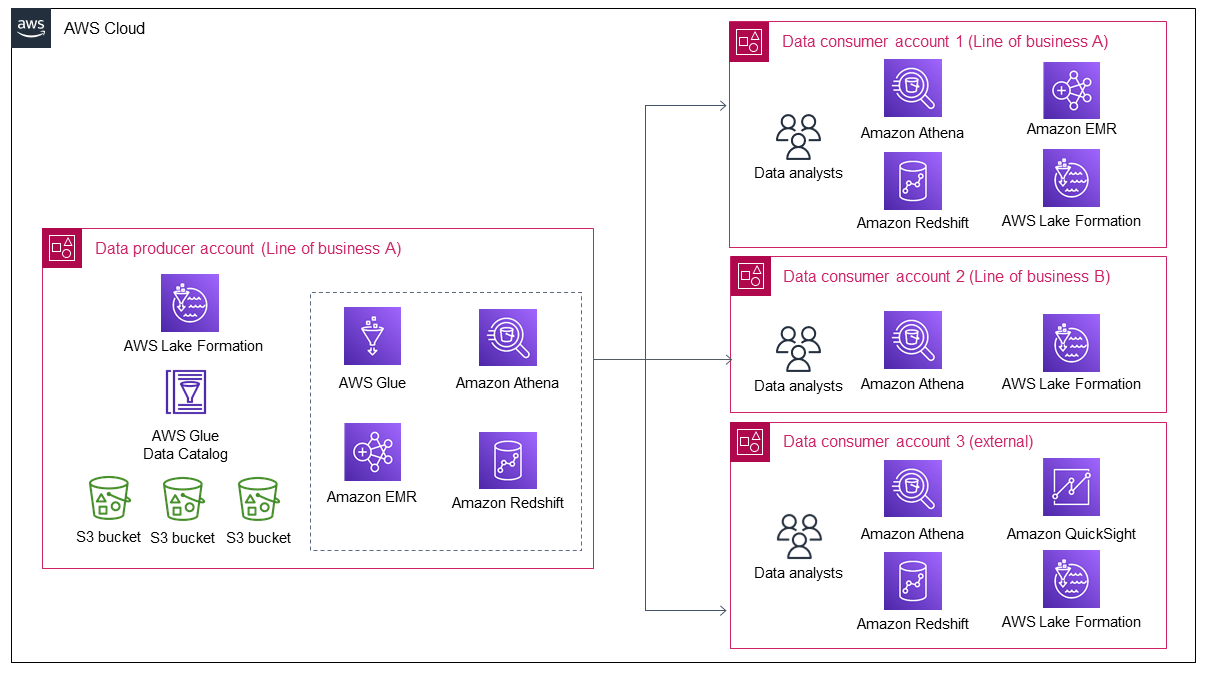
Das Diagramm zeigt, wie ein Unternehmen nahezu kontinuierlich Wert aus einem vorhandenen Datenbestand generiert und dass dies mehr Datennutzer anzieht. Bei einer Zunahme der Datenverbraucher stehen dem Datenproduzenten jedoch nur die folgenden zwei Optionen zur Verfügung, um diesem Wachstum Rechnung zu tragen:
-
Manuelles Verwalten der gemeinsamen Nutzung von Daten und des Zugriffs durch einzelne Datenverbraucher, was kein skalierbarer Ansatz ist.
-
Entwickeln Sie einen automatisierten oder halbautomatischen Prozess für die gemeinsame Nutzung von Daten und die Verwaltung des Datenzugriffs. Dies könnte zwar eine skalierbare Option sein, erfordert jedoch einen erheblichen Zeit- und Arbeitsaufwand bei der Planung und Erstellung, da interne und externe Datenverbraucher unterschiedliche Anforderungen an die Sicherheitskontrolle haben. In future wären auch zusätzliche Zeit und Mühe für alle Lösungsverbesserungen erforderlich.
Die Zahl der Datenproduzenten steigt
Das folgende Diagramm zeigt die Data-Lake-Architektur, wenn sich mehrere Geschäftsbereiche als Datenproduzenten zusammenschließen.
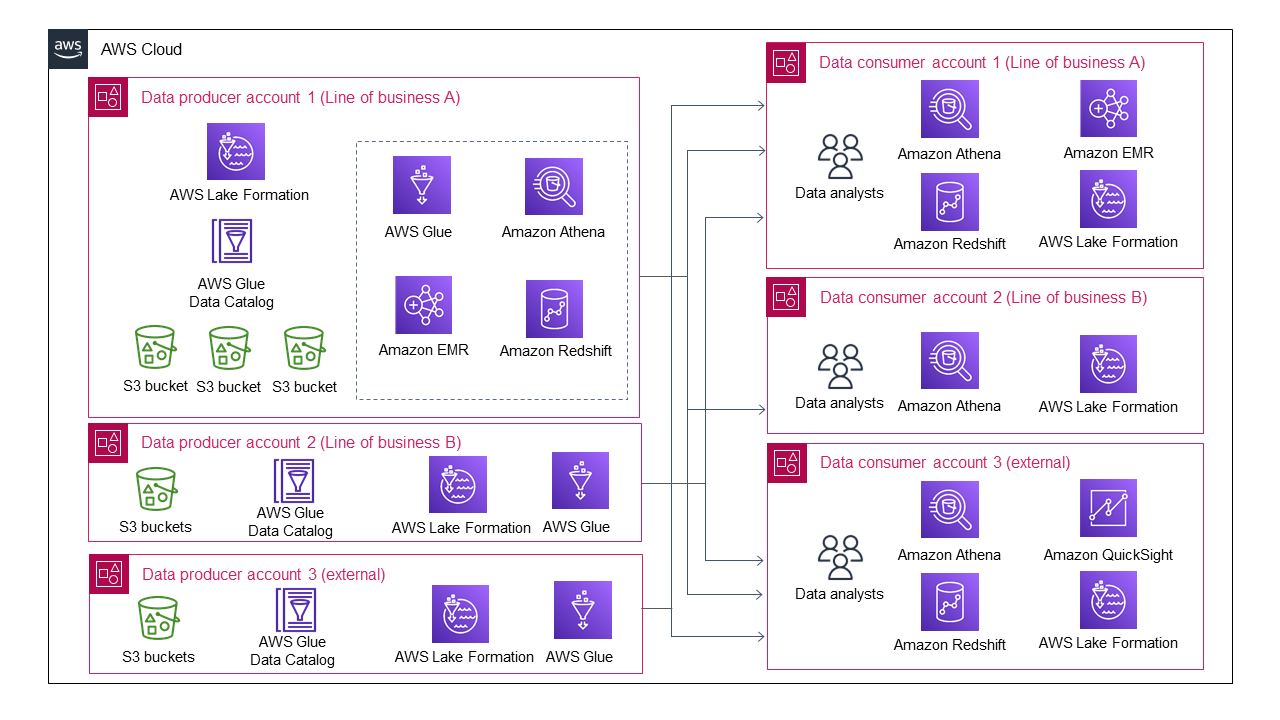
Die Architektur eines Data Lakes wird immer komplizierter, selbst wenn es nur drei Datenproduzenten und drei Datenkonsumenten gibt.
Jeder Datenproduzent muss sich um die gemeinsame Nutzung von Daten und das Datenzugriffsmanagement für mehrere Datenverbraucher kümmern. Es ist unrealistisch zu erwarten, dass alle Datenproduzenten ein automatisiertes oder halbautomatisiertes Verfahren für die gemeinsame Nutzung von Daten und das Datenzugriffsmanagement entwickeln. Einige Datenproduzenten entscheiden sich möglicherweise dafür, ihre Daten nicht weiterzugeben, um unerschwinglichen Verwaltungsaufwand zu vermeiden. In ähnlicher Weise muss jeder Datenverbraucher mit mehreren Datenproduzenten interagieren, um deren unterschiedliche Datennutzungsprozesse zu verstehen. Das bedeutet, dass einzelne Datenkonsumenten mit einem zunehmenden Verwaltungsaufwand konfrontiert sind, wenn es um den Umgang mit unterschiedlichen Mustern des Datenaustauschs geht.
In vielen Unternehmen führt dieser Data Lake zu Engpässen und kann weder wachsen noch skalieren. Dies kann bedeuten, dass Ihr Unternehmen seinen Data Lake neu entwerfen und neu aufbauen muss, um den Engpass zu beseitigen, was viel Zeit, Ressourcen und Geld kosten kann.
