Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Referenzarchitektur
Das folgende Diagramm zeigt die Referenzarchitektur dieses Handbuchs für das Wachstum und die Skalierung eines Data Lakes auf dem AWS Cloud.
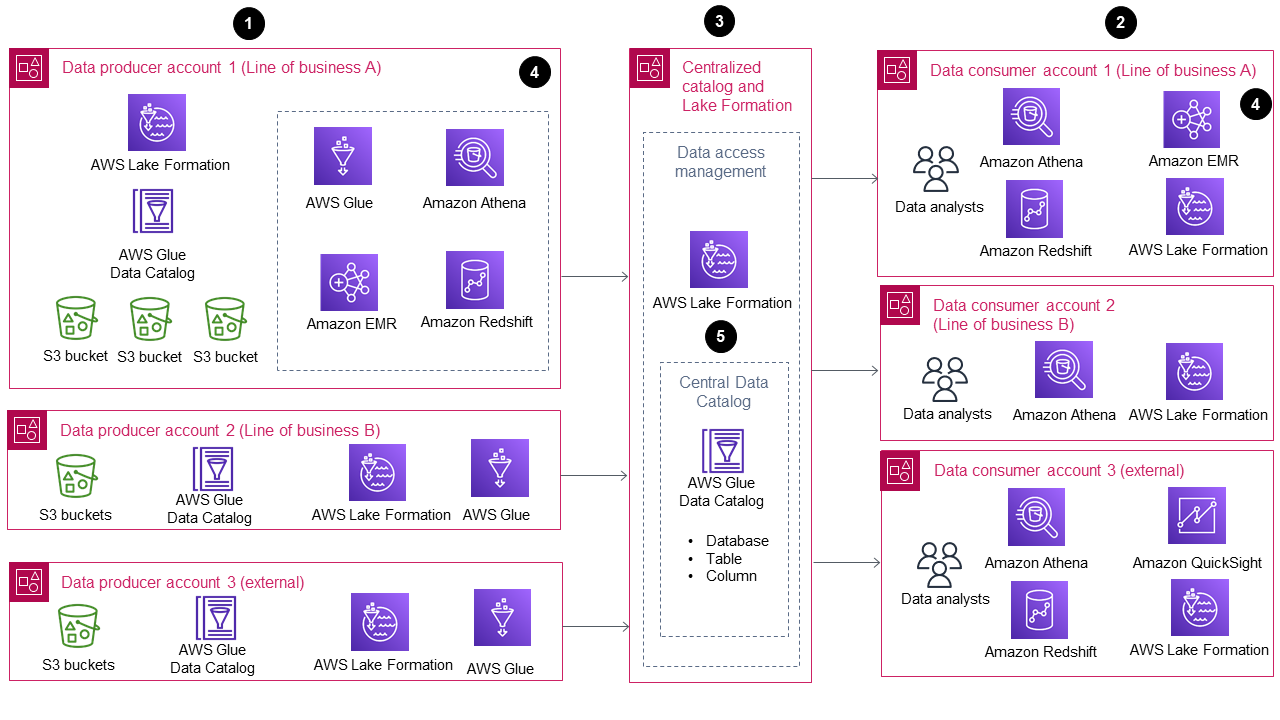
Das Diagramm zeigt die folgenden Komponenten:
-
Eine Datenproduzentenebene ist unterschiedlich AWS-Konten.
-
Eine Datenverbraucherebene ist anders AWS-Konten.
-
Ein zentralisierter Katalog in einem AWS-Konto.
-
Obwohl es in jedem Geschäftsbereich nur einen Datenproduzenten und einen Datenverbraucher gibt, unterstützt die Referenzarchitektur des Leitfadens mehrere Datenproduzenten und Datenkonsumenten für jeden Geschäftsbereich. Es ist üblich, einen Datenproduzenten mit einem oder mehreren Datenverbrauchern zu verbinden, zu denen sowohl Datenbereitstellungs- als auch Anwendungstypen gehören. Weitere Informationen dazu finden Sie im Komponenten der Referenzarchitektur Abschnitt dieses Handbuchs.
-
Der zentralisierte Katalog ist die Schnittstelle, die von Datenproduzenten und Datenkonsumenten verwendet wird, um Daten auszutauschen und zu konsumieren.
Der Ansatz der Referenzarchitektur ermöglicht es, die gemeinsame Nutzung und Nutzung von Daten zu standardisieren und Datenproduzenten und Datenverbraucher unabhängig voneinander zu skalieren, ohne Ihren Verwaltungsaufwand zu erhöhen. Die Referenzarchitektur ermöglicht auch die Datenproduktion und -verteilung zwischen verschiedenen Datenproduzenten. Jeder Datenproduzent kann Teil des Data Lakes sein, seine Daten teilen und so zum Gesamtwert beitragen, den der Data Lake bietet.
Dieser Ansatz ermöglicht es Ihrem Unternehmen, Datenwerte in allen Geschäftsbereichen und externen Dateneigentümern zu nutzen, ohne dass dadurch Engpässe entstehen, indem die Datenerfassung und -verarbeitung in einer einzigen Pipeline eingeschränkt wird.
