Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Benennen von Amazon S3 S3-Buckets in Ihren Datenschichten
Die folgenden Abschnitte enthalten Benennungsstrukturen für Amazon Simple Storage Service (Amazon S3) -Buckets in Ihren Data Lake-Ebenen. Sie können die Amazon S3 S3-Bucket- und Pfadnamen jedoch an die Anforderungen Ihrer Organisation anpassen. Wir empfehlen, separate Buckets für jede einzelne Ebene zu erstellen, da die Anforderungen an Archivierung, Versionierung, Zugriff und Verschlüsselung für jede Ebene variieren können.
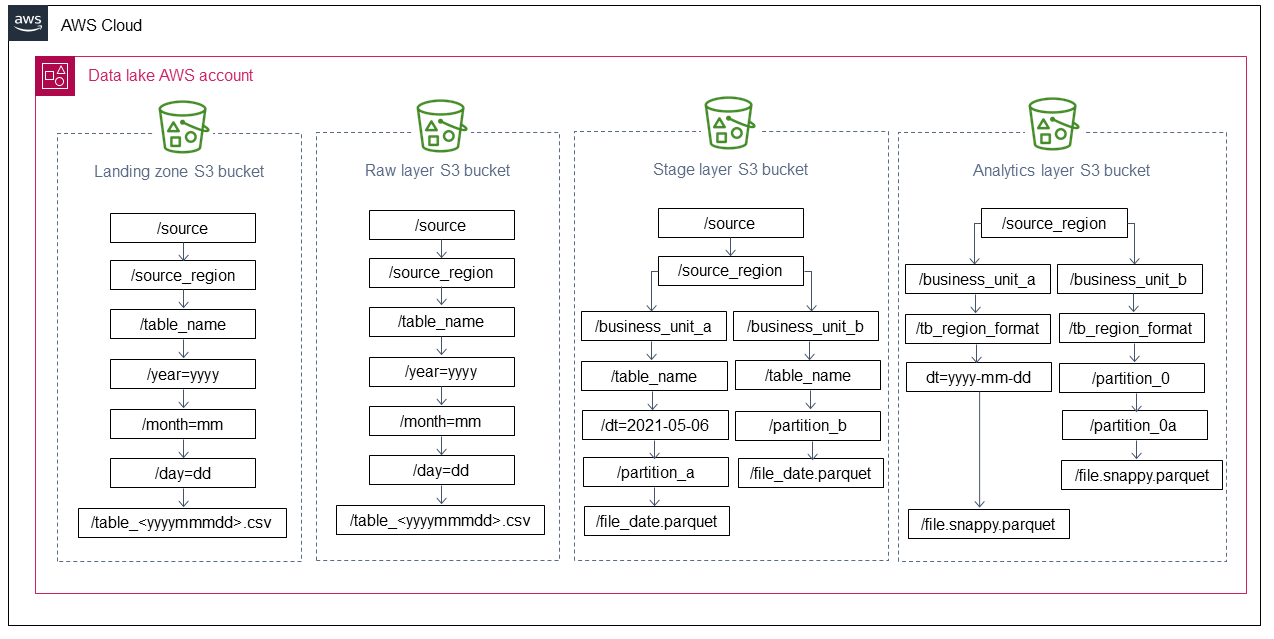
Das folgende Diagramm zeigt die empfohlene Benennungsstruktur für Amazon S3 S3-Buckets in den empfohlenen Data-Lake-Schichten. Die Benennungsstruktur trennt mehrere Geschäftsbereiche, Dateiformate und Partitionen.
Wichtig
Amazon S3 S3-Buckets müssen den Benennungsrichtlinien der Bucket-Benennungsregeln in der Amazon S3 S3-Dokumentation entsprechen.
Sie können Datenpartitionen an die Anforderungen Ihres Unternehmens anpassen. Sie sollten jedoch Paare aus Kleinbuchstaben und Schlüssel/Wert verwenden (z. B. year=yyyy anstelle vonyyyy), damit Sie den Katalog mit dem Befehl aktualisieren können. MSCK REPAIR
TABLE
Die Definition einer Partitionsstrategie hängt von der Art Ihrer Daten und vor allem von der Art Ihrer Benutzerabfragen ab. Wir empfehlen Ihnen, die Verbrauchs- und Datenverarbeitungsmuster zu analysieren, um die für Ihr Unternehmen am besten geeignete Strategie zu finden. Im Allgemeinen ist es sinnvoll, höhere Hierarchieebenen, z. B.year=yyyy, und month=mmday=dd, auf der Rohdatenebene und niedrigere Hierarchieebenen auf Verbrauchsdatenebenen wie der Stufe- und Analyseebene vorzusehen. Dies liegt daran, dass Rohdatenschichten in der Regel nicht die komplexen Nutzungsmuster von Datenverarbeitungspipelines aufweisen.
Landezone Amazon S3 S3-Bucket
Sie benötigen einen Amazon S3 S3-Bucket für Ihre landing zone, wenn sensible Datensätze Elemente enthalten, die maskiert werden müssen, bevor Daten in den Raw-Bucket verschoben werden.
Die folgende Tabelle enthält die Benennungsstruktur, eine Beschreibung der Benennungsstruktur und ein Namensbeispiel für den Amazon S3 S3-Bucket in Ihrem landing zone Zone-Layer.
| Benennungsformat | Beispiel |
|---|---|
|
|
Amazon S3 S3-Bucket mit Rohschicht
Die Rohdatenschicht enthält aufgenommene Daten, die nicht transformiert wurden und in ihrem ursprünglichen Dateiformat wie JSON oder CSV vorliegen. Diese Daten sind in der Regel nach Datenquelle und Datum geordnet, an dem sie in den Amazon S3 S3-Bucket der Rohdatenschicht aufgenommen wurden.
Die folgende Tabelle enthält die Benennungsstruktur, eine Beschreibung der Benennungsstruktur und ein Namensbeispiel für den Amazon S3 S3-Bucket in Ihrer Rohdatenschicht.
| Benennungsformat | Beispiel |
|---|---|
|
|
Amazon S3 S3-Bucket auf Stufenebene
Daten in der Stageebene werden aus der Rohschicht gelesen und transformiert (z. B. mithilfe eines AWS Glue oder eines Amazon EMR-Jobs). Dieser Prozess validiert die Daten (z. B. durch Überprüfung von Datentypen und Headern) und speichert sie anschließend in einem nutzbaren Dateiformat wie Apache Parquet. Die Metadaten werden in einer Tabelle im gespeichert. AWS Glue Data Catalog
Die folgende Tabelle enthält die Benennungsstruktur, eine Beschreibung der Benennungsstruktur und ein Namensbeispiel für den Amazon S3 S3-Bucket in Ihrer Stage-Datenschicht.
| Benennungsformat | Beispiel |
|---|---|
|
|
Analyseschicht Amazon S3 S3-Bucket
Die Analyseebene ähnelt der Stage-Ebene, da die Daten in einem verarbeiteten Dateiformat vorliegen, die Daten dann jedoch gemäß den Anforderungen Ihrer Organisation aggregiert werden.
Die folgende Tabelle enthält die Benennungsstruktur, eine Beschreibung der Benennungsstruktur und ein Namensbeispiel für den Amazon S3 S3-Bucket in Ihrer Analytics-Datenschicht.
| Benennungsformat | Beispiel |
|---|---|
|
|
