Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Modelle für maschinelles Lernen zur Prognose der Frachtnachfrage
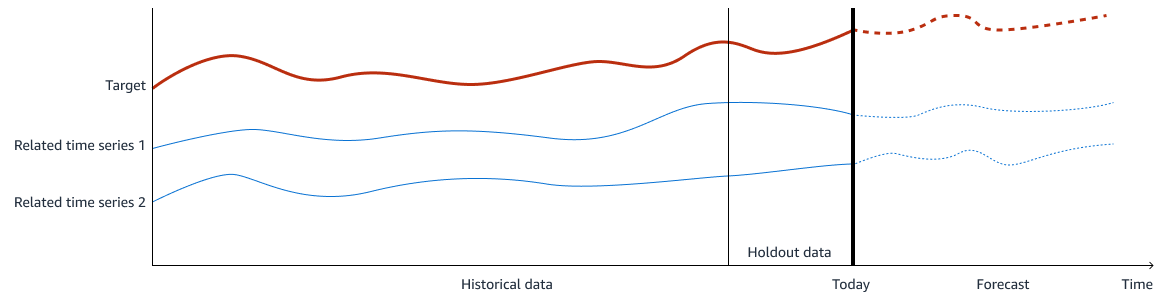
Die folgende Abbildung zeigt ein Beispiel für die Trainingsdaten. Das Ziel ist das, was Sie vorhersagen möchten, und die zugehörigen Zeitreihen 1 und 2 sind Eingabe-Features, die für die Vorhersage des Ziels relevant sind. Historische Daten werden für das Training und die Validierung verwendet, und Sie behalten einen bestimmten Zeitraum der historischen Daten für die Modellvalidierung zurück.
Bei der Bedarfsprognose entspricht die Leistung (oder das Ziel) dem Nachfragevolumen, das Sie vorhersagen möchten. Die Eingabe-Features sind Zeitreihendaten, die sich auf die Ausgabe beziehen. Um ein ML-Modell so zu trainieren, dass es eine genaue Prognose des Bedarfsvolumens erstellt, sind in der Lösung zwei Modelle für maschinelles Lernen erforderlich. Das erste Modell erstellt eine Zeitreihenprognose für die Eingabefunktionen, einschließlich interner und externer Daten. Das zweite Modell erstellt die endgültige Bedarfsprognose unter Verwendung aller Funktionen. Wenn Sie diese beiden Modelle zusammen verwenden, können Sie sowohl den Zeitreihentrend als auch die Beziehung zwischen dem Ziel und den Eingaben effektiv erfassen.
ML-Modell für die Prognose der Eingabe-Features
Zu den Eingabefunktionen gehören sowohl interne als auch externe historische Zeitreihendaten. Um Prognosen für jedes Feature zu erstellen, können Sie ein eindimensionales (1D) Zeitreihenmodell verwenden. Es sind verschiedene Algorithmen verfügbar. Prophet
ML-Modell für die Prognose der Zielvariablen
Das ML-Modell für die Ausgabe oder das Bedarfsvolumen ist so konzipiert, dass es die Beziehung zwischen allen Funktionen und der Ausgabe erfasst. Sie können verschiedene überwachte Regressionsmodelle verwenden, z. B.lasso, ridge regressionrandom forest, undXGBoost. Bei der Modellerstellung und der Suche nach den besten Parametern und Hyperparametern können Sie Holdout-Daten verwenden. Bei Holdout-Daten handelt es sich um einen Teil historischer, beschrifteter Daten, der aus dem Datensatz, der zum Trainieren eines Modells für maschinelles Lernen verwendet wird, zurückgehalten wird. Sie können Holdout-Daten verwenden, um die Leistung des Modells zu bewerten, indem Sie die Vorhersagen mit den Holdout-Daten vergleichen.
