Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Lokale Interpretierbarkeit
Die gängigsten Methoden zur lokalen Interpretierbarkeit komplexer Modelle basieren entweder auf Shapley Additive Explanations (SHAP) [8] oder integrierten Gradienten [11]. Jede Methode hat eine Reihe von Varianten, die für einen Modelltyp spezifisch sind.
Verwenden Sie für drei Ensemblemodelle tree SHAP
Bei baumbasierten Modellen ermöglicht die dynamische Programmierung eine schnelle und exakte Berechnung der Shapley-Werte
Verwenden Sie für neuronale Netzwerke und differenzierbare Modelle integrierte Gradienten und Leitfähigkeit
Integrierte Gradienten bieten eine einfache Möglichkeit, Merkmalsattributionen in neuronalen Netzwerken zu berechnen. Die Leitfähigkeit basiert auf integrierten Gradienten, um Ihnen bei der Interpretation von Attributen von Teilen neuronaler Netzwerke wie Schichten und einzelnen Neuronen zu helfen. (Siehe [3,11], die Implementierung ist unter https://captum.ai/
Verwenden Sie für alle anderen Fälle Kernel SHAP
Sie können Kernel-SHAP verwenden, um Feature-Attributionen für jedes Modell zu berechnen, aber es ist eine Annäherung an die Berechnung der vollständigen Shapley-Werte und bleibt rechenintensiv (siehe [8]). Die für Kernel SHAP benötigten Rechenressourcen wachsen schnell mit der Anzahl der Funktionen. Dies erfordert Näherungsmethoden, die die Genauigkeit, Wiederholbarkeit und Robustheit von Erklärungen verringern können. Amazon SageMaker Clarify bietet praktische Methoden, mit denen vorgefertigte Container für die Berechnung von Kernal-SHAP-Werten in separaten Instanzen bereitgestellt werden. (Ein Beispiel finden Sie im GitHub Repository Fairness and Explaability with SageMaker Clarify
Für Einzelbaummodelle bieten die geteilten Variablen und Blattwerte ein sofort erklärbares Modell, und die zuvor erörterten Methoden bieten keine zusätzlichen Erkenntnisse. In ähnlicher Weise liefern die Koeffizienten für lineare Modelle eine klare Erklärung des Modellverhaltens. (SHAP- und integrierte Gradientenmethoden geben beide Beiträge zurück, die durch die Koeffizienten bestimmt werden.)
Sowohl SHAP als auch integrierte gradientenbasierte Methoden weisen Schwächen auf. SHAP erfordert, dass Attribute aus einem gewichteten Durchschnitt aller Merkmalskombinationen abgeleitet werden. Auf diese Weise erhaltene Attribute können bei der Schätzung der Merkmalsbedeutung irreführend sein, wenn eine starke Wechselwirkung zwischen Merkmalen besteht. Methoden, die auf integrierten Gradienten basieren, können aufgrund der großen Anzahl von Dimensionen, die in großen neuronalen Netzwerken vorhanden sind, schwierig zu interpretieren sein, und diese Methoden reagieren empfindlich auf die Wahl eines Basispunkts. Allgemeiner gesagt können Modelle Merkmale auf unerwartete Weise verwenden, um ein bestimmtes Leistungsniveau zu erreichen. Diese können je nach Modell variieren. Die Bedeutung der Merkmale hängt immer vom Modell ab.
Empfohlene Visualisierungen
Die folgende Tabelle enthält mehrere empfohlene Methoden zur Veranschaulichung der lokalen Interpretationen, die in den vorherigen Abschnitten erörtert wurden. Für tabellarische Daten empfehlen wir ein einfaches Balkendiagramm, das die Attribute zeigt, damit sie leicht verglichen und verwendet werden können, um abzuleiten, wie das Modell Vorhersagen trifft.
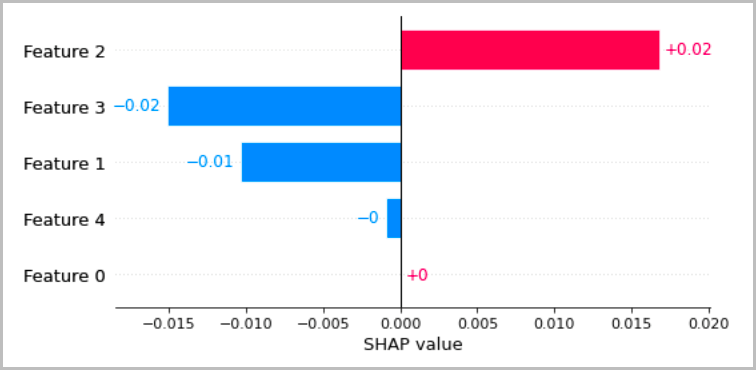
Bei Textdaten führt das Einbetten von Tokens zu einer großen Anzahl von skalaren Eingaben. Die in den vorherigen Abschnitten empfohlenen Methoden erzeugen eine Zuordnung für jede Dimension der Einbettung und für jede Ausgabe. Um diese Informationen in einer Visualisierung zusammenzufassen, können die Attribute für ein bestimmtes Token zusammengefasst werden. Das folgende Beispiel zeigt die Summe der Attribute für das BERT-basierte Modell zur Beantwortung von Fragen, das auf dem SQUAD-Datensatz trainiert wurde. In diesem Fall ist die vorhergesagte und wahre Bezeichnung das Zeichen für das Wort „Frankreich“.

Andernfalls kann die Vektornorm der Token-Attributionen als Gesamtattributionswert zugewiesen werden, wie im folgenden Beispiel gezeigt.

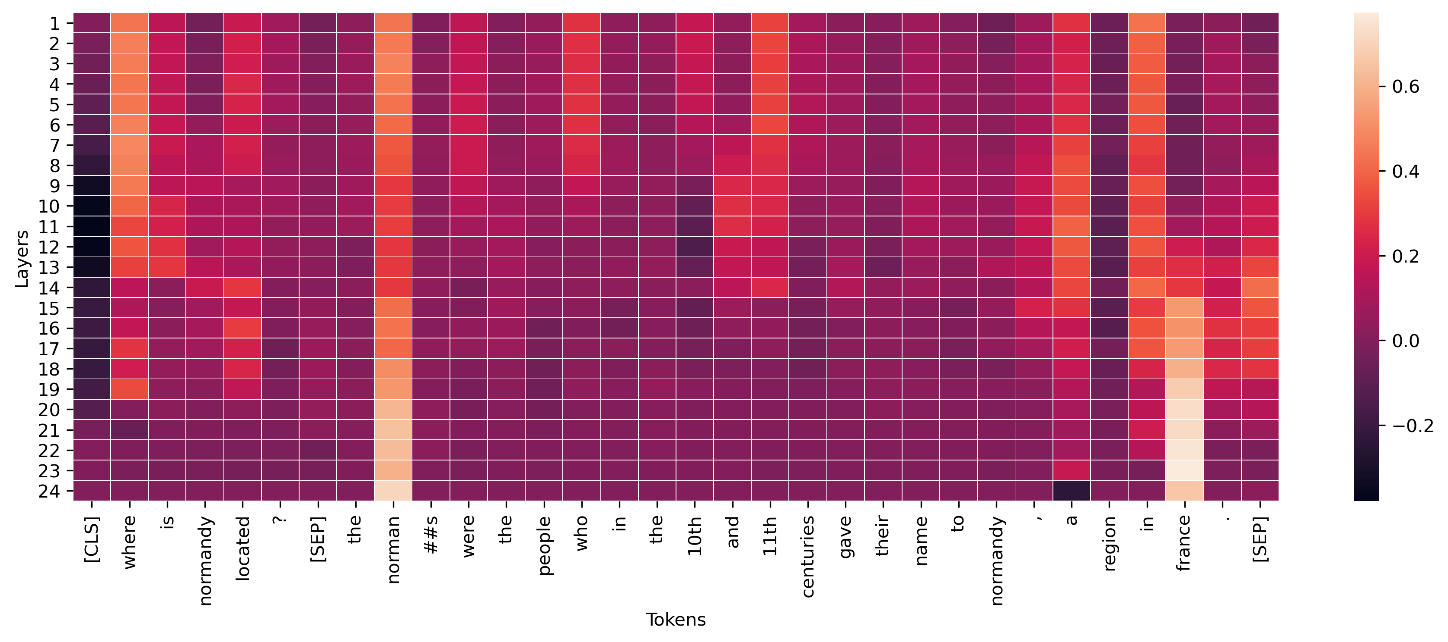
Für Zwischenschichten in Deep-Learning-Modellen können ähnliche Aggregationen auf Leitwerte zur Visualisierung angewendet werden, wie im folgenden Beispiel gezeigt. Diese Vektornorm der Token-Leitfähigkeit für Transformatorschichten zeigt die eventuelle Aktivierung für die End-Token-Vorhersage („Frankreich“).
Konzeptaktivierungsvektoren bieten eine Methode, um tiefe neuronale Netzwerke genauer zu untersuchen [6]. Diese Methode extrahiert Merkmale aus einer Schicht in einem bereits trainierten Netzwerk und trainiert einen linearen Klassifikator anhand dieser Merkmale, um Rückschlüsse auf die Informationen in der Schicht zu ziehen. Beispielsweise möchten Sie möglicherweise ermitteln, welche Ebene eines BERT-basierten Sprachmodells die meisten Informationen über die Sprachteile enthält. In diesem Fall könnten Sie für jede Layer-Ausgabe ein lineares part-of-speech Modell trainieren und eine grobe Schätzung vornehmen, dass der Klassifikator mit der besten Leistung dem Layer zugeordnet ist, der die meisten part-of-speech Informationen enthält. Obwohl wir dies nicht als primäre Methode zur Interpretation neuronaler Netze empfehlen, kann es eine Option für detailliertere Studien und Unterstützung bei der Gestaltung der Netzwerkarchitektur sein.
